Panoramica della Generazione di Immagini
Scorri per mostrare il menu
Le immagini generate dall'IA stanno cambiando il modo in cui le persone creano arte, design e contenuti digitali. Con l'aiuto dell'intelligenza artificiale, i computer possono ora realizzare immagini realistiche, migliorare il lavoro creativo e persino supportare le aziende. In questo capitolo, esploreremo come l'IA crea immagini, i diversi tipi di modelli per la generazione di immagini e come vengono utilizzati nella vita reale.
Come l'IA crea immagini
La generazione di immagini tramite IA funziona imparando da una vasta raccolta di immagini. L'IA studia i modelli presenti nelle immagini e poi crea nuove immagini che appaiono simili. Questa tecnologia è notevolmente migliorata negli anni, producendo immagini sempre più realistiche e creative. Oggi viene utilizzata nei videogiochi, nei film, nella pubblicità e persino nella moda.
Metodi iniziali: PixelRNN e PixelCNN
Prima dei moderni modelli avanzati di IA, i ricercatori hanno sviluppato metodi iniziali per la generazione di immagini come PixelRNN e PixelCNN. Questi modelli creavano immagini prevedendo un pixel alla volta.
- PixelRNN: utilizza un sistema chiamato rete neurale ricorrente (RNN) per prevedere i colori dei pixel uno dopo l'altro. Sebbene funzionasse bene, era molto lento;
- PixelCNN: ha migliorato PixelRNN utilizzando un diverso tipo di rete, chiamata strati convoluzionali, che ha reso la creazione delle immagini più veloce.
Anche se questi modelli sono stati un buon punto di partenza, non erano in grado di produrre immagini di alta qualità. Questo ha portato allo sviluppo di tecniche migliori.
Modelli Autoregressivi
I modelli autoregressivi generano immagini un pixel alla volta, utilizzando i pixel precedenti per prevedere quelli successivi. Questi modelli sono stati utili ma lenti, il che li ha resi meno popolari nel tempo. Tuttavia, hanno ispirato modelli più recenti e veloci.
