Panoramica del Modello YOLO
Scorri per mostrare il menu
L'algoritmo YOLO (You Only Look Once) è un modello di rilevamento oggetti rapido ed efficiente. A differenza degli approcci tradizionali come R-CNN che utilizzano più fasi, YOLO elabora l'intera immagine in un unico passaggio, rendendolo ideale per applicazioni in tempo reale.
Come YOLO si differenzia dagli approcci R-CNN
I metodi tradizionali di rilevamento oggetti, come R-CNN e le sue varianti, si basano su una pipeline a due stadi: prima generano proposte di regione, poi classificano ciascuna regione proposta. Sebbene efficace, questo approccio è computazionalmente oneroso e rallenta l'inferenza, rendendolo meno adatto alle applicazioni in tempo reale.
YOLO (You Only Look Once) adotta un approccio radicalmente diverso. Divide l'immagine di input in una griglia e predice bounding box e probabilità di classe per ciascuna cella in un unico passaggio forward. Questo design inquadra il rilevamento oggetti come un unico problema di regressione, consentendo a YOLO di ottenere prestazioni in tempo reale.
A differenza dei metodi basati su R-CNN che si concentrano solo su regioni locali, YOLO elabora l'intera immagine contemporaneamente, permettendo di catturare informazioni contestuali globali. Questo porta a migliori prestazioni nel rilevamento di oggetti multipli o sovrapposti, mantenendo elevata velocità e accuratezza.
Architettura YOLO e Predizioni Basate su Griglia
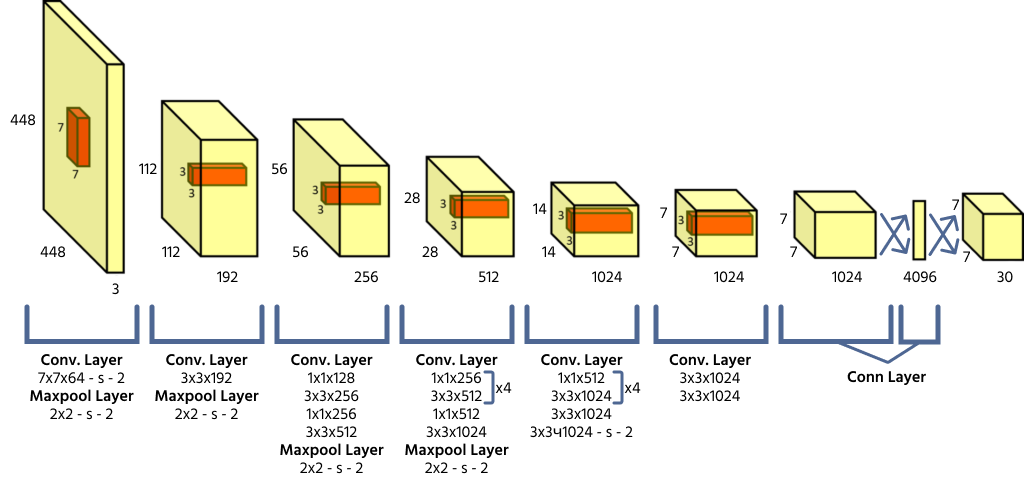
YOLO suddivide un'immagine di input in una griglia S × S, dove ciascuna cella della griglia è responsabile del rilevamento degli oggetti il cui centro ricade al suo interno. Ogni cella predice le coordinate del bounding box (x, y, larghezza, altezza), un punteggio di confidenza dell'oggetto e le probabilità di classe. Poiché YOLO elabora l'intera immagine in un unico passaggio forward, risulta altamente efficiente rispetto ai modelli di rilevamento oggetti precedenti.
Funzione di perdita e punteggi di confidenza delle classi
YOLO ottimizza la precisione del rilevamento utilizzando una funzione di perdita personalizzata, che include:
- Perdita di localizzazione: misura l'accuratezza del riquadro di delimitazione;
- Perdita di confidenza: garantisce che le previsioni indichino correttamente la presenza di oggetti;
- Perdita di classificazione: valuta quanto la classe prevista corrisponde a quella reale.
Per migliorare i risultati, YOLO applica anchor box e soppressione non massima (NMS) per rimuovere rilevamenti ridondanti.
