Panoramica Dei Modelli Cnn Più Popolari
Scorri per mostrare il menu
Le reti neurali convoluzionali (CNN) si sono evolute significativamente, con diverse architetture che hanno migliorato accuratezza, efficienza e scalabilità. Questo capitolo esamina cinque modelli chiave di CNN che hanno influenzato il deep learning: LeNet, AlexNet, VGGNet, ResNet e InceptionNet.
LeNet: La Fondazione delle CNN
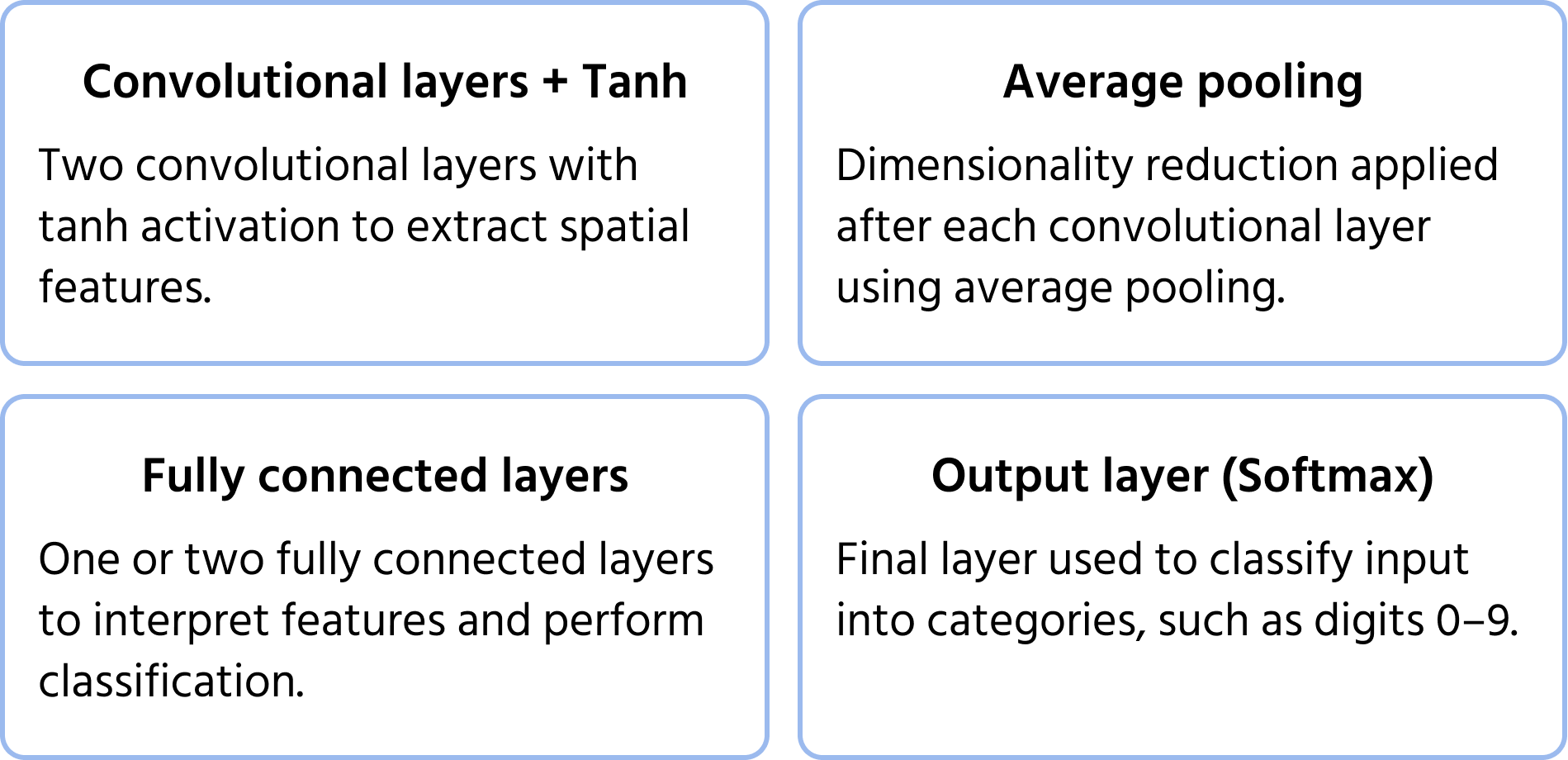
Una delle prime architetture di reti neurali convoluzionali, proposta da Yann LeCun nel 1998 per il riconoscimento di cifre scritte a mano. Ha posto le basi per le moderne CNN introducendo componenti fondamentali come convoluzioni, pooling e strati completamente connessi. Maggiori informazioni sul modello sono disponibili nella documentazione.