Come l'IA Comprende il Testo per la Creazione di Immagini
Alcuni modelli di IA possono trasformare parole scritte in immagini. Questi modelli utilizzano i Large Language Models (LLM) per comprendere le descrizioni e generare immagini corrispondenti. Ad esempio, se si digita “a cat sitting on a beach at sunset”, l'IA creerà un'immagine basata su quella descrizione.
Modelli di IA come DALL-E di OpenAI e Imagen di Google utilizzano una comprensione avanzata del linguaggio per migliorare la corrispondenza tra le descrizioni testuali e le immagini generate. Questo è possibile grazie al Natural Language Processing (NLP), che aiuta l'IA a trasformare le parole in numeri che guidano la creazione delle immagini.
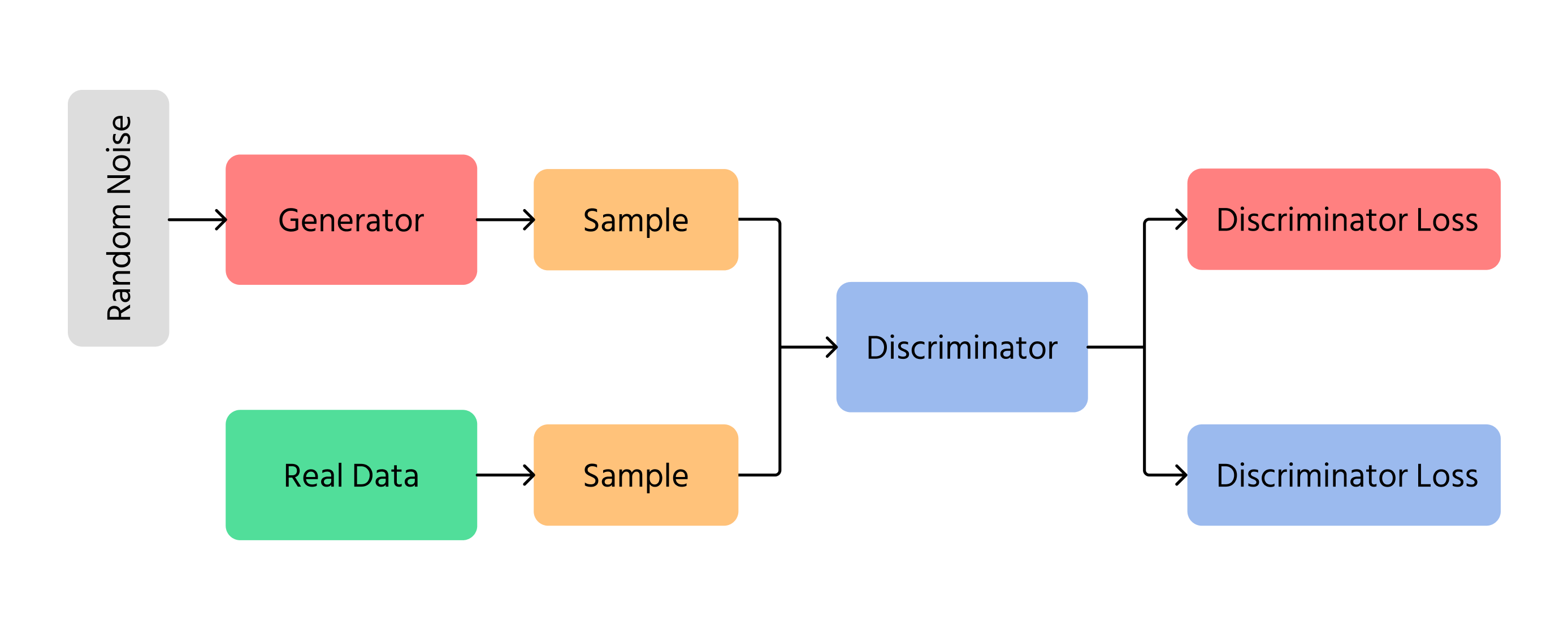
Generative Adversarial Networks (GAN)
Una delle scoperte più importanti nella generazione di immagini tramite IA è stata rappresentata dalle Generative Adversarial Networks (GAN). Le GAN funzionano utilizzando due diverse reti neurali:
- Generatore: crea nuove immagini da zero;
- Discriminatore: verifica se le immagini sembrano reali o false.
Il generatore cerca di produrre immagini così realistiche che il discriminatore non riesce a distinguerle da quelle vere. Nel tempo, le immagini migliorano e appaiono sempre più simili a fotografie reali. Le GAN vengono utilizzate nella tecnologia deepfake, nella creazione di opere d'arte e nel miglioramento della qualità delle immagini.
Autoencoder Variazionali (VAE)
I VAE rappresentano un altro metodo con cui l'intelligenza artificiale può generare immagini. Invece di utilizzare la competizione come i GAN, i VAE codificano e decodificano le immagini utilizzando la probabilità. Funzionano imparando i modelli sottostanti di un'immagine e poi ricostruendola con leggere variazioni. L'elemento probabilistico nei VAE garantisce che ogni immagine generata sia leggermente diversa, aggiungendo varietà e creatività.
