Prédictions de Boîtes Englobantes
Glissez pour afficher le menu
Les boîtes englobantes sont essentielles pour la détection d'objets, fournissant un moyen de marquer l'emplacement des objets. Les modèles de détection d'objets utilisent ces boîtes pour définir la position et les dimensions des objets détectés dans une image. Prédire avec précision les boîtes englobantes est fondamental pour garantir une détection d'objets fiable.
Comment les CNN prédisent les coordonnées des boîtes englobantes
Les réseaux de neurones convolutifs (CNN) traitent les images à travers des couches de convolutions et de sous-échantillonnage afin d'extraire des caractéristiques. Pour la détection d'objets, les CNN génèrent des cartes de caractéristiques qui représentent différentes parties d'une image. La prédiction des boîtes englobantes est généralement réalisée par :
- Extraction des représentations de caractéristiques à partir de l'image ;
- Application d'une fonction de régression pour prédire les coordonnées de la boîte englobante ;
- Classification des objets détectés dans chaque boîte.
Les prédictions des boîtes englobantes sont représentées par des valeurs numériques correspondant à :
- (x, y) : les coordonnées du centre de la boîte ;
- (w, h) : la largeur et la hauteur de la boîte.
Exemple : Prédiction de boîtes englobantes à l'aide d'un modèle pré-entraîné
Au lieu d'entraîner un CNN à partir de zéro, il est possible d'utiliser un modèle pré-entraîné tel que Faster R-CNN du model zoo de TensorFlow pour prédire les boîtes englobantes sur une image. Ci-dessous, un exemple de chargement d'un modèle pré-entraîné, de chargement d'une image, de réalisation de prédictions et de visualisation des boîtes englobantes avec les étiquettes de classe.
Importer les bibliothèques
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Charger le modèle et l'image
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Prétraiter l'image
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Prédiction et extraction des caractéristiques des boîtes englobantes
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Dessiner les boîtes englobantes
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisation
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Résultat :

Prédictions de boîtes englobantes basées sur la régression
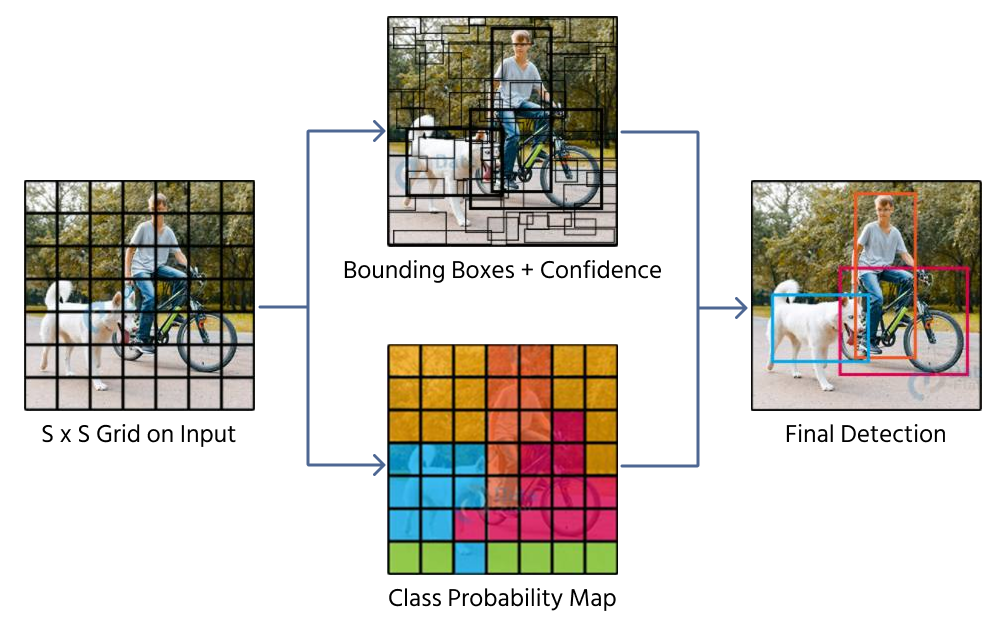
Une méthode pour prédire les boîtes englobantes est la régression directe, où un CNN génère quatre valeurs numériques représentant la position et la taille de la boîte. Des modèles tels que YOLO (You Only Look Once) utilisent cette technique en divisant une image en une grille et en attribuant des prédictions de boîtes englobantes aux cellules de la grille.
Cependant, la régression directe présente des limites :
- Difficulté à gérer des objets de tailles et de rapports d’aspect variés ;
- Gestion inefficace des objets qui se chevauchent ;
- Déplacement imprévisible des boîtes englobantes, entraînant des incohérences.
Approches basées sur les ancres vs. approches sans ancre
Méthodes basées sur les ancres
Les boîtes d'ancrage sont des boîtes englobantes prédéfinies avec des tailles et des rapports d'aspect fixes. Des modèles tels que Faster R-CNN et SSD (Single Shot MultiBox Detector) utilisent des boîtes d'ancrage pour améliorer la précision des prédictions. Le modèle prédit des ajustements aux boîtes d'ancrage plutôt que de prédire les boîtes englobantes à partir de zéro. Cette méthode est efficace pour détecter des objets à différentes échelles, mais elle augmente la complexité computationnelle.
Méthodes sans ancre
Les méthodes sans ancre, telles que CenterNet et FCOS (Fully Convolutional One-Stage Object Detection), éliminent les boîtes d'ancrage prédéfinies et prédisent directement les centres des objets. Ces méthodes offrent :
- Architectures de modèles plus simples ;
- Vitesses d'inférence plus rapides ;
- Meilleure généralisation à des tailles d'objets non vues.

A (Basé sur les ancres) : prédit les décalages (lignes vertes) à partir d’ancres prédéfinies (bleu) pour correspondre à la vérité terrain (rouge). B (Sans ancre) : estime directement les décalages d’un point vers ses frontières.
La prédiction de boîtes englobantes constitue un élément essentiel de la détection d’objets, différentes approches équilibrant précision et efficacité. Les méthodes basées sur les ancres améliorent la précision grâce à l’utilisation de formes prédéfinies, tandis que les méthodes sans ancre simplifient la détection en prédisant directement la localisation des objets. La compréhension de ces techniques permet de concevoir des systèmes de détection d’objets plus performants pour diverses applications réelles.
1. Quelles informations une prédiction de boîte englobante contient-elle généralement ?
2. Quel est l'avantage principal des méthodes basées sur les ancres en détection d'objets ?
3. Quel défi la régression directe rencontre-t-elle dans la prédiction de boîtes englobantes ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
