画像生成の概要
メニューを表示するにはスワイプしてください
AI生成画像は、アート、デザイン、デジタルコンテンツの制作方法を変革しています。人工知能の力により、コンピュータは現実的な画像を作成し、創造的な作業を向上させ、さらにはビジネスにも貢献しています。本章では、AIがどのように画像を生成するのか、さまざまな画像生成モデルの種類、そしてそれらが実際にどのように活用されているかについて解説します。
AIによる画像生成の仕組み
AIによる画像生成は、大量の画像データから学習することで実現されます。AIは画像内のパターンを解析し、それに似た新しい画像を生成します。この技術は年々進化しており、より現実的で創造的な画像を作成できるようになっています。現在では、ビデオゲーム、映画、広告、ファッションなど幅広い分野で利用されています。
初期の手法:PixelRNNとPixelCNN
現在の高度なAIモデルが登場する以前、研究者たちはPixelRNNやPixelCNNといった初期の画像生成手法を開発しました。これらのモデルは、1ピクセルずつ予測しながら画像を生成します。
- PixelRNN:リカレントニューラルネットワーク(RNN)と呼ばれる仕組みを用いて、ピクセルの色を順番に予測します。精度は高いものの、処理速度が非常に遅いという課題がありました。
- PixelCNN:PixelRNNを改良し、畳み込み層という異なるネットワーク構造を採用することで、画像生成の速度を向上させました。
これらのモデルは良い出発点となりましたが、高品質な画像生成には限界がありました。そのため、より優れた手法の開発へとつながりました。
自回帰モデル
自回帰モデルは、過去のピクセルを利用して次に来るピクセルを予測しながら、画像を1ピクセルずつ生成する手法。これらのモデルは有用であったが、処理速度が遅いため、次第にあまり使われなくなった。しかし、より新しく高速なモデルの発展に影響を与えた。