Vantaggi di YOLO: Compromesso tra velocità e accuratezza
Il principale vantaggio di YOLO è la velocità. Poiché il rilevamento avviene in un unico passaggio, YOLO è molto più rapido rispetto ai metodi basati su R-CNN, rendendolo adatto ad applicazioni in tempo reale come la guida autonoma e la videosorveglianza. Tuttavia, le prime versioni di YOLO avevano difficoltà nel rilevamento di oggetti di piccole dimensioni, aspetto migliorato nelle versioni successive.
YOLO: Una Breve Storia
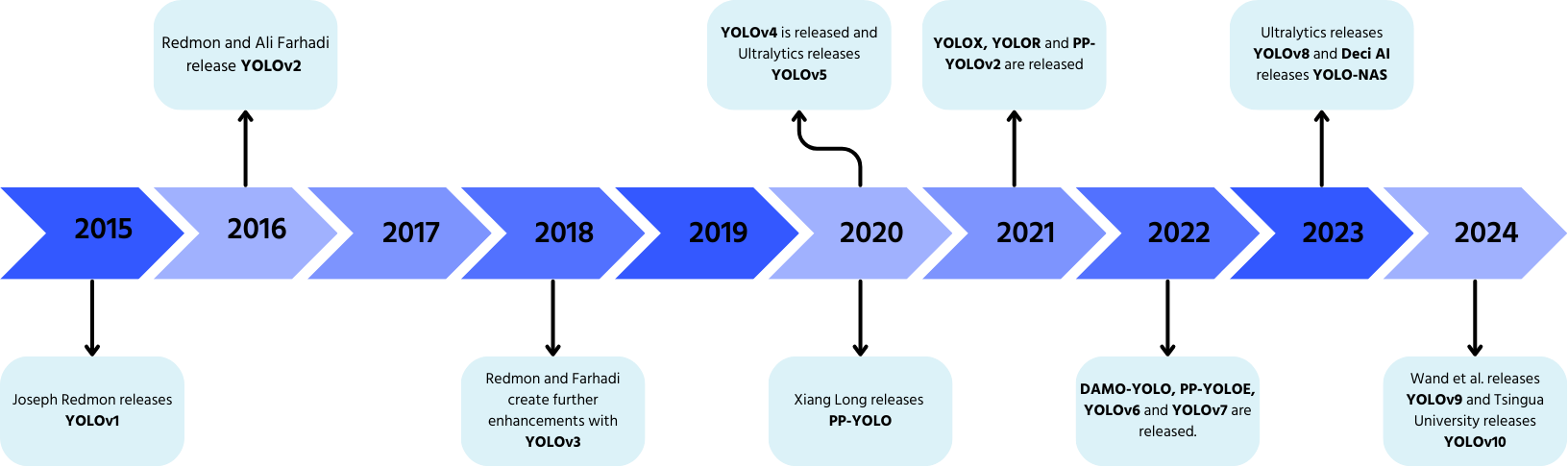
YOLO, sviluppato da Joseph Redmon e Ali Farhadi nel 2015, ha rivoluzionato il rilevamento degli oggetti grazie all'elaborazione in singolo passaggio.
- YOLOv2 (2016): aggiunta della batch normalization, anchor boxes e cluster di dimensioni;
- YOLOv3 (2018): introdotto un backbone più efficiente, anchor multipli e spatial pyramid pooling;
- YOLOv4 (2020): aggiunta della data augmentation Mosaic, una testa di rilevamento anchor-free e una nuova funzione di perdita;
- YOLOv5: miglioramento delle prestazioni tramite ottimizzazione degli iperparametri, tracciamento degli esperimenti e funzionalità di esportazione automatica;
- YOLOv6 (2022): open source da Meituan e utilizzato nei robot per la consegna autonoma;
- YOLOv7: capacità ampliate per includere la stima della posa;
- YOLOv8 (2023): miglioramenti in velocità, flessibilità ed efficienza per i compiti di visione artificiale;
- YOLOv9: introdotti Programmable Gradient Information (PGI) e Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: sviluppato dalla Tsinghua University, elimina la Non-Maximum Suppression (NMS) con una testa di rilevamento End-to-End;
- YOLOv11: il modello più recente che offre prestazioni all'avanguardia in rilevamento oggetti, segmentazione e classificazione.