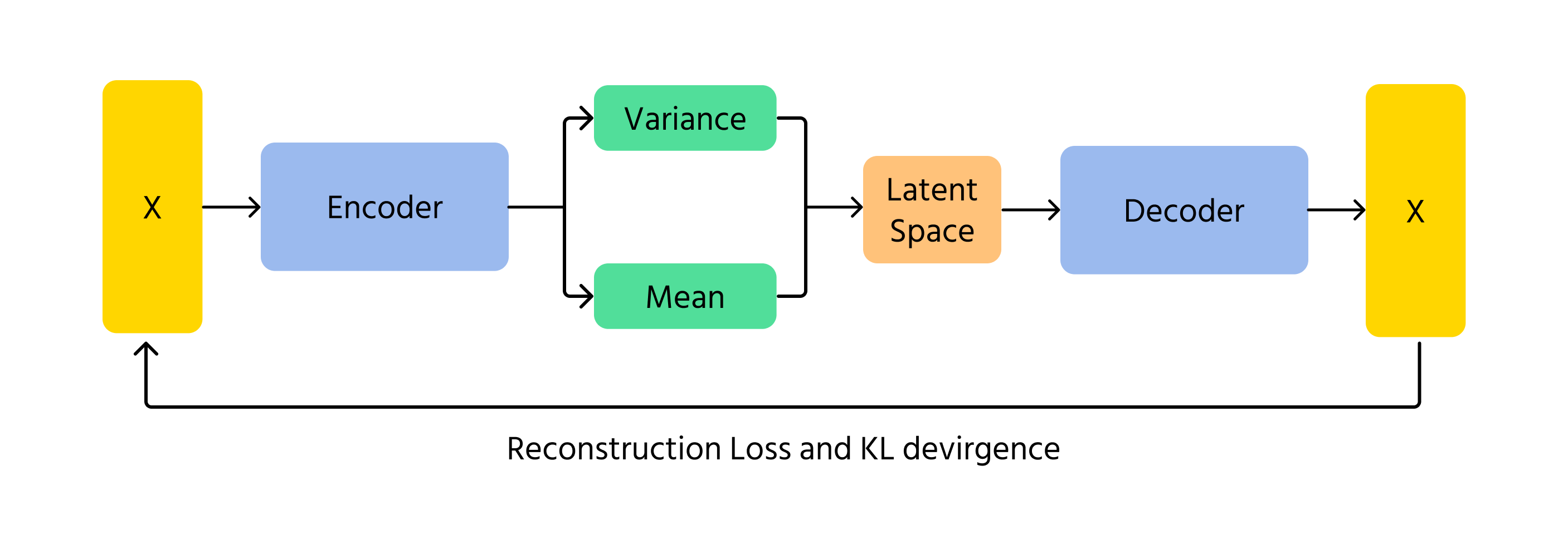
Un concetto chiave nei VAE è la divergenza di Kullback-Leibler (KL), che misura la differenza tra la distribuzione appresa e una distribuzione normale standard. Minimizzando la divergenza KL, i VAE garantiscono che le immagini generate rimangano realistiche pur consentendo variazioni creative.
Funzionamento dei VAE
- Codifica: i dati di input x vengono inseriti nell'encoder, che restituisce i parametri della distribuzione dello spazio latente q(z∣x) (media μ e varianza σ²);
- Campionamento nello spazio latente: le variabili latenti z vengono campionate dalla distribuzione q(z∣x) utilizzando tecniche come il trucco di riparametrizzazione;
- Decodifica e ricostruzione: il z campionato viene passato attraverso il decoder per produrre i dati ricostruiti x̂, che dovrebbero essere simili all'input originale x.
I VAE sono utili per attività come la ricostruzione di volti, la generazione di nuove versioni di immagini esistenti e la creazione di transizioni fluide tra immagini diverse.
Modelli di Diffusione
I modelli di diffusione rappresentano l'ultima innovazione nella generazione di immagini tramite IA. Questi modelli partono da un rumore casuale e migliorano gradualmente l'immagine passo dopo passo, come se si eliminasse la staticità da una foto sfocata. A differenza dei GAN, che a volte producono variazioni limitate, i modelli di diffusione possono generare una gamma più ampia di immagini di alta qualità.