画像生成におけるAIによるテキスト理解
一部のAIモデルは、文章を画像に変換することができる。これらのモデルは**大規模言語モデル(LLM)**を用いて説明文を理解し、それに合った画像を生成する。たとえば「夕焼けのビーチに座る猫」と入力すると、AIはその説明に基づいた画像を作成する。
OpenAIのDALL-EやGoogleのImagenのようなAIモデルは、高度な言語理解によって、テキストの説明と生成される画像の一致度を向上させている。これは**自然言語処理(NLP)**によって実現されており、AIが単語を数値に変換し、それが画像生成の指針となる。
敵対的生成ネットワーク(GAN)
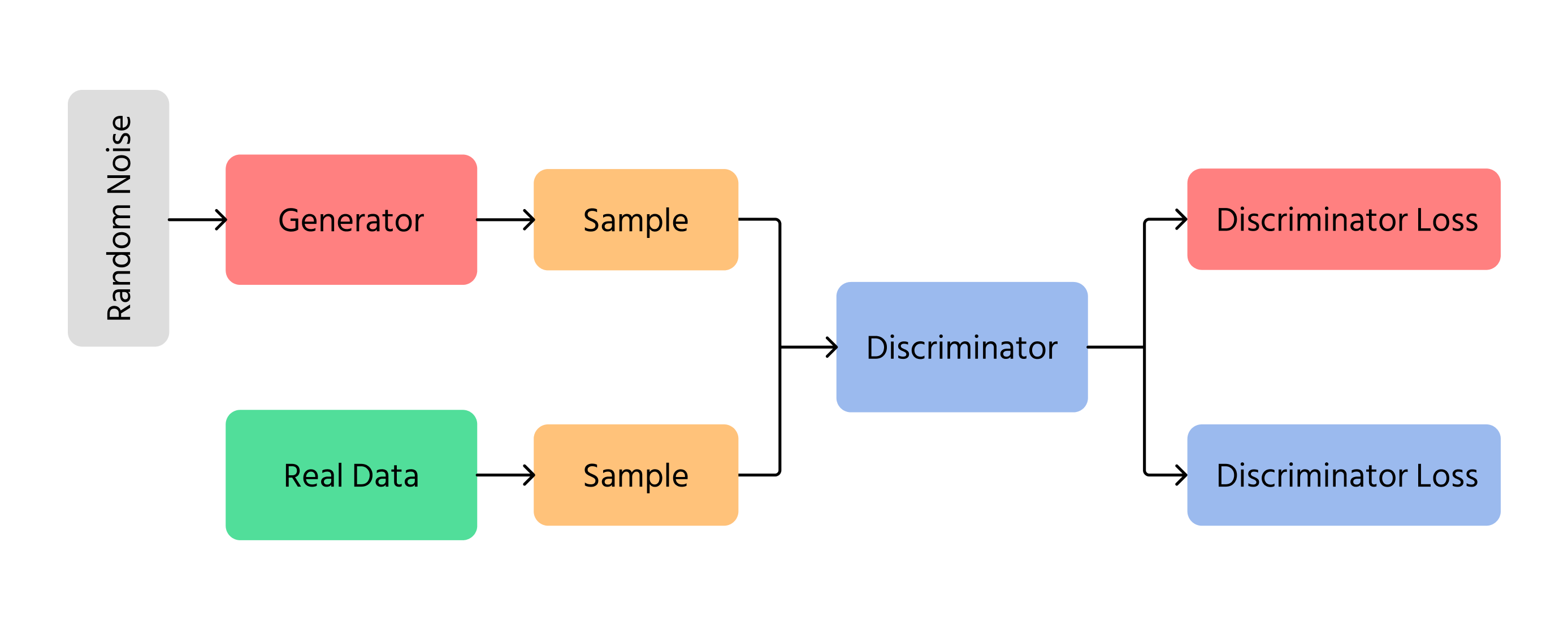
AIによる画像生成の分野で最も重要なブレークスルーの一つが敵対的生成ネットワーク(GAN)。GANは2つの異なるニューラルネットワークを用いる:
- ジェネレーター:ゼロから新しい画像を生成する;
- ディスクリミネーター:画像が本物か偽物かを判定する。
ジェネレーターは、ディスクリミネーターが偽物と見抜けないほどリアルな画像を作ろうとする。これを繰り返すことで、画像は徐々に本物の写真のように精度が高くなる。GANはディープフェイク技術、アート作品の生成、画像品質の向上などに利用されている。
変分オートエンコーダ(VAE)
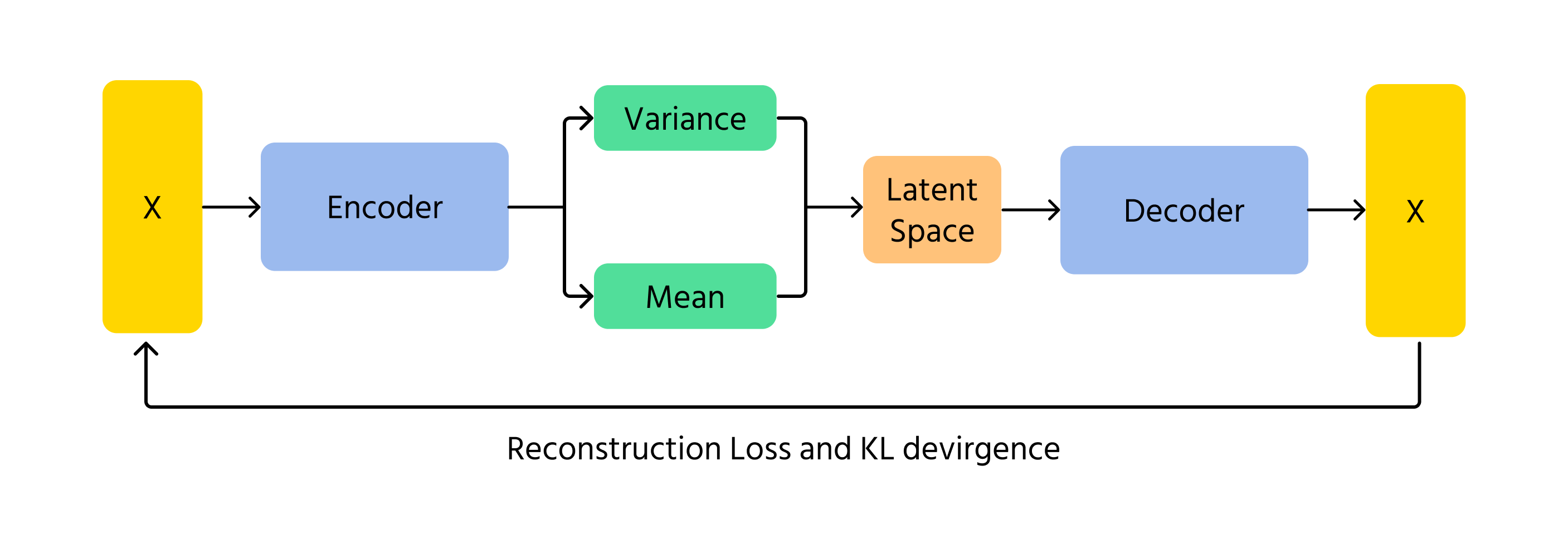
VAEは、AIが画像を生成するもう一つの方法。GANのような競争ではなく、VAEは確率を用いて画像をエンコードおよびデコードする。画像内の基礎的なパターンを学習し、それをわずかに変化させて再構成する仕組み。VAEの確率的要素により、生成される各画像は少しずつ異なり、多様性と創造性が加わる。