Caratteristiche Principali dell'Architettura
AlexNet: Svolta nel Deep Learning
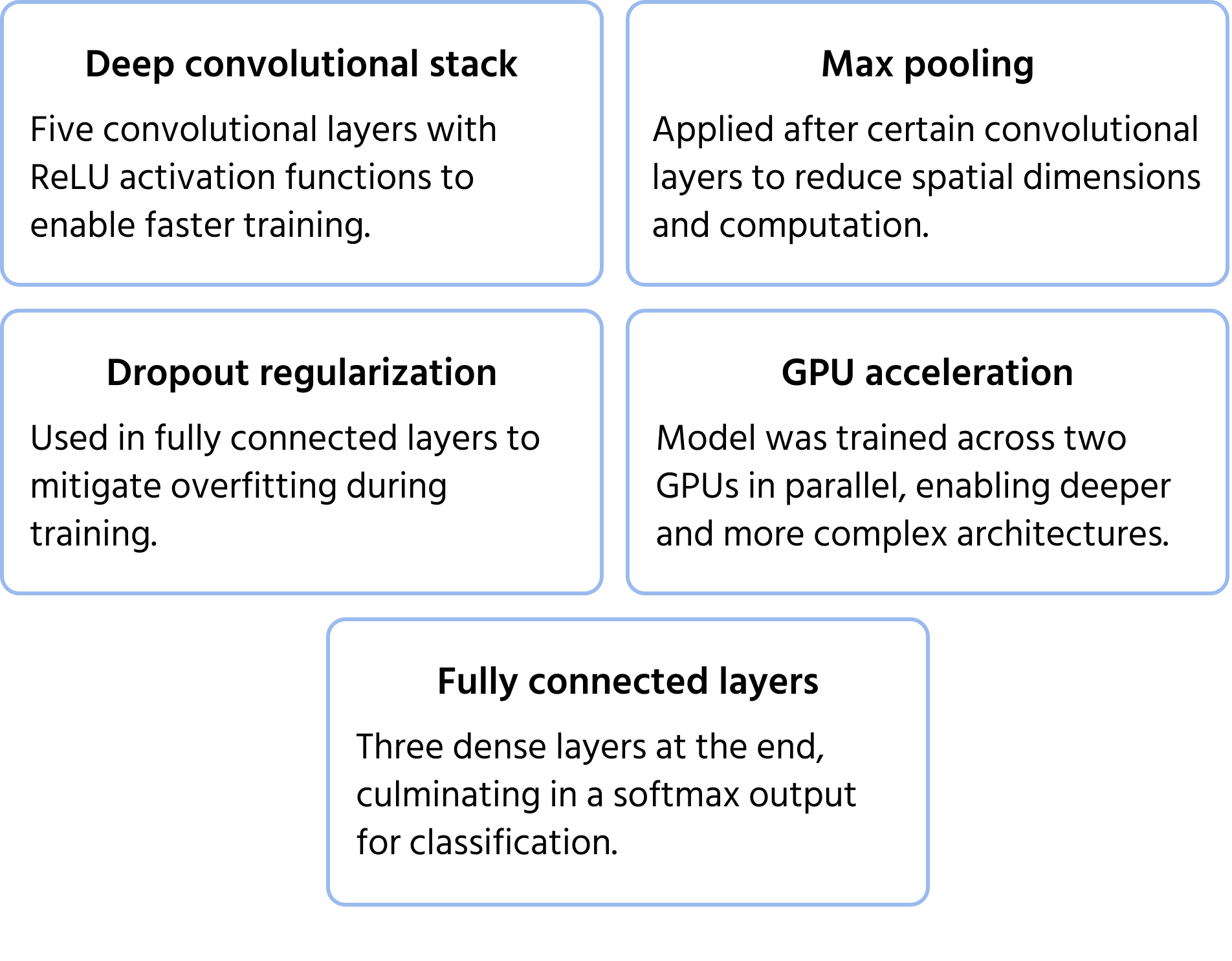
Un'architettura CNN fondamentale che ha vinto la competizione ImageNet del 2012, AlexNet ha dimostrato che le reti neurali profonde a convoluzione possono superare significativamente i metodi tradizionali di machine learning per la classificazione di immagini su larga scala. Ha introdotto innovazioni che sono diventate standard nel deep learning moderno. Puoi approfondire il modello nella documentazione.
