Aperçu du Modèle YOLO
Glissez pour afficher le menu
L’algorithme YOLO (You Only Look Once) est un modèle de détection d’objets rapide et efficace. Contrairement aux approches traditionnelles telles que R-CNN qui utilisent plusieurs étapes, YOLO traite l’image entière en un seul passage, ce qui le rend idéal pour les applications en temps réel.
Différences entre YOLO et les approches R-CNN
Les méthodes traditionnelles de détection d’objets, telles que R-CNN et ses variantes, reposent sur un pipeline en deux étapes : d’abord la génération de propositions de régions, puis la classification de chaque région proposée. Bien que cette approche soit efficace, elle est coûteuse en calcul et ralentit l’inférence, la rendant moins adaptée aux applications en temps réel.
YOLO (You Only Look Once) adopte une approche radicalement différente. Il divise l’image d’entrée en une grille et prédit les boîtes englobantes et les probabilités de classe pour chaque cellule en un seul passage avant. Cette conception considère la détection d’objets comme un problème de régression unique, permettant à YOLO d’atteindre des performances en temps réel.
Contrairement aux méthodes basées sur R-CNN qui se concentrent uniquement sur des régions locales, YOLO traite l’image entière en une seule fois, ce qui lui permet de capturer des informations contextuelles globales. Cela conduit à de meilleures performances pour la détection d’objets multiples ou chevauchants, tout en maintenant une grande rapidité et précision.
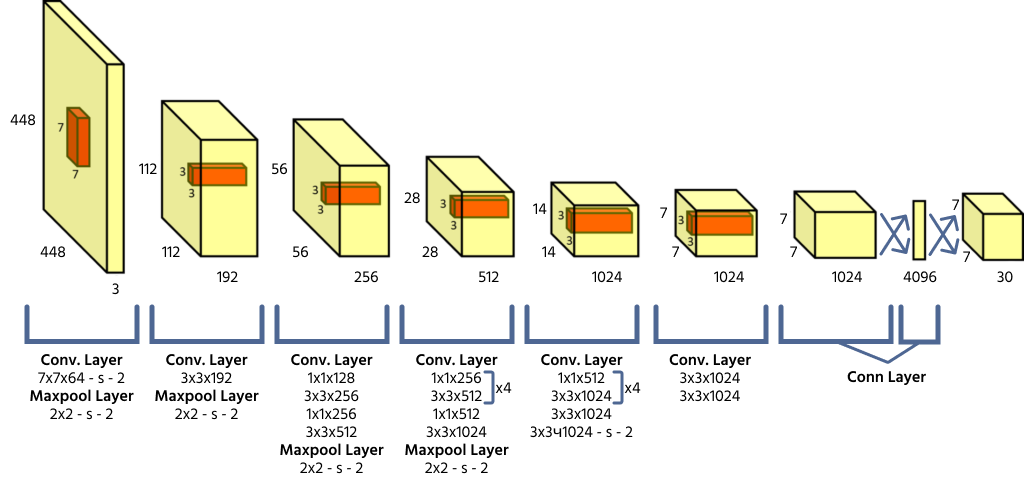
Architecture de YOLO et prédictions basées sur une grille
YOLO divise une image d’entrée en une grille S × S, où chaque cellule de la grille est responsable de détecter les objets dont le centre se trouve à l’intérieur. Chaque cellule prévoit les coordonnées de la boîte englobante (x, y, largeur, hauteur), un score de confiance d’objet et les probabilités de classe. Puisque YOLO traite l’image entière en un seul passage avant, il est très efficace comparé aux modèles de détection d’objets antérieurs.
Fonction de perte et scores de confiance des classes
YOLO optimise la précision de la détection à l'aide d'une fonction de perte personnalisée, qui comprend :
- Perte de localisation : mesure la précision des boîtes englobantes ;
- Perte de confiance : garantit que les prédictions indiquent correctement la présence d'un objet ;
- Perte de classification : évalue la correspondance entre la classe prédite et la classe réelle.
Pour améliorer les résultats, YOLO applique des boîtes d'ancrage et la suppression non maximale (NMS) afin d'éliminer les détections redondantes.