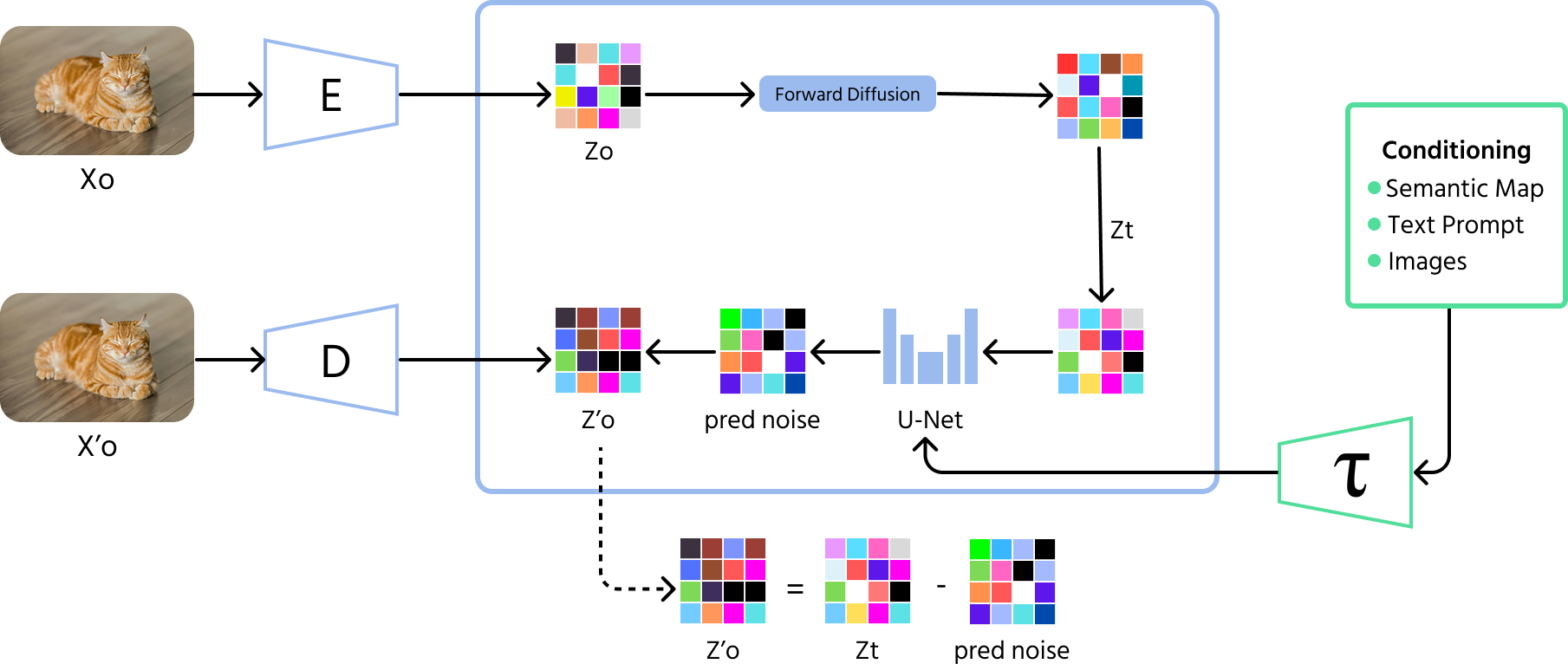
Funzionamento dei modelli di diffusione
- Processo diretto (aggiunta di rumore): il modello inizia aggiungendo rumore casuale a un'immagine attraverso molti passaggi fino a renderla completamente irriconoscibile;
- Processo inverso (rimozione del rumore): il modello apprende quindi come invertire questo processo, rimuovendo gradualmente il rumore passo dopo passo per recuperare un'immagine significativa;
- Addestramento: i modelli di diffusione vengono addestrati a prevedere e rimuovere il rumore a ogni passaggio, aiutandoli a generare immagini chiare e di alta qualità a partire da rumore casuale.
Un esempio popolare è MidJourney, DALL-E e Stable Diffusion, noto per la creazione di immagini realistiche e artistiche. I modelli di diffusione sono ampiamente utilizzati per arte generata dall'IA, sintesi di immagini ad alta risoluzione e applicazioni di design creativo.
Esempi di immagini generate da modelli di diffusione

Immagine realistica di un giocatore di basket con la barba in una divisa giallo-viola che schiaccia e sconfigge demoni in una partita di basket, tutta l'azione si svolge all'inferno.