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
Panoramica del Modello YOLO
L'algoritmo YOLO (You Only Look Once) è un modello di rilevamento oggetti rapido ed efficiente. A differenza degli approcci tradizionali come R-CNN che utilizzano più fasi, YOLO elabora l'intera immagine in un unico passaggio, rendendolo ideale per applicazioni in tempo reale.
Come YOLO si differenzia dagli approcci R-CNN
I metodi tradizionali di rilevamento oggetti, come R-CNN e le sue varianti, si basano su una pipeline a due stadi: prima generano proposte di regione, poi classificano ciascuna regione proposta. Sebbene efficace, questo approccio è computazionalmente oneroso e rallenta l'inferenza, rendendolo meno adatto alle applicazioni in tempo reale.
YOLO (You Only Look Once) adotta un approccio radicalmente diverso. Divide l'immagine di input in una griglia e predice bounding box e probabilità di classe per ciascuna cella in un unico passaggio forward. Questo design inquadra il rilevamento oggetti come un unico problema di regressione, consentendo a YOLO di ottenere prestazioni in tempo reale.
A differenza dei metodi basati su R-CNN che si concentrano solo su regioni locali, YOLO elabora l'intera immagine contemporaneamente, permettendo di catturare informazioni contestuali globali. Questo porta a migliori prestazioni nel rilevamento di oggetti multipli o sovrapposti, mantenendo elevata velocità e accuratezza.
Architettura YOLO e Predizioni Basate su Griglia
YOLO suddivide un'immagine di input in una griglia S × S, dove ciascuna cella della griglia è responsabile del rilevamento degli oggetti il cui centro ricade al suo interno. Ogni cella predice le coordinate del bounding box (x, y, larghezza, altezza), un punteggio di confidenza dell'oggetto e le probabilità di classe. Poiché YOLO elabora l'intera immagine in un unico passaggio forward, risulta altamente efficiente rispetto ai modelli di rilevamento oggetti precedenti.
Funzione di perdita e punteggi di confidenza delle classi
YOLO ottimizza la precisione del rilevamento utilizzando una funzione di perdita personalizzata, che include:
- Perdita di localizzazione: misura l'accuratezza del riquadro di delimitazione;
- Perdita di confidenza: garantisce che le previsioni indichino correttamente la presenza di oggetti;
- Perdita di classificazione: valuta quanto la classe prevista corrisponde a quella reale.
Per migliorare i risultati, YOLO applica anchor box e soppressione non massima (NMS) per rimuovere rilevamenti ridondanti.
Vantaggi di YOLO: Compromesso tra velocità e accuratezza
Il principale vantaggio di YOLO è la velocità. Poiché il rilevamento avviene in un unico passaggio, YOLO è molto più rapido rispetto ai metodi basati su R-CNN, rendendolo adatto ad applicazioni in tempo reale come la guida autonoma e la videosorveglianza. Tuttavia, le prime versioni di YOLO avevano difficoltà nel rilevamento di oggetti di piccole dimensioni, aspetto migliorato nelle versioni successive.
YOLO: Una Breve Storia
YOLO, sviluppato da Joseph Redmon e Ali Farhadi nel 2015, ha rivoluzionato il rilevamento degli oggetti grazie all'elaborazione in singolo passaggio.
- YOLOv2 (2016): aggiunta della batch normalization, anchor boxes e cluster di dimensioni;
- YOLOv3 (2018): introdotto un backbone più efficiente, anchor multipli e spatial pyramid pooling;
- YOLOv4 (2020): aggiunta della data augmentation Mosaic, una testa di rilevamento anchor-free e una nuova funzione di perdita;
- YOLOv5: miglioramento delle prestazioni tramite ottimizzazione degli iperparametri, tracciamento degli esperimenti e funzionalità di esportazione automatica;
- YOLOv6 (2022): open source da Meituan e utilizzato nei robot per la consegna autonoma;
- YOLOv7: capacità ampliate per includere la stima della posa;
- YOLOv8 (2023): miglioramenti in velocità, flessibilità ed efficienza per i compiti di visione artificiale;
- YOLOv9: introdotti Programmable Gradient Information (PGI) e Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: sviluppato dalla Tsinghua University, elimina la Non-Maximum Suppression (NMS) con una testa di rilevamento End-to-End;
- YOLOv11: il modello più recente che offre prestazioni all'avanguardia in rilevamento oggetti, segmentazione e classificazione.
Grazie per i tuoi commenti!