Avantages de YOLO : compromis entre vitesse et précision
Le principal avantage de YOLO est la vitesse. Comme la détection s'effectue en un seul passage, YOLO est beaucoup plus rapide que les méthodes basées sur R-CNN, ce qui le rend adapté aux applications en temps réel telles que la conduite autonome et la surveillance. Cependant, les premières versions de YOLO avaient des difficultés à détecter les petits objets, ce qui a été amélioré dans les versions ultérieures.
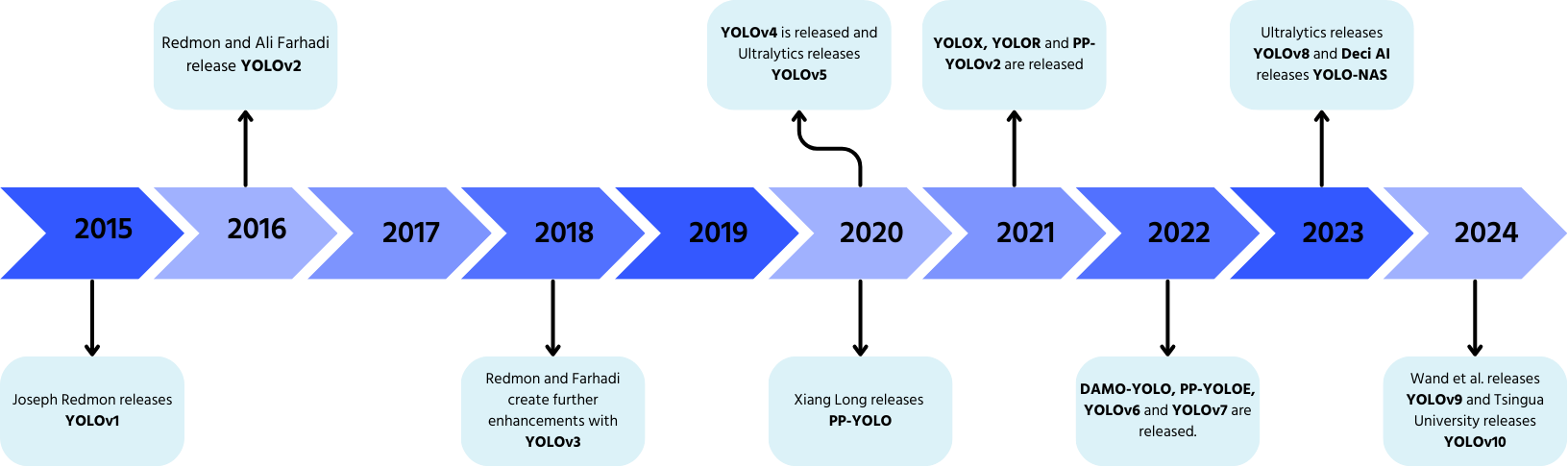
YOLO : Un bref historique
YOLO, développé par Joseph Redmon et Ali Farhadi en 2015, a révolutionné la détection d'objets grâce à son traitement en un seul passage.
- YOLOv2 (2016) : ajout de la normalisation par lot, des boîtes d'ancrage et des clusters de dimensions ;
- YOLOv3 (2018) : introduction d'une colonne vertébrale plus efficace, de multiples ancres et du regroupement spatial pyramidal ;
- YOLOv4 (2020) : ajout de l'augmentation de données Mosaic, d'une tête de détection sans ancre et d'une nouvelle fonction de perte ;
- YOLOv5 : amélioration des performances grâce à l'optimisation des hyperparamètres, au suivi des expériences et aux fonctionnalités d'exportation automatique ;
- YOLOv6 (2022) : open source par Meituan et utilisé dans des robots de livraison autonomes ;
- YOLOv7 : extension des capacités pour inclure l'estimation de pose ;
- YOLOv8 (2023) : amélioration de la vitesse, de la flexibilité et de l'efficacité pour les tâches d'IA visuelle ;
- YOLOv9 : introduction de l'Information de Gradient Programmable (PGI) et du Generalized Efficient Layer Aggregation Network (GELAN) ;
- YOLOv10 : développé par l'Université Tsinghua, éliminant la Suppression Non Maximale (NMS) avec une tête de détection de bout en bout ;
- YOLOv11 : le modèle le plus récent offrant des performances de pointe en détection d'objets, segmentation et classification.
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
