Box di Ancoraggio
Scorri per mostrare il menu
Anchor box è un riquadro di delimitazione predefinito con dimensioni e rapporto d'aspetto fissi, posizionato in punti specifici su un'immagine.
Perché si utilizzano gli Anchor Box nell'Object Detection
Gli anchor box sono un concetto fondamentale nei moderni modelli di object detection come Faster R-CNN e YOLO. Fungono da riquadri di riferimento predefiniti che aiutano a rilevare oggetti di diverse dimensioni e rapporti d'aspetto, rendendo il rilevamento più veloce e affidabile.
Invece di rilevare gli oggetti da zero, i modelli utilizzano gli anchor box come punti di partenza, adattandoli per meglio corrispondere agli oggetti rilevati. Questo approccio migliora l'efficienza e l'accuratezza, soprattutto per il rilevamento di oggetti su scale differenti.
Differenza tra Anchor Box e Bounding Box
- Anchor Box: modello predefinito che funge da riferimento durante l'object detection;
- Bounding Box: riquadro finale previsto dopo che sono state apportate modifiche a un anchor box per adattarsi all'oggetto reale.

A differenza dei bounding box, che vengono regolati dinamicamente durante la previsione, gli anchor box sono fissati in posizioni specifiche prima che avvenga qualsiasi rilevamento di oggetti. I modelli imparano a perfezionare gli anchor box modificandone dimensione, posizione e rapporto d'aspetto, trasformandoli infine in bounding box finali che rappresentano accuratamente gli oggetti rilevati.
Come una rete genera gli anchor box
Gli anchor box non vengono applicati direttamente a un'immagine, ma alle feature map estratte dall'immagine stessa. Dopo l'estrazione delle feature, un insieme di anchor box viene posizionato su queste feature map, variando per dimensione e rapporto d'aspetto. La scelta delle forme degli anchor box è fondamentale e richiede un equilibrio tra il rilevamento di oggetti piccoli e grandi.
Per definire le dimensioni degli anchor box, i modelli utilizzano tipicamente una combinazione di selezione manuale e algoritmi di clustering come K-Means per analizzare il dataset e determinare le forme e dimensioni di oggetti più comuni. Questi anchor box predefiniti vengono poi applicati in diverse posizioni sulle feature map. Ad esempio, un modello di object detection può utilizzare anchor box di dimensioni (16x16), (32x32), (64x64), con rapporti d'aspetto come 1:1, 1:2, and 2:1.
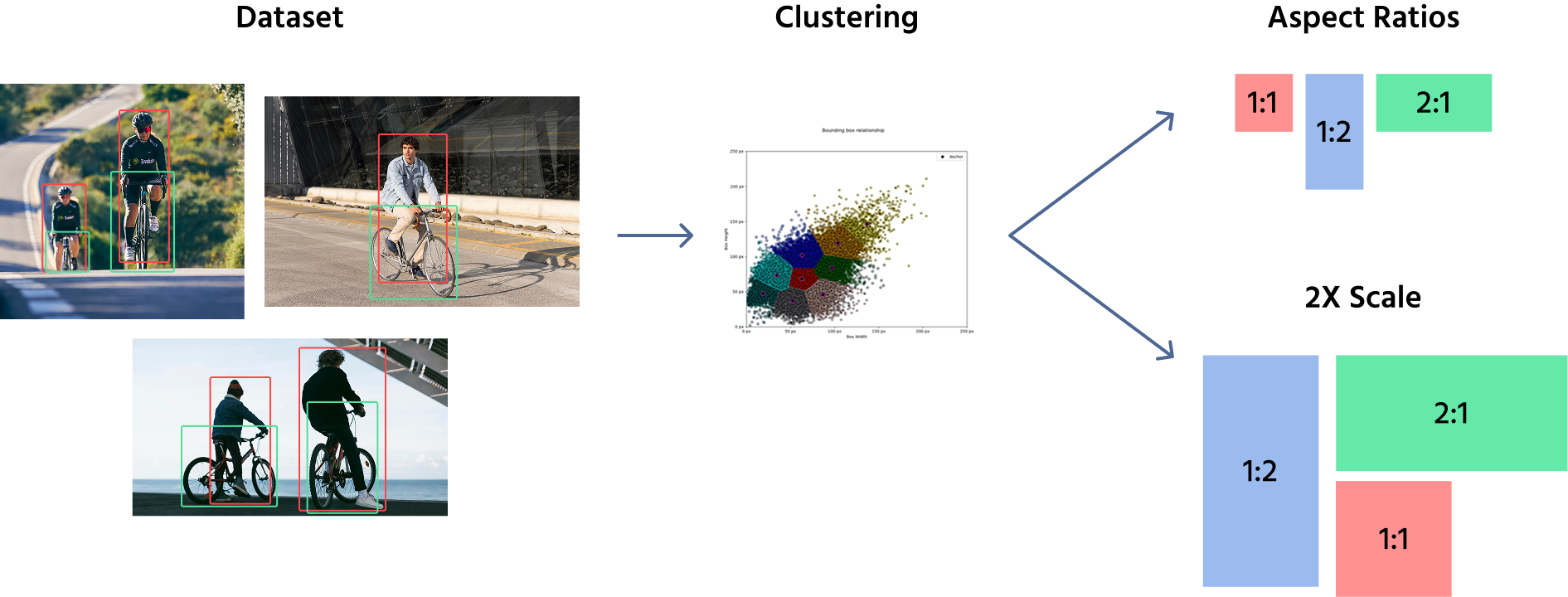
Una volta definiti questi anchor box, essi vengono applicati alle feature map, non all'immagine originale. Il modello assegna più anchor box a ciascuna posizione della feature map, coprendo diverse forme e dimensioni. Durante l'addestramento, la rete regola gli anchor box prevedendo degli offset, perfezionando così la loro dimensione e posizione per adattarsi meglio agli oggetti.
