Apprendimento Trasferito nella Visione Artificiale
Scorri per mostrare il menu
Transfer learning consente di riutilizzare modelli addestrati su grandi dataset per nuovi compiti con dati limitati. Invece di costruire una rete neurale da zero, si sfruttano modelli pre-addestrati per migliorare efficienza e prestazioni. Nel corso di questa formazione, sono già stati presentati approcci simili nelle sezioni precedenti, che hanno posto le basi per applicare efficacemente il transfer learning.
Cos'è il Transfer Learning?
Transfer learning è una tecnica in cui un modello addestrato su un compito viene adattato a un altro compito correlato. In ambito computer vision, modelli pre-addestrati su grandi dataset come ImageNet possono essere perfezionati per applicazioni specifiche come imaging medico o guida autonoma.
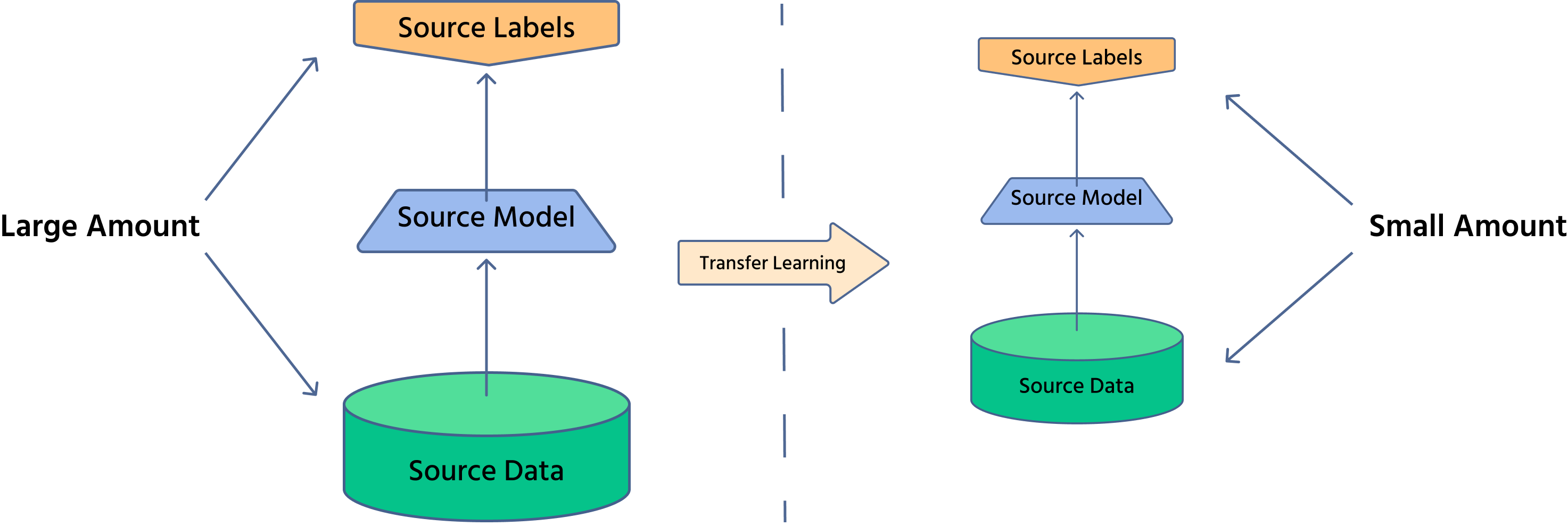
Perché il Transfer Learning è Importante?
- Riduce il tempo di addestramento: poiché il modello ha già appreso caratteristiche generali, sono necessarie solo lievi modifiche;
- Richiede meno dati: utile nei casi in cui ottenere dati etichettati è costoso;
- Migliora le prestazioni: i modelli pre-addestrati offrono un'estrazione di caratteristiche robusta, aumentando l'accuratezza.
Flusso di Lavoro del Transfer Learning
Il flusso di lavoro tipico del transfer learning comprende diversi passaggi chiave:
-
Selezione di un Modello Pre-addestrato:
- Scegliere un modello addestrato su un grande dataset (ad esempio, ResNet, VGG, YOLO);
- Questi modelli hanno appreso rappresentazioni utili che possono essere adattate a nuovi compiti.