Foto artistica surrealista e bellissima di una Volkswagen Golf GTI bianca del 1990 in un campo infinito di fiori bianchi in armonia con la natura, al centro di colline infinite piene di fiori, botanica, luce naturale, artistica, nebbiosa, fotorealistica, surrealista, ultra dettagliata, pellicola kodak, luce naturale, obiettivo grandangolare, f 1.20

Dipinto di un cane Barboncino beige sdraiato su un divano verde con cuscino a righe verdi e bianche nello stile di Fairfield Porter, espressionismo astratto, con pennellate audaci su sfondo beige

Primo piano estremo della pelle di una donna mediterranea o latina, che mette in risalto un tipo di pelle mista con evidente untuosità su fronte e naso, mentre le guance appaiono più secche e leggermente desquamate. I pori sono più visibili nella zona T e c'è una naturale lucentezza dovuta alla produzione di sebo. La pelle presenta una combinazione di sottotoni caldi e dorati, con una texture irregolare dovuta ai diversi livelli di idratazione. Una luce soffusa e naturale enfatizza il contrasto realistico tra le aree secche e quelle oleose. Lo sfondo è sfocato, mantenendo l'attenzione sull'incarnato.
Sfide e questioni etiche
Anche se le immagini generate dall'IA sono impressionanti, presentano delle sfide:
- Mancanza di controllo: l'IA potrebbe non generare sempre esattamente ciò che l'utente desidera;
- Potenza di calcolo: la creazione di immagini IA di alta qualità richiede computer potenti e costosi;
- Bias nei modelli IA: poiché l'IA apprende da immagini esistenti, può talvolta ripetere i pregiudizi presenti nei dati.
Esistono anche questioni etiche:
- Chi possiede l'arte generata dall'IA?: se un'IA crea un'opera d'arte, la proprietà spetta a chi ha utilizzato l'IA o all'azienda che la produce?
- Immagini false e deepfake: le GAN possono essere utilizzate per creare immagini false che sembrano reali, con possibili conseguenze su disinformazione e privacy.
Utilizzi attuali della generazione di immagini IA
Le immagini generate dall'IA stanno già avendo un grande impatto in diversi settori:
- Intrattenimento: videogiochi, film e animazione utilizzano l'IA per creare sfondi, personaggi ed effetti;
- Moda: i designer usano l'IA per creare nuovi stili di abbigliamento e i negozi online propongono prove virtuali ai clienti;
- Graphic design: l'IA aiuta artisti e designer a realizzare rapidamente loghi, poster e materiali di marketing.
Il futuro della generazione di immagini AI
Con il continuo miglioramento della generazione di immagini tramite AI, cambierà sempre di più il modo in cui le persone creano e utilizzano le immagini. Nell'arte, nel business o nell'intrattenimento, l'AI sta aprendo nuove possibilità e rendendo il lavoro creativo più semplice e stimolante.
1. Qual è lo scopo principale della generazione di immagini tramite AI?
2. Come funzionano le Generative Adversarial Networks (GANs)?
3. Quale modello di intelligenza artificiale inizia con rumore casuale e migliora l'immagine passo dopo passo?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Panoramica della Generazione di Immagini
Le immagini generate dall'IA stanno cambiando il modo in cui le persone creano arte, design e contenuti digitali. Con l'aiuto dell'intelligenza artificiale, i computer possono ora realizzare immagini realistiche, migliorare il lavoro creativo e persino supportare le aziende. In questo capitolo, esploreremo come l'IA crea immagini, i diversi tipi di modelli per la generazione di immagini e come vengono utilizzati nella vita reale.
Come l'IA crea immagini
La generazione di immagini tramite IA funziona imparando da una vasta raccolta di immagini. L'IA studia i modelli presenti nelle immagini e poi crea nuove immagini che appaiono simili. Questa tecnologia è notevolmente migliorata negli anni, producendo immagini sempre più realistiche e creative. Oggi viene utilizzata nei videogiochi, nei film, nella pubblicità e persino nella moda.
Metodi iniziali: PixelRNN e PixelCNN
Prima dei moderni modelli avanzati di IA, i ricercatori hanno sviluppato metodi iniziali per la generazione di immagini come PixelRNN e PixelCNN. Questi modelli creavano immagini prevedendo un pixel alla volta.
