Reti Generative Avversarie (GAN)
Scorri per mostrare il menu
Generative Adversarial Networks (GANs) sono una classe di modelli generativi introdotti da Ian Goodfellow nel 2014. Sono composti da due reti neurali — il Generatore e il Discriminatore — addestrate simultaneamente in un contesto di teoria dei giochi. Il generatore cerca di produrre dati che assomigliano ai dati reali, mentre il discriminatore cerca di distinguere i dati reali da quelli generati.
I GAN apprendono a generare campioni di dati a partire dal rumore risolvendo un gioco minimax. Durante l'addestramento, il generatore diventa sempre più abile nel produrre dati realistici e il discriminatore migliora nel distinguere i dati reali da quelli falsi.
Architettura di una GAN
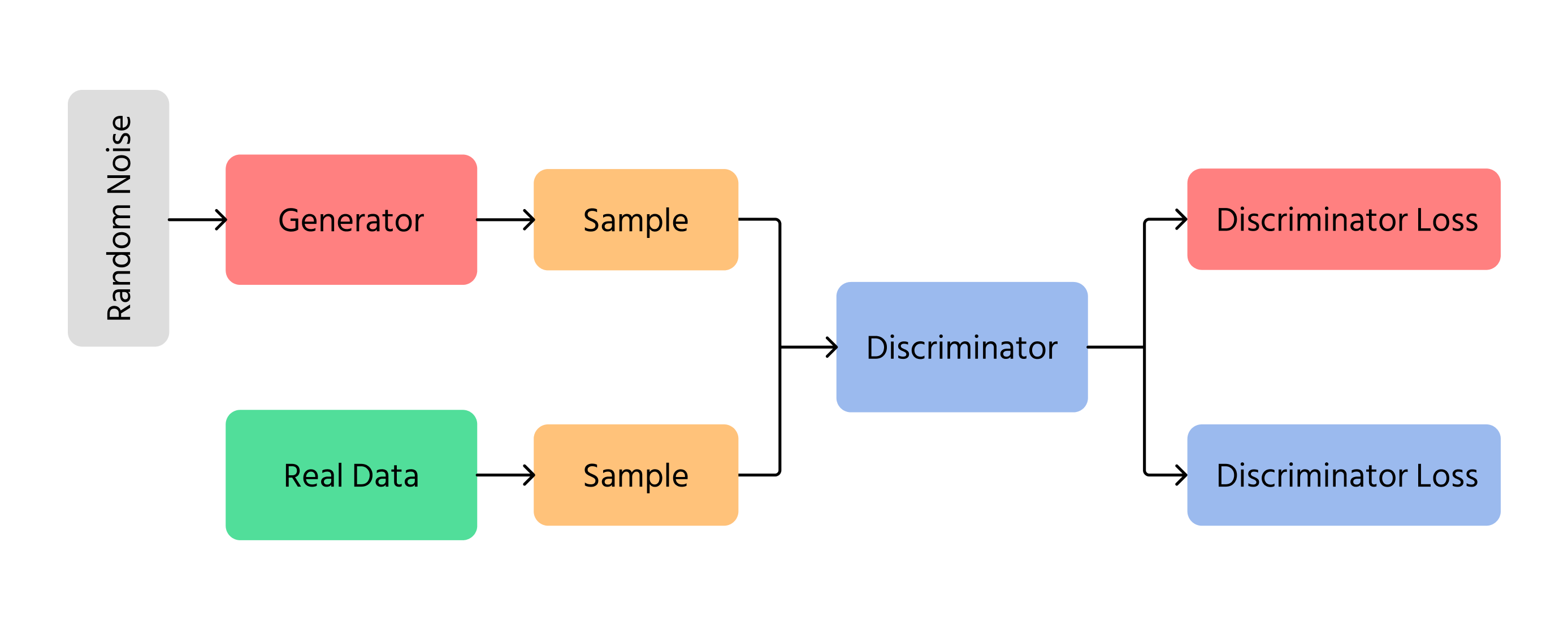
Un modello GAN di base è composto da due componenti principali:
1. Generatore (G)
- Riceve in input un vettore di rumore casuale z∼pz(z);
- Lo trasforma tramite una rete neurale in un campione di dati G(z) progettato per assomigliare ai dati della distribuzione reale.
