Previsioni del Riquadro di Delimitazione
Scorri per mostrare il menu
I riquadri di delimitazione sono fondamentali per il rilevamento degli oggetti, fornendo un metodo per segnare la posizione degli oggetti. I modelli di rilevamento degli oggetti utilizzano questi riquadri per definire la posizione e le dimensioni degli oggetti rilevati all'interno di un'immagine. Predire con precisione i riquadri di delimitazione è essenziale per garantire un rilevamento affidabile degli oggetti.
Come le CNN predicono le coordinate dei riquadri di delimitazione
Le reti neurali convoluzionali (CNN) elaborano le immagini attraverso strati di convoluzione e pooling per estrarre caratteristiche. Per il rilevamento degli oggetti, le CNN generano mappe di caratteristiche che rappresentano diverse parti di un'immagine. La previsione dei riquadri di delimitazione viene generalmente ottenuta tramite:
- Estrazione delle rappresentazioni delle caratteristiche dall'immagine;
- Applicazione di una funzione di regressione per predire le coordinate del riquadro di delimitazione;
- Classificazione degli oggetti rilevati all'interno di ciascun riquadro.
Le previsioni dei riquadri di delimitazione sono rappresentate come valori numerici corrispondenti a:
- (x, y): le coordinate del centro del riquadro;
- (w, h): la larghezza e l'altezza del riquadro.
Esempio: Predizione dei riquadri di delimitazione utilizzando un modello preaddestrato
Invece di addestrare una CNN da zero, è possibile utilizzare un modello preaddestrato come Faster R-CNN dal model zoo di TensorFlow per predire i riquadri di delimitazione su un'immagine. Di seguito è riportato un esempio di caricamento di un modello preaddestrato, caricamento di un'immagine, esecuzione delle previsioni e visualizzazione dei riquadri di delimitazione con le etichette di classe.
Importa le librerie
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Carica il modello e l'immagine
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Preelabora l'immagine
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Effettuare la previsione ed estrarre le caratteristiche del bounding box
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Disegnare i bounding box
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualizzazione
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Risultato:

Predizioni di Bounding Box Basate sulla Regressione
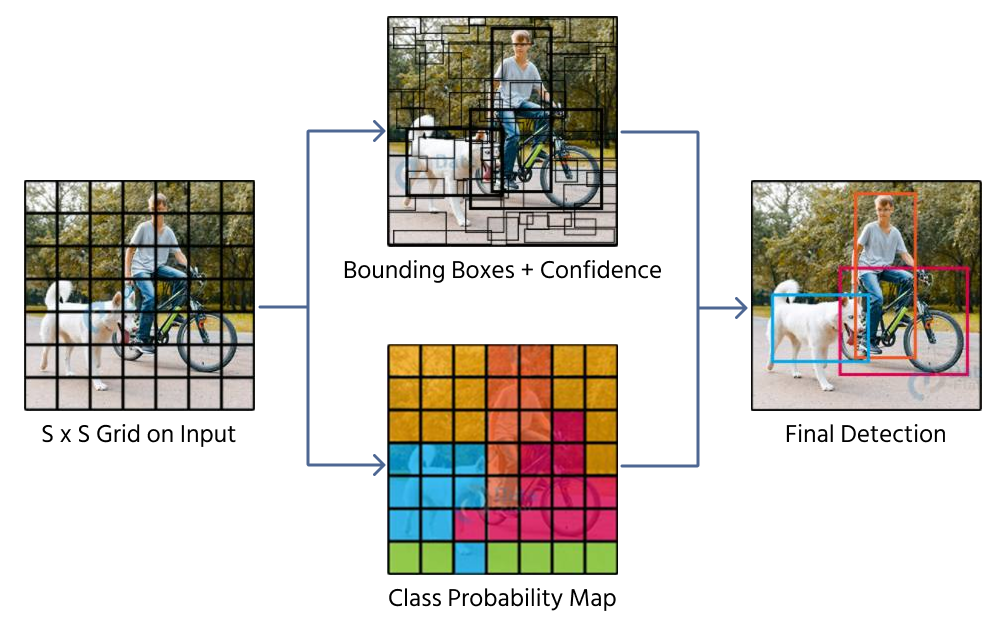
Un approccio per prevedere i bounding box è la regressione diretta, in cui una CNN restituisce quattro valori numerici che rappresentano la posizione e la dimensione del box. Modelli come YOLO (You Only Look Once) utilizzano questa tecnica suddividendo un'immagine in una griglia e assegnando le predizioni dei bounding box alle celle della griglia.
Tuttavia, la regressione diretta presenta delle limitazioni:
- Difficoltà nella gestione di oggetti con dimensioni e proporzioni variabili;
- Gestione inefficace di oggetti sovrapposti;
- Possibili spostamenti imprevedibili dei bounding box, che portano a incoerenze.
Approcci Basati su Anchor vs. Approcci Anchor-Free
Metodi Basati su Anchor
Le anchor box sono riquadri di delimitazione predefiniti con dimensioni e rapporti di aspetto fissi. Modelli come Faster R-CNN e SSD (Single Shot MultiBox Detector) utilizzano le anchor box per migliorare l'accuratezza delle previsioni. Il modello prevede aggiustamenti alle anchor box invece di prevedere i riquadri di delimitazione da zero. Questo metodo è efficace per rilevare oggetti di diverse scale, ma aumenta la complessità computazionale.
