Appiattimento
Scorri per mostrare il menu
Transizione dall'estrazione delle caratteristiche alla classificazione
Dopo che i livelli convoluzionali e di pooling hanno estratto le caratteristiche essenziali da un'immagine, il passo successivo in una rete neurale convoluzionale (CNN) è la classificazione. Poiché i livelli completamente connessi richiedono un input monodimensionale, è necessario convertire le mappe delle caratteristiche multidimensionali in un formato adatto alla classificazione.
Conversione delle mappe delle caratteristiche in un vettore 1D
Il flattening è il processo di rimodellamento dell'output dei livelli convoluzionali e di pooling in un unico vettore lungo. Se una mappa delle caratteristiche ha dimensioni X × Y × Z, il flattening la trasforma in un 1D array di lunghezza X × Y × Z.
Ad esempio, se la mappa delle caratteristiche finale ha dimensioni 7 × 7 × 64, il flattening la converte in un vettore di dimensione (7 × 7 × 64) = 3136-dimensional. Questo consente ai livelli completamente connessi di elaborare in modo efficiente le caratteristiche estratte.
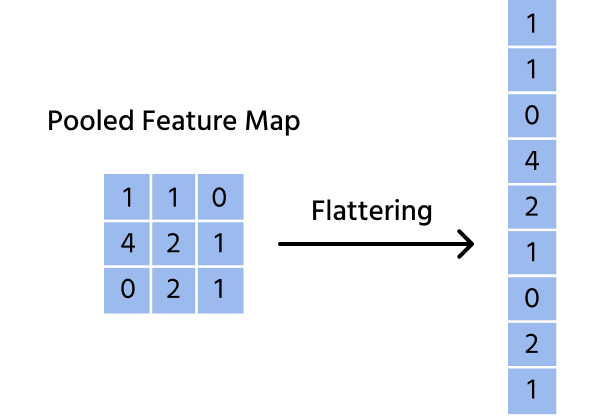
Importanza del Flattening Prima dell'Inserimento nei Layer Completamente Connessi
I layer completamente connessi operano su una struttura standard di rete neurale, in cui ogni neurone è collegato a tutti i neuroni dello strato successivo. Senza il flattening, il modello non può interpretare correttamente la struttura spaziale delle feature map. Il flattening garantisce:
- Transizione corretta dal rilevamento delle caratteristiche alla classificazione;
- Integrazione senza soluzione di continuità con i layer completamente connessi;
- Apprendimento efficiente preservando i pattern estratti per la decisione finale.
Appiattendo le feature map, le CNN possono sfruttare le caratteristiche di alto livello apprese durante la convoluzione e il pooling, consentendo una classificazione accurata degli oggetti all'interno di un'immagine.
1. Perché il flattening è necessario in una CNN?
2. Se una feature map ha dimensioni 10 × 10 × 32, quale sarà la dimensione dell'output appiattito?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Appiattimento
Transizione dall'estrazione delle caratteristiche alla classificazione
Dopo che i livelli convoluzionali e di pooling hanno estratto le caratteristiche essenziali da un'immagine, il passo successivo in una rete neurale convoluzionale (CNN) è la classificazione. Poiché i livelli completamente connessi richiedono un input monodimensionale, è necessario convertire le mappe delle caratteristiche multidimensionali in un formato adatto alla classificazione.
Conversione delle mappe delle caratteristiche in un vettore 1D
Il flattening è il processo di rimodellamento dell'output dei livelli convoluzionali e di pooling in un unico vettore lungo. Se una mappa delle caratteristiche ha dimensioni X × Y × Z, il flattening la trasforma in un 1D array di lunghezza X × Y × Z.
Ad esempio, se la mappa delle caratteristiche finale ha dimensioni 7 × 7 × 64, il flattening la converte in un vettore di dimensione (7 × 7 × 64) = 3136-dimensional. Questo consente ai livelli completamente connessi di elaborare in modo efficiente le caratteristiche estratte.
Importanza del Flattening Prima dell'Inserimento nei Layer Completamente Connessi
I layer completamente connessi operano su una struttura standard di rete neurale, in cui ogni neurone è collegato a tutti i neuroni dello strato successivo. Senza il flattening, il modello non può interpretare correttamente la struttura spaziale delle feature map. Il flattening garantisce:
- Transizione corretta dal rilevamento delle caratteristiche alla classificazione;
- Integrazione senza soluzione di continuità con i layer completamente connessi;
- Apprendimento efficiente preservando i pattern estratti per la decisione finale.
Appiattendo le feature map, le CNN possono sfruttare le caratteristiche di alto livello apprese durante la convoluzione e il pooling, consentendo una classificazione accurata degli oggetti all'interno di un'immagine.
Grazie per i tuoi commenti!