2. Discriminatore (D)
- Riceve in input un campione di dati reali x∼px(x) oppure un campione generato G(z);
- Restituisce uno scalare compreso tra 0 e 1, che stima la probabilità che l'input sia reale.
Queste due componenti vengono addestrate simultaneamente. Il generatore mira a produrre campioni realistici per ingannare il discriminatore, mentre il discriminatore mira a identificare correttamente i campioni reali rispetto a quelli generati.
Gioco Minimax dei GAN
Al centro dei GAN si trova il gioco minimax, un concetto derivato dalla teoria dei giochi. In questa configurazione:
- Il generatore G e il discriminatore D sono giocatori in competizione;
- D mira a massimizzare la sua capacità di distinguere dati reali da quelli generati;
- G mira a minimizzare la capacità di D di rilevare i suoi dati falsi.
Questa dinamica definisce un gioco a somma zero, dove il guadagno di un giocatore corrisponde alla perdita dell'altro. L'ottimizzazione è definita come:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Il generatore cerca di ingannare il discriminatore generando campioni G(z) il più possibile simili ai dati reali.
Funzioni di Loss
Sebbene l'obiettivo originale dei GAN definisca un gioco minimax, nella pratica vengono utilizzate funzioni di loss alternative per stabilizzare l'addestramento.
- Loss del Generatore Non Saturante:
Questo aiuta il generatore a ricevere gradienti forti anche quando il discriminatore funziona bene.
- Loss del Discriminatore:
Queste funzioni di loss incoraggiano il generatore a produrre campioni che aumentano l'incertezza del discriminatore e migliorano la convergenza durante l'addestramento.
Principali Varianti delle Architetture GAN
Sono emersi diversi tipi di GAN per affrontare specifiche limitazioni o per migliorare le prestazioni:

GAN Condizionale (cGAN)
I GAN condizionali estendono il framework standard dei GAN introducendo informazioni aggiuntive (solitamente etichette) sia nel generatore che nel discriminatore. Invece di generare dati solo dal rumore casuale, il generatore riceve sia il rumore z che una condizione y (ad esempio, un'etichetta di classe). Anche il discriminatore riceve y per valutare se il campione è realistico sotto quella condizione.
- Casi d'uso: generazione di immagini condizionate dalla classe, traduzione immagine-a-immagine, generazione di immagini da testo.
GAN Convoluzionale Profondo (DCGAN)
I DCGAN sostituiscono i layer completamente connessi nei GAN originali con layer convoluzionali e convoluzionali trasposti, rendendoli più efficaci per la generazione di immagini. Introdotti anche linee guida architetturali come la rimozione dei layer completamente connessi, l'uso della batch normalization e l'impiego di attivazioni ReLU/LeakyReLU.
- Casi d'uso: generazione di immagini foto-realistiche, apprendimento di rappresentazioni visive, apprendimento non supervisionato delle caratteristiche.
CycleGAN I CycleGAN affrontano il problema della traduzione immagine-a-immagine senza coppie abbinate. A differenza di altri modelli che richiedono dataset accoppiati (ad esempio, la stessa foto in due stili diversi), i CycleGAN possono apprendere le mappature tra due domini senza esempi accoppiati. Introdotti due generatori e due discriminatori, ciascuno responsabile della mappatura in una direzione (ad esempio, da foto a dipinti e viceversa), viene applicata una perdita di ciclo-consistenza per garantire che la traduzione da un dominio e ritorno restituisca l'immagine originale. Questa perdita è fondamentale per preservare contenuto e struttura.
La perdita di ciclo-consistenza garantisce:
GBA(GAB(x))≈x e GAB(GBA(y))≈ydove:
- GAB mappa immagini dal dominio A al dominio B;
- GBA mappa dal dominio B al dominio A.
- x∈A,y∈B.
Casi d'uso: conversione da foto ad opera d'arte, traduzione da cavallo a zebra, conversione vocale tra parlanti.