Caratteristiche principali dell'architettura
VGGNet: Reti più profonde con filtri uniformi
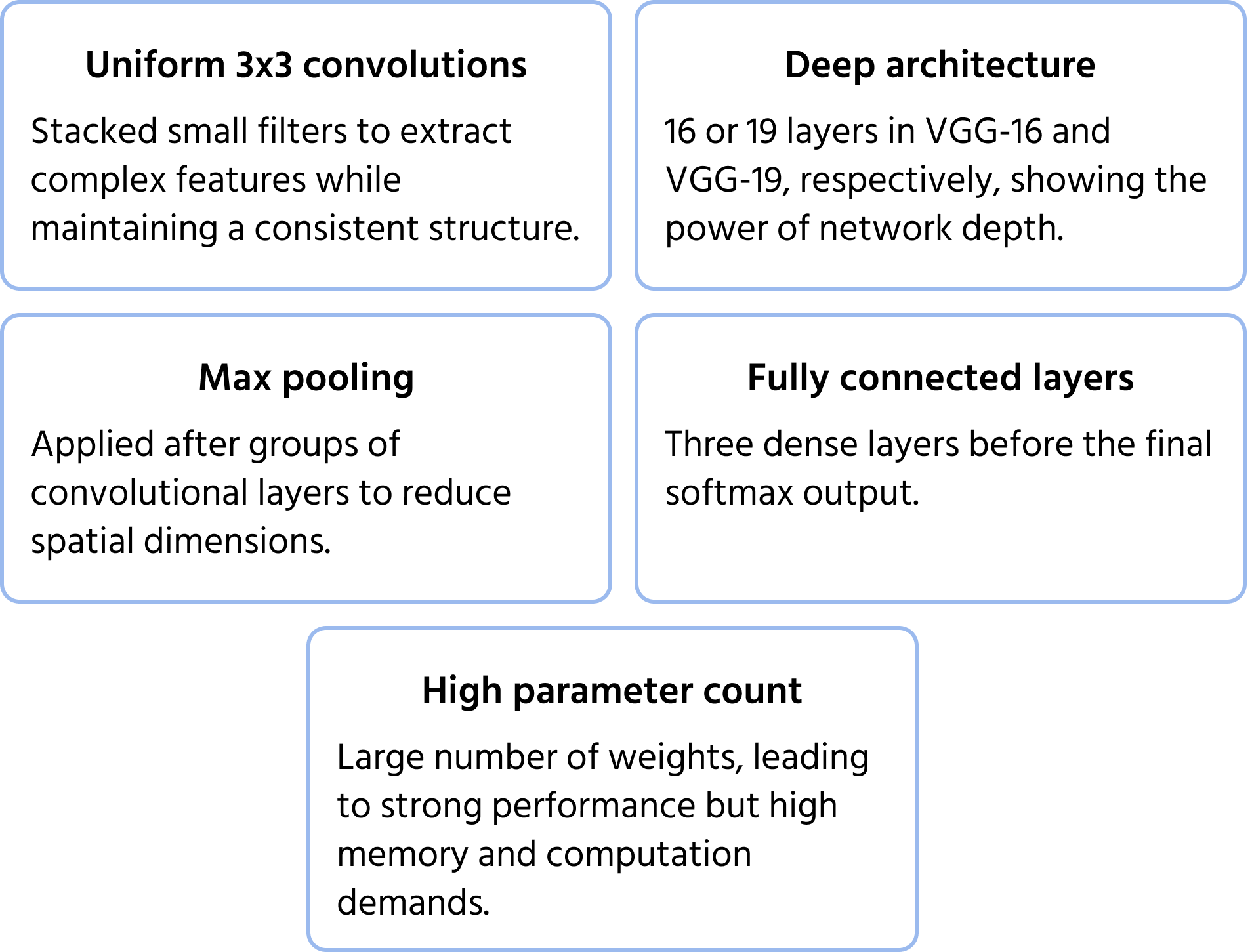
Sviluppata dal Visual Geometry Group di Oxford, VGGNet ha enfatizzato profondità e semplicità utilizzando filtri convoluzionali uniformi 3×3. Ha dimostrato che l'accumulo di piccoli filtri in reti profonde può migliorare significativamente le prestazioni, portando a varianti ampiamente utilizzate come VGG-16 e VGG-19. Puoi approfondire il modello nella documentazione.