VAE(変分オートエンコーダ)における重要な概念は、カルバック・ライブラー(KL)ダイバージェンスであり、これは学習された分布と標準正規分布との差異を測定する指標。 KLダイバージェンスを最小化することで、VAEは生成される画像が現実的でありながらも多様なバリエーションを持つことを保証。
VAEの仕組み
- エンコーディング:入力データxをエンコーダに入力し、潜在空間分布**q(z∣x)(平均μと分散σ²)**のパラメータを出力;
- 潜在空間サンプリング:zをq(z∣x)からリパラメータ化トリックなどの手法でサンプリング;
- デコーディングと再構成:サンプリングしたzをデコーダに通し、再構成データx̂を生成。これは元の入力xと類似している必要がある。
VAEは顔画像の再構成、既存画像の新バージョン生成、異なる画像間のスムーズな遷移などのタスクに有用。
拡散モデル
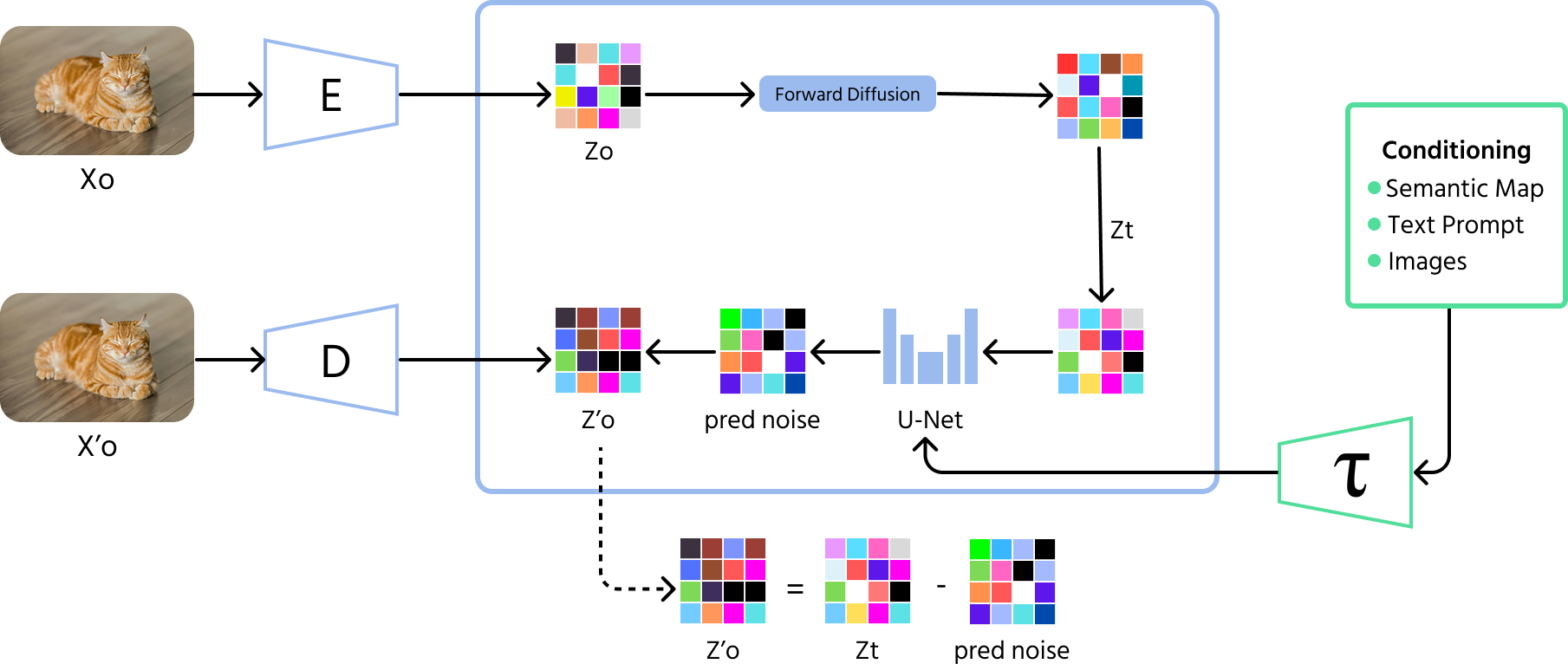
拡散モデルは、AIによる画像生成分野における最新のブレークスルー。 これらのモデルはランダムノイズから始まり、写真のノイズを徐々に消していくように、段階的に画像を洗練。 GANとは異なり、拡散モデルはより幅広く高品質な画像バリエーションを生成可能。
拡散モデルの仕組み
- 順方向プロセス(ノイズ付加):モデルは画像にランダムなノイズを何度も加え、最終的に判別できない状態にする。
- 逆方向プロセス(ノイズ除去):モデルはこのプロセスを逆にたどる方法を学習し、ノイズを段階的に除去して意味のある画像を復元する。
- 学習:拡散モデルは各ステップでノイズを予測・除去するように訓練され、ランダムノイズから鮮明で高品質な画像を生成できるようになる。
代表的な例として、MidJourney、DALL-E、Stable Diffusionがあり、リアルかつ芸術的な画像生成で知られている。拡散モデルはAIによるアート生成、高解像度画像合成、クリエイティブデザイン分野で広く利用されている。
