Détection d'Objets
Glissez pour afficher le menu
La détection d'objets constitue une avancée essentielle au-delà de la classification et de la localisation d’images. Alors que la classification détermine quel objet est présent dans une image, et que la localisation identifie où se trouve un objet unique, la détection d’objets va plus loin en reconnaissant plusieurs objets ainsi que leurs emplacements au sein d’une même image.
Qu’est-ce qui distingue la détection d’objets ?
Contrairement à la classification, qui attribue une seule étiquette à une image entière, la détection d’objets implique à la fois classification et localisation pour plusieurs objets. Un modèle de détection doit prédire des boîtes englobantes autour de chaque objet et les classer correctement. Cela rend la détection d’objets plus complexe et plus exigeante en ressources de calcul que la simple classification.

Approche de la fenêtre glissante et ses limitations
Une méthode traditionnelle pour la détection d'objets est l'approche de la fenêtre glissante, où une fenêtre de taille fixe se déplace sur une image afin de classifier chaque section. Bien que conceptuellement simple, cette méthode présente plusieurs limitations :
- Coût computationnel élevé : nécessite de balayer l'image à plusieurs échelles et positions, ce qui entraîne un temps de traitement important ;
- Tailles de fenêtre rigides : les objets varient en taille et en ratio d'aspect, rendant les fenêtres de taille fixe inefficaces ;
- Calculs redondants : les fenêtres qui se chevauchent traitent à plusieurs reprises des régions similaires de l'image, gaspillant ainsi des ressources.
En raison de ces inefficacités, les méthodes de détection d'objets basées sur l'apprentissage profond ont largement remplacé l'approche de la fenêtre glissante.

Méthodes basées sur les régions : Selective Search et réseaux de propositions de régions (RPN)
Pour améliorer l'efficacité, les méthodes basées sur les régions proposent des régions d'intérêt (RoI) au lieu de balayer l'image entière. Deux techniques majeures sont :
-
Selective search : une approche traditionnelle qui regroupe les pixels similaires en propositions de régions, réduisant ainsi le nombre de prédictions de boîtes englobantes. Bien que plus efficace que les fenêtres glissantes, cette méthode reste lente ;
-
Réseaux de propositions de régions (RPN) : utilisés dans Faster R-CNN, les RPN exploitent un réseau de neurones pour générer directement des régions d'objets potentielles, améliorant significativement la vitesse et la précision par rapport à la selective search.
Premières approches basées sur l'apprentissage profond
L'apprentissage profond a révolutionné la détection d'objets en introduisant les réseaux de neurones convolutifs (CNN) dans les pipelines de détection. Parmi les modèles pionniers, on trouve :
-
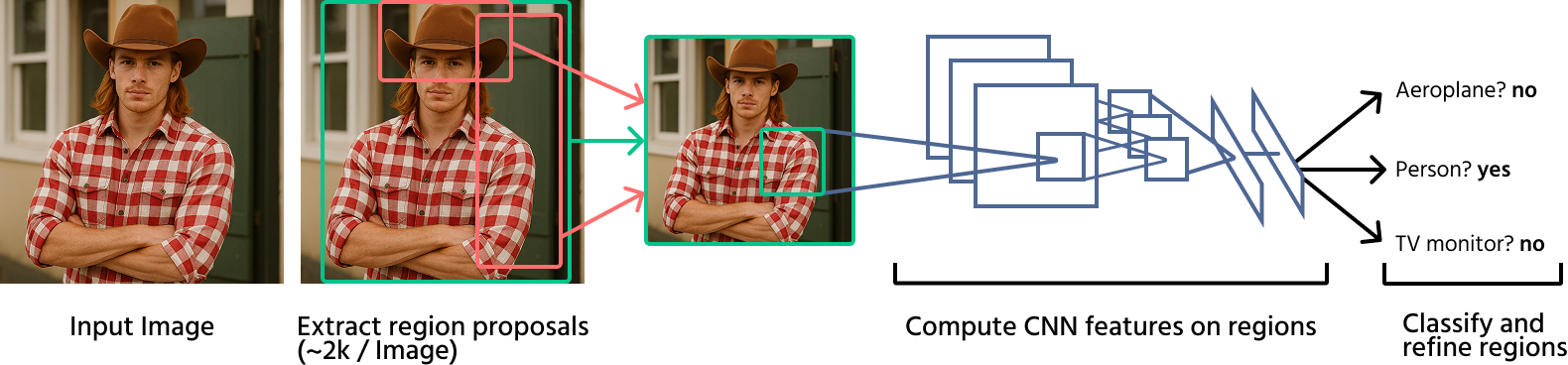
R-CNN (Regions with CNNs) : cette méthode applique un CNN à chaque proposition de région générée par la recherche sélective. Bien que nettement plus précise que les méthodes traditionnelles, elle est lente sur le plan computationnel en raison des évaluations répétées du CNN ;
-
Fast R-CNN : une amélioration du R-CNN, ce modèle traite d'abord l'image entière avec un CNN puis applique un RoI pooling pour extraire les caractéristiques destinées à la classification, accélérant ainsi la détection ;
-
Faster R-CNN : introduit les réseaux de propositions de régions (RPN) pour remplacer la recherche sélective, rendant la détection d'objets plus rapide et plus précise en intégrant la génération de propositions de régions directement dans le réseau de neurones.