Da Anchor Box a Bounding Box
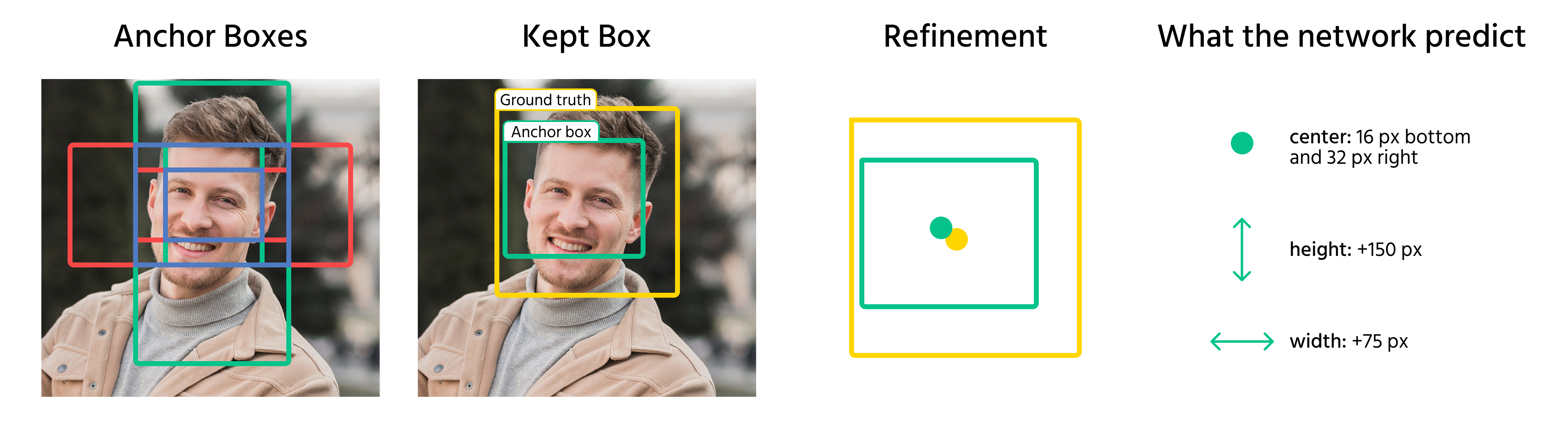
Una volta che gli anchor box sono assegnati agli oggetti, il modello prevede degli offset per perfezionarli. Questi offset includono:
- Regolazione delle coordinate del centro del box;
- Ridimensionamento della larghezza e dell'altezza;
- Spostamento del box per allinearlo meglio all'oggetto.
Applicando queste trasformazioni, il modello converte gli anchor box in bounding box finali che corrispondono accuratamente agli oggetti in un'immagine.
Approcci che non utilizzano ancore o ne riducono il numero
Sebbene le anchor box siano ampiamente utilizzate, alcuni modelli mirano a ridurne la dipendenza o a eliminarle completamente:
- Metodi anchor-free: modelli come
CenterNeteFCOSprevedono direttamente le posizioni degli oggetti senza ancore predefinite, riducendo la complessità; - Approcci con ancore ridotte:
EfficientDeteYOLOv4ottimizzano il numero di anchor box utilizzate, bilanciando velocità di rilevamento e accuratezza.
Questi approcci puntano a migliorare l'efficienza del rilevamento degli oggetti mantenendo alte prestazioni, in particolare per applicazioni in tempo reale.