StyleGAN
StyleGAN, sviluppato da NVIDIA, introduce un controllo basato sullo stile all'interno del generatore. Invece di fornire direttamente un vettore di rumore al generatore, questo passa attraverso una rete di mappatura per produrre "style vector" che influenzano ogni livello del generatore. Questo consente un controllo preciso su caratteristiche visive come colore dei capelli, espressioni facciali o illuminazione.
Innovazioni rilevanti:
- Style mixing, permette di combinare più codici latenti;
- Adaptive Instance Normalization (AdaIN), controlla le mappe di caratteristiche nel generatore;
- Crescita progressiva, l'addestramento inizia a bassa risoluzione e aumenta nel tempo.
Casi d'uso: generazione di immagini ad altissima risoluzione (ad esempio, volti), controllo di attributi visivi, generazione artistica.
Confronto: GAN vs VAE
I GAN sono una potente classe di modelli generativi in grado di produrre dati altamente realistici attraverso un processo di addestramento avversario. Il loro nucleo risiede in un gioco minimax tra due reti, utilizzando perdite avversarie per migliorare iterativamente entrambi i componenti. Una solida comprensione della loro architettura, delle funzioni di perdita—incluse varianti come cGAN, DCGAN, CycleGAN e StyleGAN—e del loro confronto con altri modelli come i VAE fornisce ai professionisti le basi necessarie per applicazioni in campi come generazione di immagini, sintesi video, data augmentation e altro ancora.
1. Quale delle seguenti opzioni descrive meglio i componenti di un'architettura GAN di base?
2. Qual è l'obiettivo del gioco minimax nei GAN?
3. Quale delle seguenti affermazioni è vera riguardo alla differenza tra GAN e VAE?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Reti Generative Avversarie (GAN)
Generative Adversarial Networks (GANs) sono una classe di modelli generativi introdotti da Ian Goodfellow nel 2014. Sono composti da due reti neurali — il Generatore e il Discriminatore — addestrate simultaneamente in un contesto di teoria dei giochi. Il generatore cerca di produrre dati che assomigliano ai dati reali, mentre il discriminatore cerca di distinguere i dati reali da quelli generati.
I GAN apprendono a generare campioni di dati a partire dal rumore risolvendo un gioco minimax. Durante l'addestramento, il generatore diventa sempre più abile nel produrre dati realistici e il discriminatore migliora nel distinguere i dati reali da quelli falsi.
Architettura di una GAN
Un modello GAN di base è composto da due componenti principali:
1. Generatore (G)
- Riceve in input un vettore di rumore casuale z∼pz(z);
- Lo trasforma tramite una rete neurale in un campione di dati G(z) progettato per assomigliare ai dati della distribuzione reale.
2. Discriminatore (D)
- Riceve in input un campione di dati reali x∼px(x) oppure un campione generato G(z);
- Restituisce uno scalare compreso tra 0 e 1, che stima la probabilità che l'input sia reale.
Queste due componenti vengono addestrate simultaneamente. Il generatore mira a produrre campioni realistici per ingannare il discriminatore, mentre il discriminatore mira a identificare correttamente i campioni reali rispetto a quelli generati.
Gioco Minimax dei GAN
Al centro dei GAN si trova il gioco minimax, un concetto derivato dalla teoria dei giochi. In questa configurazione:
- Il generatore G e il discriminatore D sono giocatori in competizione;
- D mira a massimizzare la sua capacità di distinguere dati reali da quelli generati;
- G mira a minimizzare la capacità di D di rilevare i suoi dati falsi.
Questa dinamica definisce un gioco a somma zero, dove il guadagno di un giocatore corrisponde alla perdita dell'altro. L'ottimizzazione è definita come:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Il generatore cerca di ingannare il discriminatore generando campioni G(z) il più possibile simili ai dati reali.
Funzioni di Loss
Sebbene l'obiettivo originale dei GAN definisca un gioco minimax, nella pratica vengono utilizzate funzioni di loss alternative per stabilizzare l'addestramento.