Caratteristiche principali dell'architettura
ResNet: Risoluzione del problema della profondità
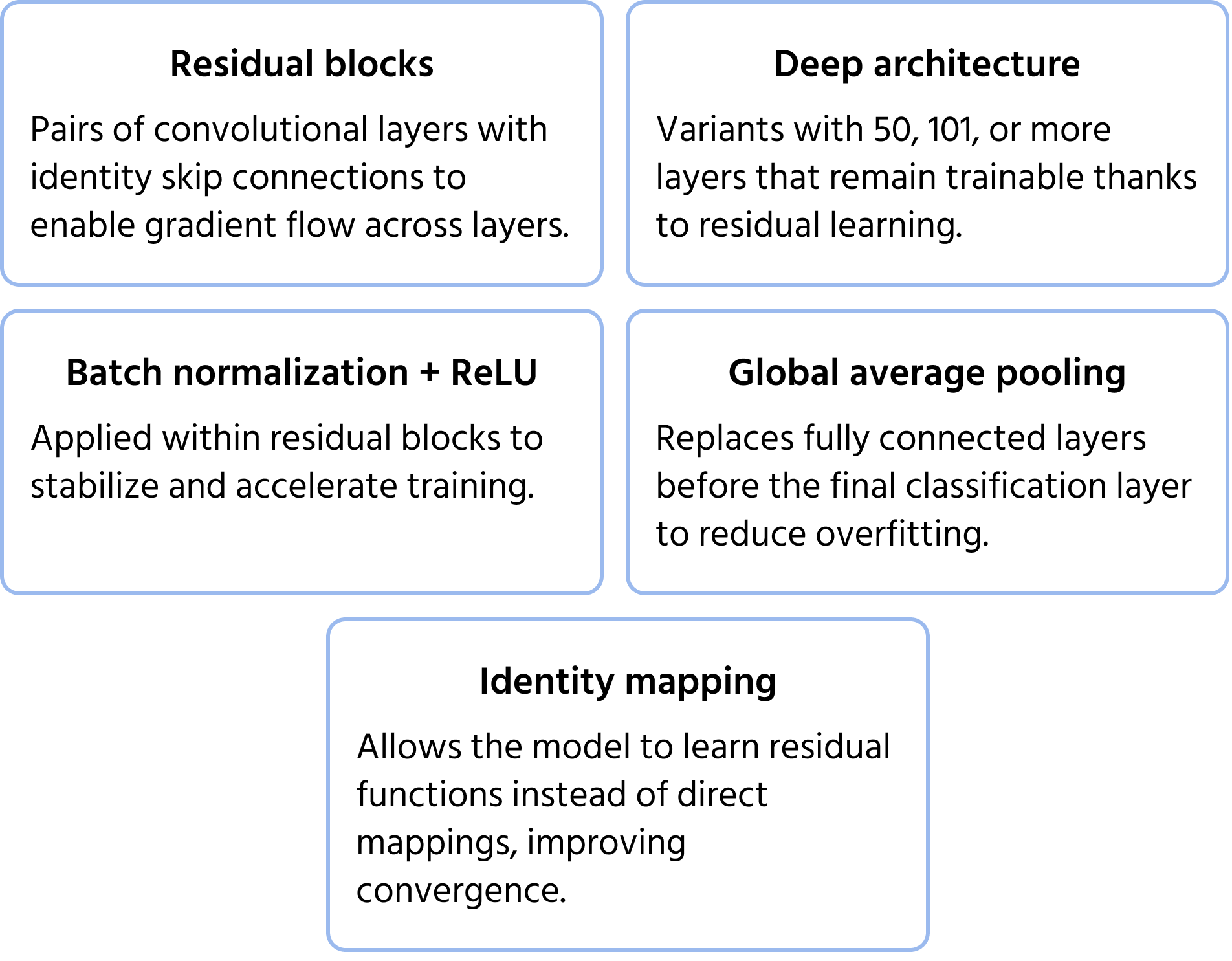
ResNet (Residual Networks), introdotto da Microsoft nel 2015, ha affrontato il problema della scomparsa del gradiente, che si verifica durante l'addestramento di reti molto profonde. Le reti profonde tradizionali incontrano difficoltà in termini di efficienza di addestramento e degrado delle prestazioni, ma ResNet ha superato questo problema grazie alle connessioni di salto (apprendimento residuo). Questi collegamenti permettono alle informazioni di bypassare determinati strati, garantendo che i gradienti continuino a propagarsi in modo efficace. Le architetture ResNet, come ResNet-50 e ResNet-101, hanno reso possibile l'addestramento di reti con centinaia di strati, migliorando significativamente l'accuratezza nella classificazione delle immagini. Puoi approfondire il modello nella documentazione.