In sintesi, le anchor box rappresentano una parte fondamentale del rilevamento degli oggetti, aiutando i modelli a rilevare oggetti in modo efficiente su diverse dimensioni e proporzioni. Tuttavia, i nuovi sviluppi stanno esplorando modi per ridurre o eliminare le anchor box per un rilevamento ancora più rapido e flessibile.
1. Qual è il ruolo principale delle anchor box nel rilevamento degli oggetti?
2. In che modo le anchor box differiscono dalle bounding box?
3. Quale metodo viene comunemente utilizzato per determinare le dimensioni ottimali delle anchor box?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Box di Ancoraggio
Anchor box è un riquadro di delimitazione predefinito con dimensioni e rapporto d'aspetto fissi, posizionato in punti specifici su un'immagine.
Perché si utilizzano gli Anchor Box nell'Object Detection
Gli anchor box sono un concetto fondamentale nei moderni modelli di object detection come Faster R-CNN e YOLO. Fungono da riquadri di riferimento predefiniti che aiutano a rilevare oggetti di diverse dimensioni e rapporti d'aspetto, rendendo il rilevamento più veloce e affidabile.
Invece di rilevare gli oggetti da zero, i modelli utilizzano gli anchor box come punti di partenza, adattandoli per meglio corrispondere agli oggetti rilevati. Questo approccio migliora l'efficienza e l'accuratezza, soprattutto per il rilevamento di oggetti su scale differenti.
Differenza tra Anchor Box e Bounding Box
- Anchor Box: modello predefinito che funge da riferimento durante l'object detection;
- Bounding Box: riquadro finale previsto dopo che sono state apportate modifiche a un anchor box per adattarsi all'oggetto reale.
A differenza dei bounding box, che vengono regolati dinamicamente durante la previsione, gli anchor box sono fissati in posizioni specifiche prima che avvenga qualsiasi rilevamento di oggetti. I modelli imparano a perfezionare gli anchor box modificandone dimensione, posizione e rapporto d'aspetto, trasformandoli infine in bounding box finali che rappresentano accuratamente gli oggetti rilevati.
Come una rete genera gli anchor box
Gli anchor box non vengono applicati direttamente a un'immagine, ma alle feature map estratte dall'immagine stessa. Dopo l'estrazione delle feature, un insieme di anchor box viene posizionato su queste feature map, variando per dimensione e rapporto d'aspetto. La scelta delle forme degli anchor box è fondamentale e richiede un equilibrio tra il rilevamento di oggetti piccoli e grandi.
Per definire le dimensioni degli anchor box, i modelli utilizzano tipicamente una combinazione di selezione manuale e algoritmi di clustering come K-Means per analizzare il dataset e determinare le forme e dimensioni di oggetti più comuni. Questi anchor box predefiniti vengono poi applicati in diverse posizioni sulle feature map. Ad esempio, un modello di object detection può utilizzare anchor box di dimensioni (16x16), (32x32), (64x64), con rapporti d'aspetto come 1:1, 1:2, and 2:1.
Una volta definiti questi anchor box, essi vengono applicati alle feature map, non all'immagine originale. Il modello assegna più anchor box a ciascuna posizione della feature map, coprendo diverse forme e dimensioni. Durante l'addestramento, la rete regola gli anchor box prevedendo degli offset, perfezionando così la loro dimensione e posizione per adattarsi meglio agli oggetti.
Da Anchor Box a Bounding Box
Una volta che gli anchor box sono assegnati agli oggetti, il modello prevede degli offset per perfezionarli. Questi offset includono:
- Regolazione delle coordinate del centro del box;
- Ridimensionamento della larghezza e dell'altezza;
- Spostamento del box per allinearlo meglio all'oggetto.
Applicando queste trasformazioni, il modello converte gli anchor box in bounding box finali che corrispondono accuratamente agli oggetti in un'immagine.
Approcci che non utilizzano ancore o ne riducono il numero
Sebbene le anchor box siano ampiamente utilizzate, alcuni modelli mirano a ridurne la dipendenza o a eliminarle completamente:
- Metodi anchor-free: modelli come
CenterNeteFCOSprevedono direttamente le posizioni degli oggetti senza ancore predefinite, riducendo la complessità; - Approcci con ancore ridotte:
EfficientDeteYOLOv4ottimizzano il numero di anchor box utilizzate, bilanciando velocità di rilevamento e accuratezza.
Questi approcci puntano a migliorare l'efficienza del rilevamento degli oggetti mantenendo alte prestazioni, in particolare per applicazioni in tempo reale.
In sintesi, le anchor box rappresentano una parte fondamentale del rilevamento degli oggetti, aiutando i modelli a rilevare oggetti in modo efficiente su diverse dimensioni e proporzioni. Tuttavia, i nuovi sviluppi stanno esplorando modi per ridurre o eliminare le anchor box per un rilevamento ancora più rapido e flessibile.
Grazie per i tuoi commenti!
