Modelli di Diffusione e Approcci Generativi Probabilistici
Scorri per mostrare il menu
Comprendere la generazione basata sulla diffusione
I modelli di diffusione sono una potente tipologia di modelli di intelligenza artificiale che generano dati – in particolare immagini – imparando a invertire un processo di aggiunta di rumore casuale. Immagina di osservare una foto nitida che gradualmente diventa sfocata, come il disturbo su uno schermo televisivo. Un modello di diffusione impara a fare l'opposto: prende immagini rumorose e ricostruisce l'immagine originale rimuovendo il rumore passo dopo passo.
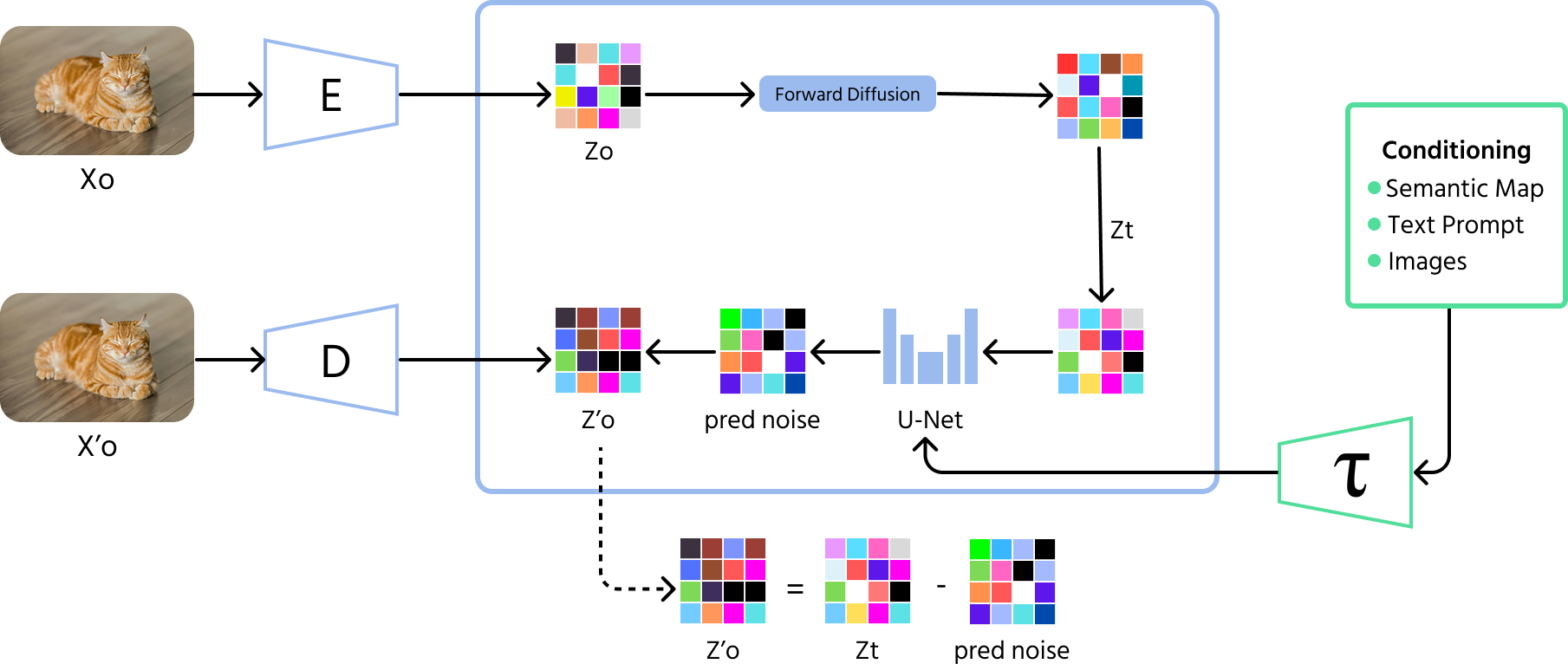
Il processo coinvolge due fasi principali:
- Processo diretto (diffusione): aggiunge gradualmente rumore casuale a un'immagine in molti passaggi, corrompendola fino a ottenere puro rumore;
- Processo inverso (denoising): una rete neurale apprende a rimuovere il rumore passo dopo passo, ricostruendo l'immagine originale dalla versione rumorosa.
I modelli di diffusione sono noti per la loro capacità di produrre immagini di alta qualità e realistiche. Il loro addestramento è tipicamente più stabile rispetto a modelli come i GAN, il che li rende molto interessanti nell'ambito dell'intelligenza artificiale generativa moderna.
Modelli Probabilistici di Diffusione per la Rimozione del Rumore (DDPM)
I modelli probabilistici di diffusione per la rimozione del rumore (DDPM) rappresentano una tipologia diffusa di modelli di diffusione che applicano principi probabilistici e deep learning per rimuovere il rumore dalle immagini in modo graduale, passo dopo passo.
