Introduzione alle Reti Neurali Convoluzionali
Scorri per mostrare il menu
Che cos'è una CNN e in cosa si differenzia dalle reti neurali tradizionali?
Una convolutional neural network (CNN) è un tipo di intelligenza artificiale che aiuta i computer a "vedere" e comprendere le immagini. A differenza delle reti neurali tradizionali che elaborano le immagini come una lista di numeri, le CNN analizzano le immagini in sezioni, riconoscendo schemi come bordi, forme e texture. Questo le rende molto più efficaci nella gestione di immagini e video.
Come le CNN si ispirano all'occhio umano
Le CNN funzionano in modo simile a come il cervello umano elabora le immagini. Quando osserviamo qualcosa, i nostri occhi inviano informazioni al cervello, che inizialmente riconosce forme semplici come bordi e colori. Successivamente, gli strati più profondi del cervello combinano questi elementi per comprendere oggetti, volti o intere scene. Le CNN seguono lo stesso principio, partendo da caratteristiche semplici fino a riconoscere oggetti complessi.
Proprio come i nostri occhi si concentrano su determinate aree, anche le CNN elaborano le immagini in piccole sezioni, il che le aiuta a riconoscere schemi ovunque essi compaiano. Tuttavia, a differenza degli esseri umani, le CNN necessitano di migliaia di immagini etichettate per apprendere, mentre le persone possono riconoscere oggetti anche dopo averli visti solo poche volte.
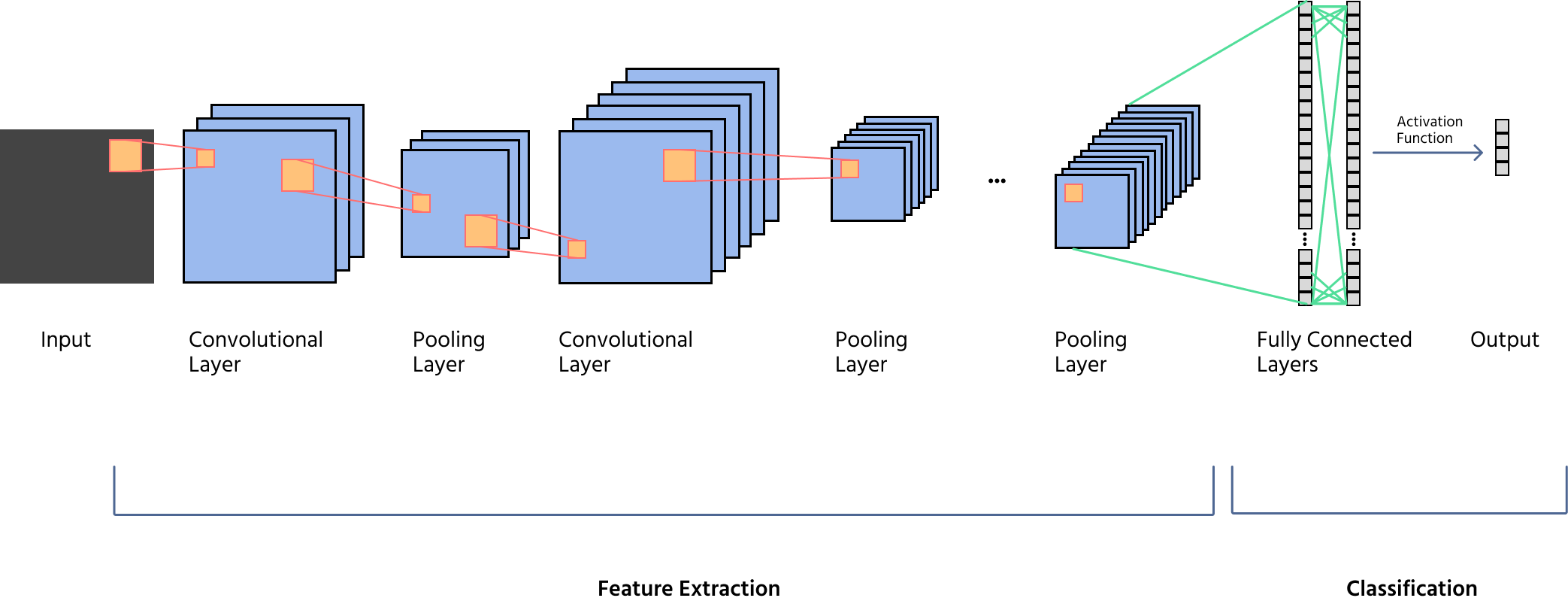
Panoramica dei componenti chiave: convoluzione, pooling, funzioni di attivazione e layer completamente connessi
Una CNN è composta da più layer, ognuno con un ruolo distinto nell'elaborazione delle immagini:
- Applicazione di filtri (kernel) per rilevare pattern come bordi, texture e forme;
- Utilizzo di stride e padding per controllare le dimensioni delle feature map;
- Generazione di più feature map per un'estrazione profonda delle caratteristiche.