拡散モデルによって生成された画像の例

地獄で行われるバスケットボールの試合で、黄色と紫のユニフォームを着たひげのあるバスケットボール選手がダンクシュートを決め、悪魔たちを打ち負かすリアルな画像。

白い1990年式フォルクスワーゲン・ゴルフGTIが、果てしなく続く白い花畑の中、自然と調和しながら無限の丘に囲まれた場所にあるという、シュールで美しい芸術的な写真。ボタニカル、自然光、芸術的、霧やもやのあるフォトリアリスティックな超高精細、コダックフィルム、自然光、広角レンズ、f1.20。

フェアフィールド・ポーター風、抽象表現主義、ベージュの背景に大胆な筆致で描かれた、緑色のソファの上に緑と白のストライプの枕とともに横たわるベージュのプードル犬の絵画

地中海系またはラテン系女性の肌を極端にクローズアップし、額や鼻に見られる皮脂によるテカリと、頬の乾燥やわずかなフレーク状の質感が混在するコンビネーション肌タイプを強調。Tゾーンでは毛穴がより目立ち、皮脂分泌による自然な輝きが見られる。肌は温かみのあるゴールド系のアンダートーンが混ざり、部位ごとの水分量の違いによる質感のムラがある。柔らかな自然光が乾燥部分とオイリー部分のリアルなコントラストを際立たせている。背景はぼかされており、肌の質感に注目が集まる。
課題と倫理的懸念
AI生成画像は非常に優れていますが、いくつかの課題があります。
- 制御の難しさ:AIは必ずしもユーザーの意図通りの画像を生成できるとは限らない;
- 計算資源の必要性:高品質なAI画像の生成には高価で高性能なコンピュータが必要;
- AIモデルのバイアス:AIは既存の画像から学習するため、データに含まれるバイアスを繰り返すことがある。
また、倫理的懸念も存在します。
- AIアートの所有権:AIが作品を生成した場合、その作品の所有権はAIを使った人にあるのか、それともAI企業にあるのか?