Caratteristiche principali dell'architettura
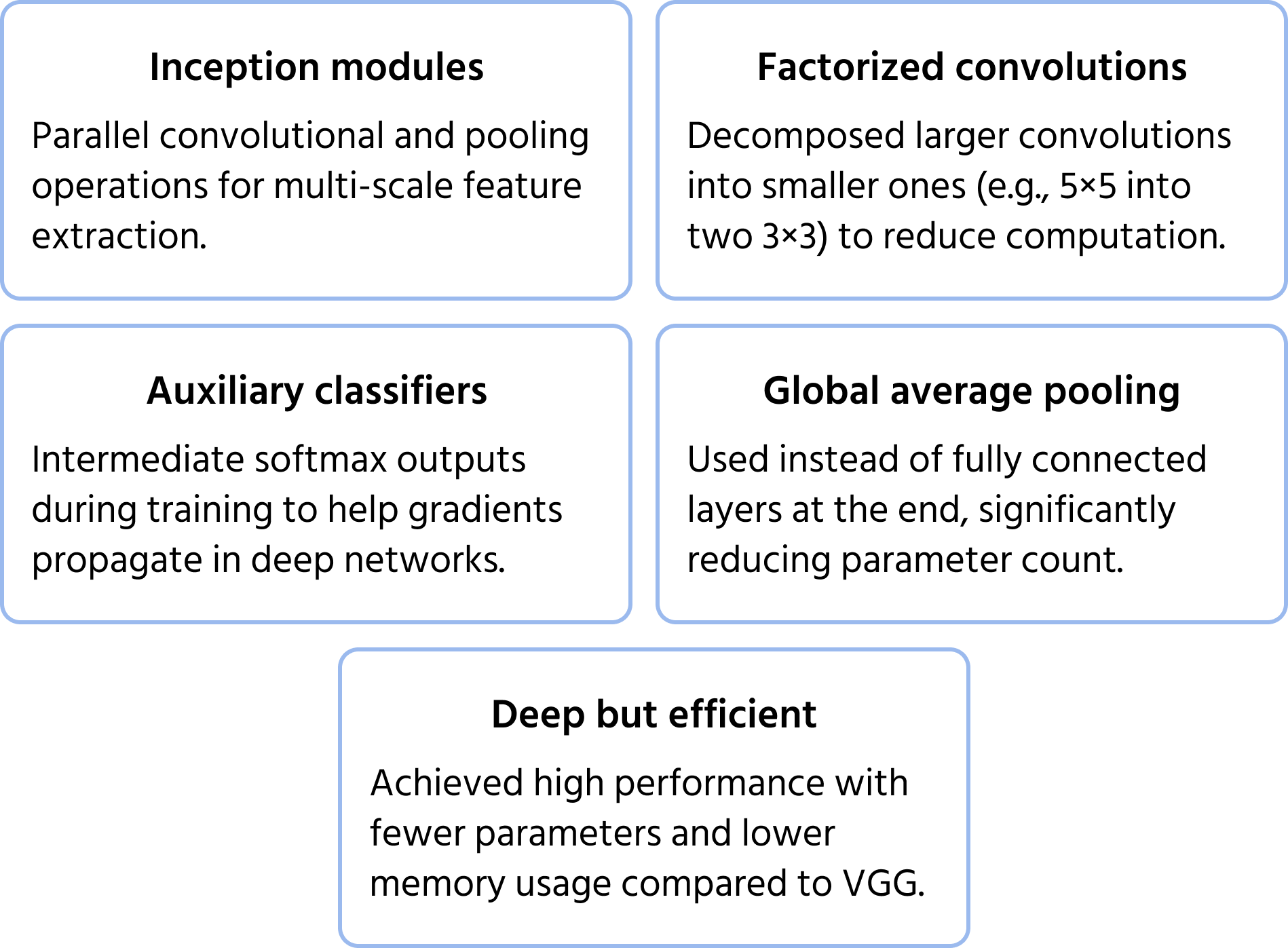
InceptionNet: Estrazione di Caratteristiche Multi-Scala
InceptionNet (conosciuto anche come GoogLeNet) si basa sul modulo inception per creare un'architettura profonda ma efficiente. Invece di impilare i livelli in modo sequenziale, InceptionNet utilizza percorsi paralleli per estrarre caratteristiche a diversi livelli. Ulteriori informazioni sul modello sono disponibili nella documentazione.