- PixelRNN: utilizza un sistema chiamato rete neurale ricorrente (RNN) per prevedere i colori dei pixel uno dopo l'altro. Sebbene funzionasse bene, era molto lento;
- PixelCNN: ha migliorato PixelRNN utilizzando un diverso tipo di rete, chiamata strati convoluzionali, che ha reso la creazione delle immagini più veloce.
Anche se questi modelli sono stati un buon punto di partenza, non erano in grado di produrre immagini di alta qualità. Questo ha portato allo sviluppo di tecniche migliori.
Modelli Autoregressivi
I modelli autoregressivi generano immagini un pixel alla volta, utilizzando i pixel precedenti per prevedere quelli successivi. Questi modelli sono stati utili ma lenti, il che li ha resi meno popolari nel tempo. Tuttavia, hanno ispirato modelli più recenti e veloci.
Come l'IA Comprende il Testo per la Creazione di Immagini
Alcuni modelli di IA possono trasformare parole scritte in immagini. Questi modelli utilizzano i Large Language Models (LLM) per comprendere le descrizioni e generare immagini corrispondenti. Ad esempio, se si digita “a cat sitting on a beach at sunset”, l'IA creerà un'immagine basata su quella descrizione.
Modelli di IA come DALL-E di OpenAI e Imagen di Google utilizzano una comprensione avanzata del linguaggio per migliorare la corrispondenza tra le descrizioni testuali e le immagini generate. Questo è possibile grazie al Natural Language Processing (NLP), che aiuta l'IA a trasformare le parole in numeri che guidano la creazione delle immagini.
Generative Adversarial Networks (GAN)
Una delle scoperte più importanti nella generazione di immagini tramite IA è stata rappresentata dalle Generative Adversarial Networks (GAN). Le GAN funzionano utilizzando due diverse reti neurali:
- Generatore: crea nuove immagini da zero;
- Discriminatore: verifica se le immagini sembrano reali o false.
Il generatore cerca di produrre immagini così realistiche che il discriminatore non riesce a distinguerle da quelle vere. Nel tempo, le immagini migliorano e appaiono sempre più simili a fotografie reali. Le GAN vengono utilizzate nella tecnologia deepfake, nella creazione di opere d'arte e nel miglioramento della qualità delle immagini.
Autoencoder Variazionali (VAE)
I VAE rappresentano un altro metodo con cui l'intelligenza artificiale può generare immagini. Invece di utilizzare la competizione come i GAN, i VAE codificano e decodificano le immagini utilizzando la probabilità. Funzionano imparando i modelli sottostanti di un'immagine e poi ricostruendola con leggere variazioni. L'elemento probabilistico nei VAE garantisce che ogni immagine generata sia leggermente diversa, aggiungendo varietà e creatività.
Un concetto chiave nei VAE è la divergenza di Kullback-Leibler (KL), che misura la differenza tra la distribuzione appresa e una distribuzione normale standard. Minimizzando la divergenza KL, i VAE garantiscono che le immagini generate rimangano realistiche pur consentendo variazioni creative.
Funzionamento dei VAE
- Codifica: i dati di input x vengono inseriti nell'encoder, che restituisce i parametri della distribuzione dello spazio latente q(z∣x) (media μ e varianza σ²);
- Campionamento nello spazio latente: le variabili latenti z vengono campionate dalla distribuzione q(z∣x) utilizzando tecniche come il trucco di riparametrizzazione;
- Decodifica e ricostruzione: il z campionato viene passato attraverso il decoder per produrre i dati ricostruiti x̂, che dovrebbero essere simili all'input originale x.
I VAE sono utili per attività come la ricostruzione di volti, la generazione di nuove versioni di immagini esistenti e la creazione di transizioni fluide tra immagini diverse.
Modelli di Diffusione
I modelli di diffusione rappresentano l'ultima innovazione nella generazione di immagini tramite IA. Questi modelli partono da un rumore casuale e migliorano gradualmente l'immagine passo dopo passo, come se si eliminasse la staticità da una foto sfocata. A differenza dei GAN, che a volte producono variazioni limitate, i modelli di diffusione possono generare una gamma più ampia di immagini di alta qualità.