Processo Forward
Nel processo forward, si parte da un'immagine reale x0 e si aggiunge gradualmente rumore gaussiano per T step temporali:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)Dove:
- xt: versione rumorosa dell'input allo step temporale;
- βt: sequenza di piccole varianze che controlla la quantità di rumore aggiunto;
- N: distribuzione gaussiana.
È possibile esprimere anche il rumore totale aggiunto fino allo step come:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)Dove:
- αˉt=∏s=1t(1−βs)
Processo inverso
L'obiettivo del modello è apprendere il processo inverso. Una rete neurale parametrizzata da θ predice la media e la varianza della distribuzione denoised:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))dove:
- xt: immagine rumorosa al passo temporale t;
- xt−1: immagine prevista meno rumorosa al passo t−1;
- μθ: media prevista dalla rete neurale;
- Σθ: varianza prevista dalla rete neurale.
Funzione di perdita
L'addestramento consiste nel minimizzare la differenza tra il rumore reale e il rumore predetto dal modello utilizzando il seguente obiettivo:
Lsimple=Ex0,ϵ,t[∣∣ϵ−ϵ0(αˉtx0+1−αˉtϵ,t)∣∣2]dove:
- xt: immagine di input originale;
- ϵ: rumore gaussiano casuale;
- t: passo temporale durante la diffusione;
- ϵθ: previsione del rumore da parte della rete neurale;
- αˉt: prodotto dei parametri dello schedule del rumore fino al passo t.
Questo aiuta il modello a migliorare la capacità di denoising, aumentando la sua abilità nel generare dati realistici.
Modellazione Generativa Basata su Score
I modelli basati su score rappresentano un'altra classe di modelli di diffusione. Invece di apprendere direttamente il processo inverso del rumore, apprendono la funzione score:
∇xlogp(x)dove:
- ∇xlogp(x): gradiente della densità di log-probabilità rispetto all'input x. Indica la direzione di aumento della probabilità secondo la distribuzione dei dati;
- p(x): distribuzione di probabilità dei dati.
Questa funzione indica al modello in quale direzione l'immagine dovrebbe essere modificata per assomigliare maggiormente ai dati reali. Questi modelli utilizzano quindi un metodo di campionamento come la dinamica di Langevin per spostare gradualmente i dati rumorosi verso regioni di alta probabilità.
I modelli basati su score operano spesso in tempo continuo utilizzando equazioni differenziali stocastiche (SDE). Questo approccio continuo offre flessibilità e può produrre generazioni di alta qualità su diversi tipi di dati.
Applicazioni nella Generazione di Immagini ad Alta Risoluzione
I modelli di diffusione hanno rivoluzionato i compiti generativi, in particolare nella generazione visiva ad alta risoluzione. Applicazioni di rilievo includono:
- Stable Diffusion: modello di diffusione latente che genera immagini da prompt testuali. Combina un modello di denoising basato su U-Net con un autoencoder variazionale (VAE) per operare nello spazio latente;
- DALL·E 2: combina embedding CLIP e decodifica basata su diffusione per generare immagini altamente realistiche e semantiche a partire da testo;
- MidJourney: piattaforma di generazione di immagini basata su diffusione nota per produrre visual di alta qualità e stile artistico da prompt astratti o creativi.
Questi modelli sono utilizzati nella generazione artistica, sintesi fotorealistica, inpainting, super-risoluzione e altro ancora.
Riepilogo
I modelli di diffusione definiscono una nuova era della modellazione generativa trattando la generazione dei dati come un processo stocastico a tempo inverso. Attraverso DDPM e modelli basati su score, raggiungono un addestramento robusto, alta qualità dei campioni e risultati convincenti su diverse modalità. Il loro fondamento nei principi probabilistici e termodinamici li rende sia matematicamente eleganti che praticamente potenti.
1. Qual è l'idea principale alla base dei modelli generativi basati sulla diffusione?
2. Cosa utilizza il processo forward nei DDPM per aggiungere rumore a ogni passo?
3. Quale delle seguenti opzioni descrive meglio il ruolo della funzione score ∇xlogp(x) nella modellazione generativa basata su score?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Modelli di Diffusione e Approcci Generativi Probabilistici
Comprendere la generazione basata sulla diffusione
I modelli di diffusione sono una potente tipologia di modelli di intelligenza artificiale che generano dati – in particolare immagini – imparando a invertire un processo di aggiunta di rumore casuale. Immagina di osservare una foto nitida che gradualmente diventa sfocata, come il disturbo su uno schermo televisivo. Un modello di diffusione impara a fare l'opposto: prende immagini rumorose e ricostruisce l'immagine originale rimuovendo il rumore passo dopo passo.