La détection d'objets s'appuie sur la classification et la localisation, permettant aux modèles de reconnaître plusieurs objets dans une image. Les méthodes traditionnelles comme les fenêtres glissantes ont été remplacées par des techniques basées sur les régions, plus efficaces, telles que R-CNN et ses successeurs. Faster R-CNN, grâce à l'utilisation de réseaux de propositions de régions, représente une avancée majeure vers une détection d'objets en temps réel et de haute précision. À l'avenir, des techniques plus avancées comme YOLO et SSD permettront d'améliorer encore la rapidité et l'efficacité de la détection.
1. Quel est l'avantage principal de Faster R-CNN par rapport à Fast R-CNN ?
2. Pourquoi l'approche de la fenêtre glissante est-elle inefficace pour la détection d'objets ?
3. Laquelle des méthodes suivantes est une méthode de détection d'objets basée sur l'apprentissage profond ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
Détection d'Objets
La détection d'objets constitue une avancée essentielle au-delà de la classification et de la localisation d’images. Alors que la classification détermine quel objet est présent dans une image, et que la localisation identifie où se trouve un objet unique, la détection d’objets va plus loin en reconnaissant plusieurs objets ainsi que leurs emplacements au sein d’une même image.
Qu’est-ce qui distingue la détection d’objets ?
Contrairement à la classification, qui attribue une seule étiquette à une image entière, la détection d’objets implique à la fois classification et localisation pour plusieurs objets. Un modèle de détection doit prédire des boîtes englobantes autour de chaque objet et les classer correctement. Cela rend la détection d’objets plus complexe et plus exigeante en ressources de calcul que la simple classification.
Approche de la fenêtre glissante et ses limitations
Une méthode traditionnelle pour la détection d'objets est l'approche de la fenêtre glissante, où une fenêtre de taille fixe se déplace sur une image afin de classifier chaque section. Bien que conceptuellement simple, cette méthode présente plusieurs limitations :
- Coût computationnel élevé : nécessite de balayer l'image à plusieurs échelles et positions, ce qui entraîne un temps de traitement important ;
- Tailles de fenêtre rigides : les objets varient en taille et en ratio d'aspect, rendant les fenêtres de taille fixe inefficaces ;
- Calculs redondants : les fenêtres qui se chevauchent traitent à plusieurs reprises des régions similaires de l'image, gaspillant ainsi des ressources.
En raison de ces inefficacités, les méthodes de détection d'objets basées sur l'apprentissage profond ont largement remplacé l'approche de la fenêtre glissante.
Méthodes basées sur les régions : Selective Search et réseaux de propositions de régions (RPN)
Pour améliorer l'efficacité, les méthodes basées sur les régions proposent des régions d'intérêt (RoI) au lieu de balayer l'image entière. Deux techniques majeures sont :
-
Selective search : une approche traditionnelle qui regroupe les pixels similaires en propositions de régions, réduisant ainsi le nombre de prédictions de boîtes englobantes. Bien que plus efficace que les fenêtres glissantes, cette méthode reste lente ;
-
Réseaux de propositions de régions (RPN) : utilisés dans Faster R-CNN, les RPN exploitent un réseau de neurones pour générer directement des régions d'objets potentielles, améliorant significativement la vitesse et la précision par rapport à la selective search.
Premières approches basées sur l'apprentissage profond
L'apprentissage profond a révolutionné la détection d'objets en introduisant les réseaux de neurones convolutifs (CNN) dans les pipelines de détection. Parmi les modèles pionniers, on trouve :
-
R-CNN (Regions with CNNs) : cette méthode applique un CNN à chaque proposition de région générée par la recherche sélective. Bien que nettement plus précise que les méthodes traditionnelles, elle est lente sur le plan computationnel en raison des évaluations répétées du CNN ;
-
Fast R-CNN : une amélioration du R-CNN, ce modèle traite d'abord l'image entière avec un CNN puis applique un RoI pooling pour extraire les caractéristiques destinées à la classification, accélérant ainsi la détection ;
-
Faster R-CNN : introduit les réseaux de propositions de régions (RPN) pour remplacer la recherche sélective, rendant la détection d'objets plus rapide et plus précise en intégrant la génération de propositions de régions directement dans le réseau de neurones.
La détection d'objets s'appuie sur la classification et la localisation, permettant aux modèles de reconnaître plusieurs objets dans une image. Les méthodes traditionnelles comme les fenêtres glissantes ont été remplacées par des techniques basées sur les régions, plus efficaces, telles que R-CNN et ses successeurs. Faster R-CNN, grâce à l'utilisation de réseaux de propositions de régions, représente une avancée majeure vers une détection d'objets en temps réel et de haute précision. À l'avenir, des techniques plus avancées comme YOLO et SSD permettront d'améliorer encore la rapidité et l'efficacité de la détection.
Merci pour vos commentaires !