-
Modifica del Modello Pre-addestrato:
- Estrazione delle caratteristiche: congelare i primi strati e riaddestrare solo gli strati finali per il nuovo compito;
- Fine-tuning: sbloccare alcuni o tutti gli strati e riaddestrarli sul nuovo dataset.
-
Addestramento sul Nuovo Dataset:
- Addestrare il modello modificato utilizzando un dataset più piccolo specifico per il compito target;
- Ottimizzare utilizzando tecniche come backpropagation e funzioni di perdita.
-
Valutazione e Iterazione:
- Valutare le prestazioni utilizzando metriche come accuratezza, precisione, recall e mAP;
- Eseguire ulteriori ottimizzazioni se necessario per migliorare i risultati.
Modelli Pre-addestrati Popolari
Alcuni dei modelli pre-addestrati più utilizzati per la computer vision includono:
- ResNet: reti neurali profonde residuali che permettono l'addestramento di architetture molto profonde;
- VGG: un'architettura semplice con strati convoluzionali uniformi;
- EfficientNet: ottimizzato per alta accuratezza con meno parametri;
- YOLO: rilevamento oggetti in tempo reale allo stato dell'arte (SOTA).
Fine-Tuning vs. Feature Extraction
Estrazione delle caratteristiche implica l'utilizzo degli strati di un modello pre-addestrato come estrattori di caratteristiche fissi. In questo approccio, lo strato di classificazione finale del modello originale viene solitamente rimosso e sostituito con uno nuovo specifico per il compito target. Gli strati pre-addestrati rimangono congelati, ovvero i loro pesi non vengono aggiornati durante l'addestramento, il che accelera il processo e richiede meno dati.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Fine-tuning, invece, va oltre sbloccando alcuni o tutti gli strati pre-addestrati e riaddestrandoli sul nuovo dataset. Questo consente al modello di adattare le caratteristiche apprese in modo più specifico alle peculiarità del nuovo compito, portando spesso a prestazioni migliori—soprattutto quando il nuovo dataset è sufficientemente ampio o differisce in modo significativo dai dati di addestramento originali.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Applicazioni del Transfer Learning
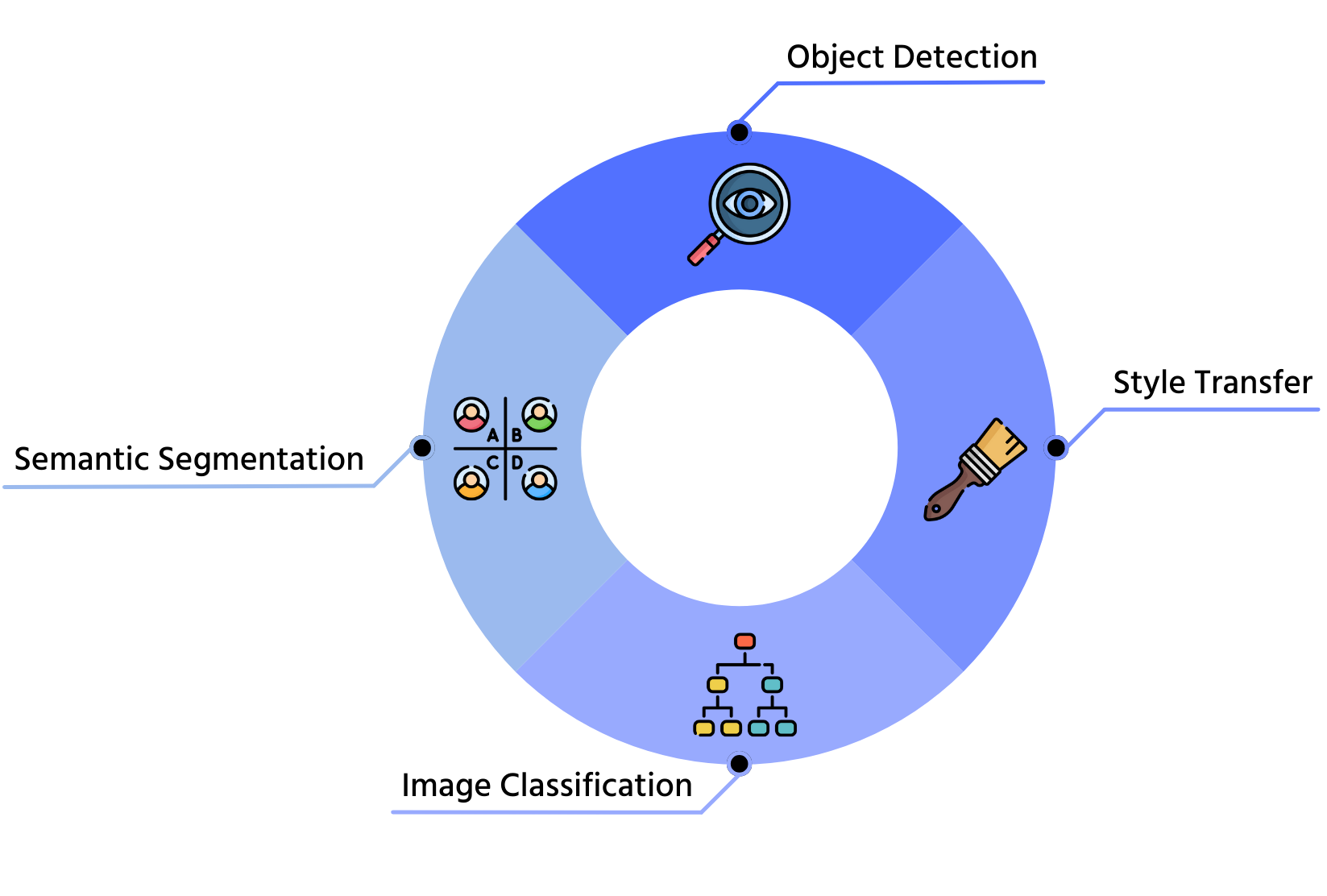
1. Classificazione delle Immagini