Il processo coinvolge due fasi principali:
- Processo diretto (diffusione): aggiunge gradualmente rumore casuale a un'immagine in molti passaggi, corrompendola fino a ottenere puro rumore;
- Processo inverso (denoising): una rete neurale apprende a rimuovere il rumore passo dopo passo, ricostruendo l'immagine originale dalla versione rumorosa.
I modelli di diffusione sono noti per la loro capacità di produrre immagini di alta qualità e realistiche. Il loro addestramento è tipicamente più stabile rispetto a modelli come i GAN, il che li rende molto interessanti nell'ambito dell'intelligenza artificiale generativa moderna.
Modelli Probabilistici di Diffusione per la Rimozione del Rumore (DDPM)
I modelli probabilistici di diffusione per la rimozione del rumore (DDPM) rappresentano una tipologia diffusa di modelli di diffusione che applicano principi probabilistici e deep learning per rimuovere il rumore dalle immagini in modo graduale, passo dopo passo.
Processo Forward
Nel processo forward, si parte da un'immagine reale x0 e si aggiunge gradualmente rumore gaussiano per T step temporali:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)Dove:
- xt: versione rumorosa dell'input allo step temporale;
- βt: sequenza di piccole varianze che controlla la quantità di rumore aggiunto;
- N: distribuzione gaussiana.
È possibile esprimere anche il rumore totale aggiunto fino allo step come:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)Dove:
- αˉt=∏s=1t(1−βs)
Processo inverso
L'obiettivo del modello è apprendere il processo inverso. Una rete neurale parametrizzata da θ predice la media e la varianza della distribuzione denoised:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))dove:
- xt: immagine rumorosa al passo temporale t;
- xt−1: immagine prevista meno rumorosa al passo t−1;
- μθ: media prevista dalla rete neurale;
- Σθ: varianza prevista dalla rete neurale.
Funzione di perdita
L'addestramento consiste nel minimizzare la differenza tra il rumore reale e il rumore predetto dal modello utilizzando il seguente obiettivo:
Lsimple=Ex0,ϵ,t[∣∣ϵ−ϵ0(αˉtx0+1−αˉtϵ,t)∣∣2]dove:
- xt: immagine di input originale;
- ϵ: rumore gaussiano casuale;
- t: passo temporale durante la diffusione;
- ϵθ: previsione del rumore da parte della rete neurale;
- αˉt: prodotto dei parametri dello schedule del rumore fino al passo t.
Questo aiuta il modello a migliorare la capacità di denoising, aumentando la sua abilità nel generare dati realistici.
Modellazione Generativa Basata su Score
I modelli basati su score rappresentano un'altra classe di modelli di diffusione. Invece di apprendere direttamente il processo inverso del rumore, apprendono la funzione score:
∇xlogp(x)dove:
- ∇xlogp(x): gradiente della densità di log-probabilità rispetto all'input x. Indica la direzione di aumento della probabilità secondo la distribuzione dei dati;
- p(x): distribuzione di probabilità dei dati.
Questa funzione indica al modello in quale direzione l'immagine dovrebbe essere modificata per assomigliare maggiormente ai dati reali. Questi modelli utilizzano quindi un metodo di campionamento come la dinamica di Langevin per spostare gradualmente i dati rumorosi verso regioni di alta probabilità.
I modelli basati su score operano spesso in tempo continuo utilizzando equazioni differenziali stocastiche (SDE). Questo approccio continuo offre flessibilità e può produrre generazioni di alta qualità su diversi tipi di dati.
Applicazioni nella Generazione di Immagini ad Alta Risoluzione
I modelli di diffusione hanno rivoluzionato i compiti generativi, in particolare nella generazione visiva ad alta risoluzione. Applicazioni di rilievo includono:
- Stable Diffusion: modello di diffusione latente che genera immagini da prompt testuali. Combina un modello di denoising basato su U-Net con un autoencoder variazionale (VAE) per operare nello spazio latente;
- DALL·E 2: combina embedding CLIP e decodifica basata su diffusione per generare immagini altamente realistiche e semantiche a partire da testo;
- MidJourney: piattaforma di generazione di immagini basata su diffusione nota per produrre visual di alta qualità e stile artistico da prompt astratti o creativi.
Questi modelli sono utilizzati nella generazione artistica, sintesi fotorealistica, inpainting, super-risoluzione e altro ancora.
Riepilogo
I modelli di diffusione definiscono una nuova era della modellazione generativa trattando la generazione dei dati come un processo stocastico a tempo inverso. Attraverso DDPM e modelli basati su score, raggiungono un addestramento robusto, alta qualità dei campioni e risultati convincenti su diverse modalità. Il loro fondamento nei principi probabilistici e termodinamici li rende sia matematicamente eleganti che praticamente potenti.
Grazie per i tuoi commenti!