- Introduzione della non-linearità, permettendo alle CNN di apprendere rappresentazioni complesse;
- Funzioni comuni includono ReLU (Rectified Linear Unit), Leaky ReLU e Sigmoid.
- Riduzione delle dimensioni spaziali delle feature map preservando le informazioni importanti;
- Tipologie includono max pooling (cattura le caratteristiche dominanti) e average pooling (uniforma le rappresentazioni);
- Favorisce invarianza alla traslazione ed efficienza computazionale.
- Appiattimento delle feature map in un vettore 1D per la classificazione;
- Collegamento a un layer di output finale tramite Softmax (per classificazione multi-classe) o Sigmoid (per classificazione binaria).
Le CNN sono potenti perché possono apprendere automaticamente le caratteristiche dalle immagini senza che sia necessario programmare ogni dettaglio manualmente. Per questo motivo vengono utilizzate in auto a guida autonoma, riconoscimento facciale, imaging medico e molte altre applicazioni reali.
1. Qual è il principale vantaggio delle CNN rispetto alle reti neurali tradizionali nell'elaborazione delle immagini?
2. Abbina l'elemento della CNN alla sua funzione.
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Introduzione alle Reti Neurali Convoluzionali
Che cos'è una CNN e in cosa si differenzia dalle reti neurali tradizionali?
Una convolutional neural network (CNN) è un tipo di intelligenza artificiale che aiuta i computer a "vedere" e comprendere le immagini. A differenza delle reti neurali tradizionali che elaborano le immagini come una lista di numeri, le CNN analizzano le immagini in sezioni, riconoscendo schemi come bordi, forme e texture. Questo le rende molto più efficaci nella gestione di immagini e video.
Come le CNN si ispirano all'occhio umano
Le CNN funzionano in modo simile a come il cervello umano elabora le immagini. Quando osserviamo qualcosa, i nostri occhi inviano informazioni al cervello, che inizialmente riconosce forme semplici come bordi e colori. Successivamente, gli strati più profondi del cervello combinano questi elementi per comprendere oggetti, volti o intere scene. Le CNN seguono lo stesso principio, partendo da caratteristiche semplici fino a riconoscere oggetti complessi.
Proprio come i nostri occhi si concentrano su determinate aree, anche le CNN elaborano le immagini in piccole sezioni, il che le aiuta a riconoscere schemi ovunque essi compaiano. Tuttavia, a differenza degli esseri umani, le CNN necessitano di migliaia di immagini etichettate per apprendere, mentre le persone possono riconoscere oggetti anche dopo averli visti solo poche volte.
Panoramica dei componenti chiave: convoluzione, pooling, funzioni di attivazione e layer completamente connessi
Una CNN è composta da più layer, ognuno con un ruolo distinto nell'elaborazione delle immagini:
- Applicazione di filtri (kernel) per rilevare pattern come bordi, texture e forme;
- Utilizzo di stride e padding per controllare le dimensioni delle feature map;
- Generazione di più feature map per un'estrazione profonda delle caratteristiche.
- Introduzione della non-linearità, permettendo alle CNN di apprendere rappresentazioni complesse;
- Funzioni comuni includono ReLU (Rectified Linear Unit), Leaky ReLU e Sigmoid.
- Riduzione delle dimensioni spaziali delle feature map preservando le informazioni importanti;
- Tipologie includono max pooling (cattura le caratteristiche dominanti) e average pooling (uniforma le rappresentazioni);
- Favorisce invarianza alla traslazione ed efficienza computazionale.
- Appiattimento delle feature map in un vettore 1D per la classificazione;
- Collegamento a un layer di output finale tramite Softmax (per classificazione multi-classe) o Sigmoid (per classificazione binaria).
Le CNN sono potenti perché possono apprendere automaticamente le caratteristiche dalle immagini senza che sia necessario programmare ogni dettaglio manualmente. Per questo motivo vengono utilizzate in auto a guida autonoma, riconoscimento facciale, imaging medico e molte altre applicazioni reali.
Grazie per i tuoi commenti!