Ottimizzazioni principali:
- Convoluzioni fattorizzate per ridurre il costo computazionale;
- Classificatori ausiliari negli strati intermedi per migliorare la stabilità dell'addestramento;
- Global average pooling al posto dei livelli completamente connessi, riducendo il numero di parametri mantenendo le prestazioni.
Questa struttura consente a InceptionNet di essere più profondo rispetto a precedenti CNN come VGG, senza aumentare drasticamente i requisiti computazionali.
Caratteristiche Principali dell'Architettura
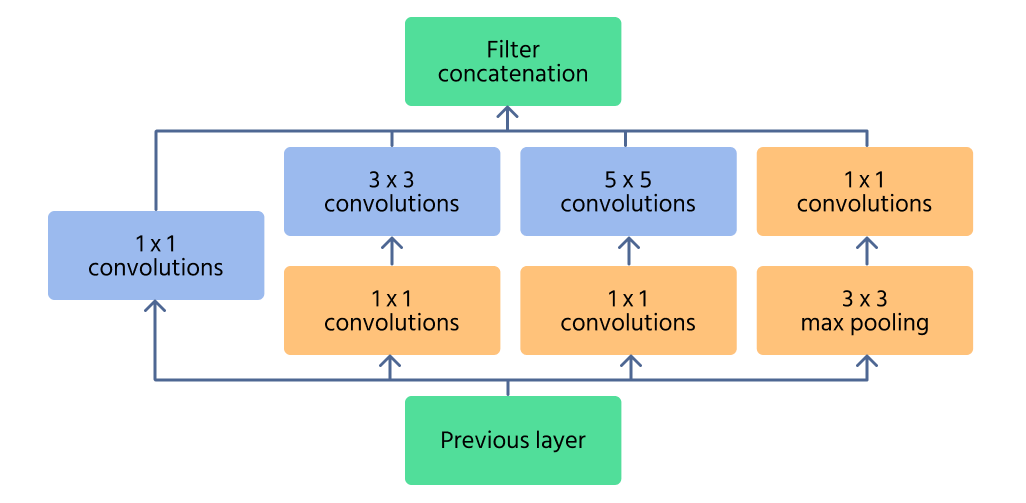
Modulo Inception
Il modulo Inception rappresenta il componente principale di InceptionNet, progettato per catturare in modo efficiente le caratteristiche su più scale. Invece di applicare una singola operazione di convoluzione, il modulo elabora l'input con filtri di diverse dimensioni (1×1, 3×3, 5×5) in parallelo. Questo consente alla rete di riconoscere sia dettagli fini che schemi di grandi dimensioni in un'immagine.
Per ridurre il costo computazionale, vengono utilizzate le 1×1 convolutions prima di applicare filtri più grandi. Queste riducendo il numero di canali in ingresso, rendendo la rete più efficiente. Inoltre, i livelli di max pooling all'interno del modulo aiutano a mantenere le caratteristiche essenziali controllando al contempo la dimensionalità.
Esempio
Considerare un esempio per comprendere come la riduzione delle dimensioni diminuisce il carico computazionale. Supponiamo di dover convolvere 28 × 28 × 192 input feature maps con 5 × 5 × 32 filters. Questa operazione richiederebbe circa 120,42 milioni di calcoli.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Ripetiamo i calcoli, ma questa volta inseriamo uno strato di convoluzione 1×1 convolutional layer prima di applicare la 5×5 convolution alle stesse mappe di caratteristiche in ingresso.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Ciascuna di queste architetture CNN ha svolto un ruolo fondamentale nell'avanzamento della visione artificiale, influenzando applicazioni in sanità, sistemi autonomi, sicurezza e elaborazione di immagini in tempo reale. Dai principi fondanti di LeNet all'estrazione di caratteristiche multi-scala di InceptionNet, questi modelli hanno costantemente ampliato i confini del deep learning, aprendo la strada a architetture ancora più avanzate in futuro.
1. Qual è stata l'innovazione principale introdotta da ResNet che ha permesso di addestrare reti estremamente profonde?
2. In che modo InceptionNet migliora l'efficienza computazionale rispetto alle CNN tradizionali?
3. Quale architettura CNN ha introdotto per prima il concetto di utilizzare piccoli filtri di convoluzione 3×3 in tutta la rete?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