- Loss del Generatore Non Saturante:
Questo aiuta il generatore a ricevere gradienti forti anche quando il discriminatore funziona bene.
- Loss del Discriminatore:
Queste funzioni di loss incoraggiano il generatore a produrre campioni che aumentano l'incertezza del discriminatore e migliorano la convergenza durante l'addestramento.
Principali Varianti delle Architetture GAN
Sono emersi diversi tipi di GAN per affrontare specifiche limitazioni o per migliorare le prestazioni:
GAN Condizionale (cGAN)
I GAN condizionali estendono il framework standard dei GAN introducendo informazioni aggiuntive (solitamente etichette) sia nel generatore che nel discriminatore. Invece di generare dati solo dal rumore casuale, il generatore riceve sia il rumore z che una condizione y (ad esempio, un'etichetta di classe). Anche il discriminatore riceve y per valutare se il campione è realistico sotto quella condizione.
- Casi d'uso: generazione di immagini condizionate dalla classe, traduzione immagine-a-immagine, generazione di immagini da testo.
GAN Convoluzionale Profondo (DCGAN)
I DCGAN sostituiscono i layer completamente connessi nei GAN originali con layer convoluzionali e convoluzionali trasposti, rendendoli più efficaci per la generazione di immagini. Introdotti anche linee guida architetturali come la rimozione dei layer completamente connessi, l'uso della batch normalization e l'impiego di attivazioni ReLU/LeakyReLU.
- Casi d'uso: generazione di immagini foto-realistiche, apprendimento di rappresentazioni visive, apprendimento non supervisionato delle caratteristiche.
CycleGAN I CycleGAN affrontano il problema della traduzione immagine-a-immagine senza coppie abbinate. A differenza di altri modelli che richiedono dataset accoppiati (ad esempio, la stessa foto in due stili diversi), i CycleGAN possono apprendere le mappature tra due domini senza esempi accoppiati. Introdotti due generatori e due discriminatori, ciascuno responsabile della mappatura in una direzione (ad esempio, da foto a dipinti e viceversa), viene applicata una perdita di ciclo-consistenza per garantire che la traduzione da un dominio e ritorno restituisca l'immagine originale. Questa perdita è fondamentale per preservare contenuto e struttura.
La perdita di ciclo-consistenza garantisce:
GBA(GAB(x))≈x e GAB(GBA(y))≈ydove:
- GAB mappa immagini dal dominio A al dominio B;
- GBA mappa dal dominio B al dominio A.
- x∈A,y∈B.
Casi d'uso: conversione da foto ad opera d'arte, traduzione da cavallo a zebra, conversione vocale tra parlanti.
StyleGAN
StyleGAN, sviluppato da NVIDIA, introduce un controllo basato sullo stile all'interno del generatore. Invece di fornire direttamente un vettore di rumore al generatore, questo passa attraverso una rete di mappatura per produrre "style vector" che influenzano ogni livello del generatore. Questo consente un controllo preciso su caratteristiche visive come colore dei capelli, espressioni facciali o illuminazione.
Innovazioni rilevanti:
- Style mixing, permette di combinare più codici latenti;
- Adaptive Instance Normalization (AdaIN), controlla le mappe di caratteristiche nel generatore;
- Crescita progressiva, l'addestramento inizia a bassa risoluzione e aumenta nel tempo.
Casi d'uso: generazione di immagini ad altissima risoluzione (ad esempio, volti), controllo di attributi visivi, generazione artistica.
Confronto: GAN vs VAE
I GAN sono una potente classe di modelli generativi in grado di produrre dati altamente realistici attraverso un processo di addestramento avversario. Il loro nucleo risiede in un gioco minimax tra due reti, utilizzando perdite avversarie per migliorare iterativamente entrambi i componenti. Una solida comprensione della loro architettura, delle funzioni di perdita—incluse varianti come cGAN, DCGAN, CycleGAN e StyleGAN—e del loro confronto con altri modelli come i VAE fornisce ai professionisti le basi necessarie per applicazioni in campi come generazione di immagini, sintesi video, data augmentation e altro ancora.
Grazie per i tuoi commenti!
