Rilevamento Oggetti
Scorri per mostrare il menu
Rilevamento degli oggetti rappresenta un progresso fondamentale rispetto alla classificazione e localizzazione delle immagini. Mentre la classificazione determina quale oggetto è presente in un'immagine e la localizzazione identifica dove si trova un singolo oggetto, il rilevamento degli oggetti amplia queste capacità riconoscendo più oggetti e le loro posizioni all'interno di un'immagine.
Cosa rende diverso il rilevamento degli oggetti?
A differenza della classificazione, che assegna un'unica etichetta all'intera immagine, il rilevamento degli oggetti coinvolge sia la classificazione che la localizzazione di più oggetti. Un modello di rilevamento deve prevedere i riquadri di delimitazione attorno a ciascun oggetto e classificarli correttamente. Questo rende il rilevamento degli oggetti un compito più complesso e computazionalmente intensivo rispetto alla semplice classificazione.

Approccio Sliding Window e le sue Limitazioni
Un metodo tradizionale per il rilevamento degli oggetti è l'approccio sliding window, in cui una finestra di dimensioni fisse si sposta sull'immagine per classificare ciascuna sezione. Sebbene sia concettualmente semplice, presenta diverse limitazioni:
- Computazionalmente oneroso: richiede la scansione dell'immagine a molteplici scale e posizioni, comportando tempi di elaborazione elevati;
- Dimensioni della finestra rigide: gli oggetti variano per dimensione e rapporto d'aspetto, rendendo le finestre di dimensioni fisse inefficienti;
- Calcoli ridondanti: le finestre sovrapposte elaborano ripetutamente regioni simili dell'immagine, sprecando risorse.
A causa di queste inefficienze, i metodi di rilevamento oggetti basati sul deep learning hanno in gran parte sostituito l'approccio sliding window.

Metodi Basati su Regione: Selective Search e Region Proposal Networks (RPN)
Per migliorare l'efficienza, i metodi basati su regione propongono Region of Interest (RoI) invece di scansionare l'intera immagine. Due tecniche principali sono:
-
Selective search: un approccio tradizionale che raggruppa pixel simili in proposte di regione, riducendo il numero di predizioni dei bounding box. Sebbene più efficiente degli sliding window, risulta comunque lento;
-
Region proposal networks (RPN): utilizzate in Faster R-CNN, le RPN impiegano una rete neurale per generare direttamente le regioni potenzialmente contenenti oggetti, migliorando notevolmente velocità e accuratezza rispetto alla selective search.
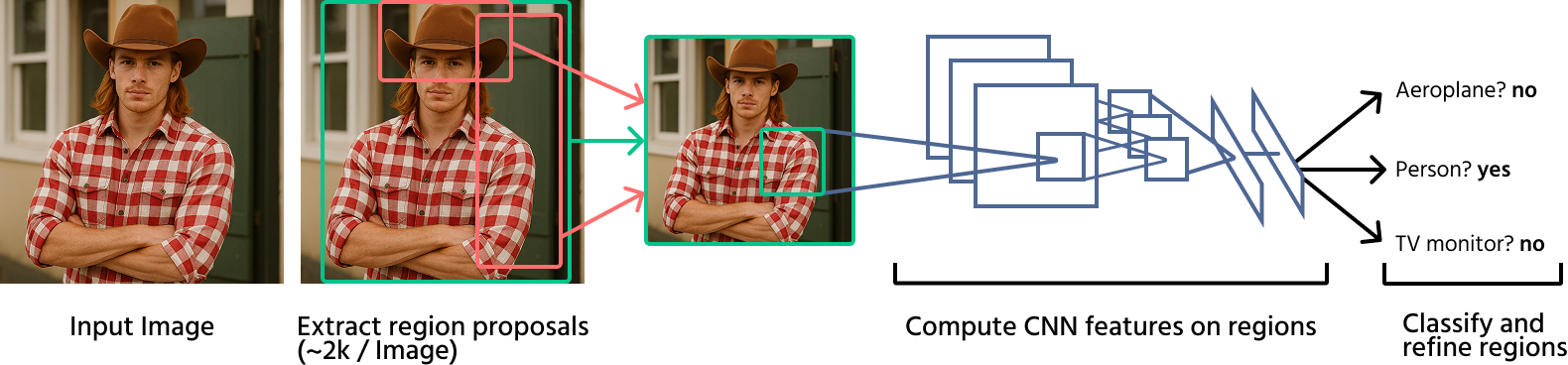
Prime Approcci Basati sul Deep Learning
Il deep learning ha rivoluzionato il rilevamento degli oggetti introducendo le reti neurali convoluzionali (CNN) nei processi di rilevamento. Alcuni dei modelli pionieristici includono:
-
R-CNN (Regions with CNNs): questo metodo applica una CNN a ciascuna proposta di regione generata tramite ricerca selettiva. Sebbene sia significativamente più accurato rispetto ai metodi tradizionali, risulta computazionalmente lento a causa delle ripetute valutazioni della CNN;
-
Fast R-CNN: miglioramento rispetto a R-CNN, questo modello elabora prima l'intera immagine con una CNN e poi applica il RoI pooling per estrarre le caratteristiche per la classificazione, accelerando il rilevamento;
-
Faster R-CNN: introduce le reti di proposta di regione (RPN) per sostituire la ricerca selettiva, rendendo il rilevamento degli oggetti più veloce e accurato integrando la generazione delle proposte di regione direttamente nella rete neurale.
Il rilevamento degli oggetti si basa sulla classificazione e localizzazione, consentendo ai modelli di riconoscere più oggetti all'interno di un'immagine. I metodi tradizionali come le finestre scorrevoli sono stati sostituiti da tecniche basate su regioni più efficienti, come R-CNN e i suoi successori. Faster R-CNN, grazie all'utilizzo delle reti di proposta di regione, rappresenta un passo significativo verso il rilevamento di oggetti in tempo reale e ad alta precisione. In seguito, tecniche più avanzate come YOLO e SSD perfezioneranno ulteriormente la velocità e l'efficienza del rilevamento.
1. Qual è il principale vantaggio di Faster R-CNN rispetto a Fast R-CNN?
2. Perché l'approccio della finestra mobile è inefficiente per il rilevamento degli oggetti?
3. Quale delle seguenti è un metodo di rilevamento oggetti basato sul deep learning?
Grazie per i tuoi commenti!
Chieda ad AI
Chieda ad AI

Chieda pure quello che desidera o provi una delle domande suggerite per iniziare la nostra conversazione