Funzionamento dei modelli di diffusione
- Processo diretto (aggiunta di rumore): il modello inizia aggiungendo rumore casuale a un'immagine attraverso molti passaggi fino a renderla completamente irriconoscibile;
- Processo inverso (rimozione del rumore): il modello apprende quindi come invertire questo processo, rimuovendo gradualmente il rumore passo dopo passo per recuperare un'immagine significativa;
- Addestramento: i modelli di diffusione vengono addestrati a prevedere e rimuovere il rumore a ogni passaggio, aiutandoli a generare immagini chiare e di alta qualità a partire da rumore casuale.
Un esempio popolare è MidJourney, DALL-E e Stable Diffusion, noto per la creazione di immagini realistiche e artistiche. I modelli di diffusione sono ampiamente utilizzati per arte generata dall'IA, sintesi di immagini ad alta risoluzione e applicazioni di design creativo.
Esempi di immagini generate da modelli di diffusione
Immagine realistica di un giocatore di basket con la barba in una divisa giallo-viola che schiaccia e sconfigge demoni in una partita di basket, tutta l'azione si svolge all'inferno.
Foto artistica surrealista e bellissima di una Volkswagen Golf GTI bianca del 1990 in un campo infinito di fiori bianchi in armonia con la natura, al centro di colline infinite piene di fiori, botanica, luce naturale, artistica, nebbiosa, fotorealistica, surrealista, ultra dettagliata, pellicola kodak, luce naturale, obiettivo grandangolare, f 1.20
Dipinto di un cane Barboncino beige sdraiato su un divano verde con cuscino a righe verdi e bianche nello stile di Fairfield Porter, espressionismo astratto, con pennellate audaci su sfondo beige
Primo piano estremo della pelle di una donna mediterranea o latina, che mette in risalto un tipo di pelle mista con evidente untuosità su fronte e naso, mentre le guance appaiono più secche e leggermente desquamate. I pori sono più visibili nella zona T e c'è una naturale lucentezza dovuta alla produzione di sebo. La pelle presenta una combinazione di sottotoni caldi e dorati, con una texture irregolare dovuta ai diversi livelli di idratazione. Una luce soffusa e naturale enfatizza il contrasto realistico tra le aree secche e quelle oleose. Lo sfondo è sfocato, mantenendo l'attenzione sull'incarnato.
Sfide e questioni etiche
Anche se le immagini generate dall'IA sono impressionanti, presentano delle sfide:
- Mancanza di controllo: l'IA potrebbe non generare sempre esattamente ciò che l'utente desidera;
- Potenza di calcolo: la creazione di immagini IA di alta qualità richiede computer potenti e costosi;
- Bias nei modelli IA: poiché l'IA apprende da immagini esistenti, può talvolta ripetere i pregiudizi presenti nei dati.
Esistono anche questioni etiche:
- Chi possiede l'arte generata dall'IA?: se un'IA crea un'opera d'arte, la proprietà spetta a chi ha utilizzato l'IA o all'azienda che la produce?
- Immagini false e deepfake: le GAN possono essere utilizzate per creare immagini false che sembrano reali, con possibili conseguenze su disinformazione e privacy.
Utilizzi attuali della generazione di immagini IA
Le immagini generate dall'IA stanno già avendo un grande impatto in diversi settori:
- Intrattenimento: videogiochi, film e animazione utilizzano l'IA per creare sfondi, personaggi ed effetti;
- Moda: i designer usano l'IA per creare nuovi stili di abbigliamento e i negozi online propongono prove virtuali ai clienti;
- Graphic design: l'IA aiuta artisti e designer a realizzare rapidamente loghi, poster e materiali di marketing.
Il futuro della generazione di immagini AI
Con il continuo miglioramento della generazione di immagini tramite AI, cambierà sempre di più il modo in cui le persone creano e utilizzano le immagini. Nell'arte, nel business o nell'intrattenimento, l'AI sta aprendo nuove possibilità e rendendo il lavoro creativo più semplice e stimolante.
Grazie per i tuoi commenti!