La classificazione delle immagini consiste nell'assegnare etichette alle immagini in base al loro contenuto visivo. Modelli pre-addestrati come ResNet ed EfficientNet possono essere adattati per compiti specifici come imaging medico o classificazione della fauna selvatica.
Esempio:
- Selezione di un modello pre-addestrato (ad esempio, ResNet);
- Modifica dello strato di classificazione per adattarsi alle classi target;
- Ottimizzazione fine con un tasso di apprendimento più basso.
2. Rilevamento Oggetti
Il rilevamento oggetti comprende sia l'identificazione che la localizzazione degli oggetti all'interno di un'immagine. Il transfer learning consente a modelli come Faster R-CNN, SSD e YOLO di rilevare oggetti specifici in nuovi dataset in modo efficiente.
Esempio:
- Utilizzo di un modello di rilevamento oggetti pre-addestrato (ad esempio, YOLOv8);
- Ottimizzazione fine su un dataset personalizzato con nuove classi di oggetti;
- Valutazione delle prestazioni e ottimizzazione di conseguenza.
3. Segmentazione Semantica
La segmentazione semantica classifica ogni pixel di un'immagine in categorie predefinite. Modelli come U-Net e DeepLab sono ampiamente utilizzati in applicazioni come guida autonoma e imaging medico.
Esempio:
- Utilizzo di un modello di segmentazione pre-addestrato (ad esempio, U-Net);
- Addestramento su un dataset specifico del dominio;
- Regolazione degli iperparametri per una maggiore accuratezza.
4. Trasferimento di Stile
Il trasferimento di stile applica lo stile visivo di un'immagine a un'altra mantenendone il contenuto originale. Questa tecnica è comunemente utilizzata in arte digitale e miglioramento delle immagini, sfruttando modelli pre-addestrati come VGG.
Esempio:
- Selezione di un modello di trasferimento di stile (ad esempio, VGG);
- Inserimento di immagini di contenuto e di stile;
- Ottimizzazione per risultati visivamente gradevoli.
1. Qual è il principale vantaggio dell'utilizzo del transfer learning nella computer vision?
2. Quale approccio viene utilizzato nell'apprendimento trasferito quando solo l'ultimo strato di un modello pre-addestrato viene modificato mentre gli strati precedenti rimangono fissi?
3. Quale dei seguenti modelli è comunemente utilizzato per l'apprendimento trasferito nel rilevamento degli oggetti?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