Metodi Anchor-Free
I metodi anchor-free, come CenterNet e FCOS (Fully Convolutional One-Stage Object Detection), eliminano le anchor box predefinite e prevedono direttamente i centri degli oggetti. Questi metodi offrono:
- Architetture di modello più semplici;
- Velocità di inferenza più elevate;
- Migliore generalizzazione a dimensioni di oggetti non viste.

A (Basato su anchor): prevede offset (linee verdi) da anchor predefiniti (blu) per corrispondere al ground truth (rosso). B (Senza anchor): stima direttamente gli offset da un punto ai suoi confini.
La predizione del bounding box è una componente fondamentale del rilevamento oggetti e i diversi approcci bilanciano accuratezza ed efficienza. Mentre i metodi basati su anchor migliorano la precisione utilizzando forme predefinite, quelli senza anchor semplificano il rilevamento prevedendo direttamente la posizione degli oggetti. Comprendere queste tecniche aiuta a progettare sistemi di rilevamento oggetti migliori per varie applicazioni reali.
1. Quali informazioni contiene tipicamente una previsione di bounding box?
2. Qual è il principale vantaggio dei metodi basati su anchor nell'object detection?
3. Quale sfida affronta la regressione diretta nella previsione delle bounding box?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Previsioni del Riquadro di Delimitazione
I riquadri di delimitazione sono fondamentali per il rilevamento degli oggetti, fornendo un metodo per segnare la posizione degli oggetti. I modelli di rilevamento degli oggetti utilizzano questi riquadri per definire la posizione e le dimensioni degli oggetti rilevati all'interno di un'immagine. Predire con precisione i riquadri di delimitazione è essenziale per garantire un rilevamento affidabile degli oggetti.
Come le CNN predicono le coordinate dei riquadri di delimitazione
Le reti neurali convoluzionali (CNN) elaborano le immagini attraverso strati di convoluzione e pooling per estrarre caratteristiche. Per il rilevamento degli oggetti, le CNN generano mappe di caratteristiche che rappresentano diverse parti di un'immagine. La previsione dei riquadri di delimitazione viene generalmente ottenuta tramite:
- Estrazione delle rappresentazioni delle caratteristiche dall'immagine;
- Applicazione di una funzione di regressione per predire le coordinate del riquadro di delimitazione;
- Classificazione degli oggetti rilevati all'interno di ciascun riquadro.
Le previsioni dei riquadri di delimitazione sono rappresentate come valori numerici corrispondenti a:
- (x, y): le coordinate del centro del riquadro;
- (w, h): la larghezza e l'altezza del riquadro.
Esempio: Predizione dei riquadri di delimitazione utilizzando un modello preaddestrato
Invece di addestrare una CNN da zero, è possibile utilizzare un modello preaddestrato come Faster R-CNN dal model zoo di TensorFlow per predire i riquadri di delimitazione su un'immagine. Di seguito è riportato un esempio di caricamento di un modello preaddestrato, caricamento di un'immagine, esecuzione delle previsioni e visualizzazione dei riquadri di delimitazione con le etichette di classe.
Importa le librerie
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Carica il modello e l'immagine
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Preelabora l'immagine
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Effettuare la previsione ed estrarre le caratteristiche del bounding box
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Disegnare i bounding box
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualizzazione
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Risultato:
Predizioni di Bounding Box Basate sulla Regressione
Un approccio per prevedere i bounding box è la regressione diretta, in cui una CNN restituisce quattro valori numerici che rappresentano la posizione e la dimensione del box. Modelli come YOLO (You Only Look Once) utilizzano questa tecnica suddividendo un'immagine in una griglia e assegnando le predizioni dei bounding box alle celle della griglia.
Tuttavia, la regressione diretta presenta delle limitazioni:
- Difficoltà nella gestione di oggetti con dimensioni e proporzioni variabili;
- Gestione inefficace di oggetti sovrapposti;
- Possibili spostamenti imprevedibili dei bounding box, che portano a incoerenze.
Approcci Basati su Anchor vs. Approcci Anchor-Free
Metodi Basati su Anchor
Le anchor box sono riquadri di delimitazione predefiniti con dimensioni e rapporti di aspetto fissi. Modelli come Faster R-CNN e SSD (Single Shot MultiBox Detector) utilizzano le anchor box per migliorare l'accuratezza delle previsioni. Il modello prevede aggiustamenti alle anchor box invece di prevedere i riquadri di delimitazione da zero. Questo metodo è efficace per rilevare oggetti di diverse scale, ma aumenta la complessità computazionale.
Metodi Anchor-Free
I metodi anchor-free, come CenterNet e FCOS (Fully Convolutional One-Stage Object Detection), eliminano le anchor box predefinite e prevedono direttamente i centri degli oggetti. Questi metodi offrono:
- Architetture di modello più semplici;
- Velocità di inferenza più elevate;
- Migliore generalizzazione a dimensioni di oggetti non viste.
A (Basato su anchor): prevede offset (linee verdi) da anchor predefiniti (blu) per corrispondere al ground truth (rosso). B (Senza anchor): stima direttamente gli offset da un punto ai suoi confini.
La predizione del bounding box è una componente fondamentale del rilevamento oggetti e i diversi approcci bilanciano accuratezza ed efficienza. Mentre i metodi basati su anchor migliorano la precisione utilizzando forme predefinite, quelli senza anchor semplificano il rilevamento prevedendo direttamente la posizione degli oggetti. Comprendere queste tecniche aiuta a progettare sistemi di rilevamento oggetti migliori per varie applicazioni reali.
Grazie per i tuoi commenti!