- 偽画像やディープフェイク:GANsは本物のように見える偽画像を作成でき、誤情報やプライバシー問題につながる可能性がある。
AI画像生成の現代での活用例
AI生成画像はすでにさまざまな業界で大きな影響を与えています。
- エンターテインメント:ビデオゲーム、映画、アニメーションで背景やキャラクター、エフェクトの作成にAIを活用;
- ファッション:デザイナーが新しい服のスタイルを作成したり、オンラインストアでバーチャル試着を提供;
- グラフィックデザイン:アーティストやデザイナーがロゴ、ポスター、マーケティング素材を迅速に作成するのにAIが役立つ。
AI画像生成の未来
AI画像生成技術の進化により、人々の画像の作成や利用方法が今後も変化し続けます。アート、ビジネス、エンターテインメントなど、さまざまな分野でAIは新たな可能性を切り開き、創造的な作業をより簡単かつ魅力的にしています。
1. AI画像生成の主な目的は何ですか?
2. 敵対的生成ネットワーク(GAN)はどのように機能しますか?
3. どのAIモデルがランダムノイズから始まり、段階的に画像を改善しますか?
フィードバックありがとうございます!
AIに質問する
AIに質問する

何でも質問するか、提案された質問の1つを試してチャットを始めてください
画像生成の概要
AI生成画像は、アート、デザイン、デジタルコンテンツの制作方法を変革しています。人工知能の力により、コンピュータは現実的な画像を作成し、創造的な作業を向上させ、さらにはビジネスにも貢献しています。本章では、AIがどのように画像を生成するのか、さまざまな画像生成モデルの種類、そしてそれらが実際にどのように活用されているかについて解説します。
AIによる画像生成の仕組み
AIによる画像生成は、大量の画像データから学習することで実現されます。AIは画像内のパターンを解析し、それに似た新しい画像を生成します。この技術は年々進化しており、より現実的で創造的な画像を作成できるようになっています。現在では、ビデオゲーム、映画、広告、ファッションなど幅広い分野で利用されています。
初期の手法:PixelRNNとPixelCNN
現在の高度なAIモデルが登場する以前、研究者たちはPixelRNNやPixelCNNといった初期の画像生成手法を開発しました。これらのモデルは、1ピクセルずつ予測しながら画像を生成します。
- PixelRNN:リカレントニューラルネットワーク(RNN)と呼ばれる仕組みを用いて、ピクセルの色を順番に予測します。精度は高いものの、処理速度が非常に遅いという課題がありました。
- PixelCNN:PixelRNNを改良し、畳み込み層という異なるネットワーク構造を採用することで、画像生成の速度を向上させました。
これらのモデルは良い出発点となりましたが、高品質な画像生成には限界がありました。そのため、より優れた手法の開発へとつながりました。
自回帰モデル
自回帰モデルは、過去のピクセルを利用して次に来るピクセルを予測しながら、画像を1ピクセルずつ生成する手法。これらのモデルは有用であったが、処理速度が遅いため、次第にあまり使われなくなった。しかし、より新しく高速なモデルの発展に影響を与えた。
画像生成におけるAIによるテキスト理解
一部のAIモデルは、文章を画像に変換することができる。これらのモデルは**大規模言語モデル(LLM)**を用いて説明文を理解し、それに合った画像を生成する。たとえば「夕焼けのビーチに座る猫」と入力すると、AIはその説明に基づいた画像を作成する。
OpenAIのDALL-EやGoogleのImagenのようなAIモデルは、高度な言語理解によって、テキストの説明と生成される画像の一致度を向上させている。これは**自然言語処理(NLP)**によって実現されており、AIが単語を数値に変換し、それが画像生成の指針となる。
敵対的生成ネットワーク(GAN)
AIによる画像生成の分野で最も重要なブレークスルーの一つが敵対的生成ネットワーク(GAN)。GANは2つの異なるニューラルネットワークを用いる:
- ジェネレーター:ゼロから新しい画像を生成する;
- ディスクリミネーター:画像が本物か偽物かを判定する。
ジェネレーターは、ディスクリミネーターが偽物と見抜けないほどリアルな画像を作ろうとする。これを繰り返すことで、画像は徐々に本物の写真のように精度が高くなる。GANはディープフェイク技術、アート作品の生成、画像品質の向上などに利用されている。
変分オートエンコーダ(VAE)
VAEは、AIが画像を生成するもう一つの方法。GANのような競争ではなく、VAEは確率を用いて画像をエンコードおよびデコードする。画像内の基礎的なパターンを学習し、それをわずかに変化させて再構成する仕組み。VAEの確率的要素により、生成される各画像は少しずつ異なり、多様性と創造性が加わる。
VAE(変分オートエンコーダ)における重要な概念は、カルバック・ライブラー(KL)ダイバージェンスであり、これは学習された分布と標準正規分布との差異を測定する指標。 KLダイバージェンスを最小化することで、VAEは生成される画像が現実的でありながらも多様なバリエーションを持つことを保証。
VAEの仕組み
- エンコーディング:入力データxをエンコーダに入力し、潜在空間分布**q(z∣x)(平均μと分散σ²)**のパラメータを出力;
- 潜在空間サンプリング:zをq(z∣x)からリパラメータ化トリックなどの手法でサンプリング;
- デコーディングと再構成:サンプリングしたzをデコーダに通し、再構成データx̂を生成。これは元の入力xと類似している必要がある。
VAEは顔画像の再構成、既存画像の新バージョン生成、異なる画像間のスムーズな遷移などのタスクに有用。
拡散モデル
拡散モデルは、AIによる画像生成分野における最新のブレークスルー。 これらのモデルはランダムノイズから始まり、写真のノイズを徐々に消していくように、段階的に画像を洗練。 GANとは異なり、拡散モデルはより幅広く高品質な画像バリエーションを生成可能。
拡散モデルの仕組み
- 順方向プロセス(ノイズ付加):モデルは画像にランダムなノイズを何度も加え、最終的に判別できない状態にする。
- 逆方向プロセス(ノイズ除去):モデルはこのプロセスを逆にたどる方法を学習し、ノイズを段階的に除去して意味のある画像を復元する。
- 学習:拡散モデルは各ステップでノイズを予測・除去するように訓練され、ランダムノイズから鮮明で高品質な画像を生成できるようになる。
代表的な例として、MidJourney、DALL-E、Stable Diffusionがあり、リアルかつ芸術的な画像生成で知られている。拡散モデルはAIによるアート生成、高解像度画像合成、クリエイティブデザイン分野で広く利用されている。
拡散モデルによって生成された画像の例
地獄で行われるバスケットボールの試合で、黄色と紫のユニフォームを着たひげのあるバスケットボール選手がダンクシュートを決め、悪魔たちを打ち負かすリアルな画像。
白い1990年式フォルクスワーゲン・ゴルフGTIが、果てしなく続く白い花畑の中、自然と調和しながら無限の丘に囲まれた場所にあるという、シュールで美しい芸術的な写真。ボタニカル、自然光、芸術的、霧やもやのあるフォトリアリスティックな超高精細、コダックフィルム、自然光、広角レンズ、f1.20。
フェアフィールド・ポーター風、抽象表現主義、ベージュの背景に大胆な筆致で描かれた、緑色のソファの上に緑と白のストライプの枕とともに横たわるベージュのプードル犬の絵画
地中海系またはラテン系女性の肌を極端にクローズアップし、額や鼻に見られる皮脂によるテカリと、頬の乾燥やわずかなフレーク状の質感が混在するコンビネーション肌タイプを強調。Tゾーンでは毛穴がより目立ち、皮脂分泌による自然な輝きが見られる。肌は温かみのあるゴールド系のアンダートーンが混ざり、部位ごとの水分量の違いによる質感のムラがある。柔らかな自然光が乾燥部分とオイリー部分のリアルなコントラストを際立たせている。背景はぼかされており、肌の質感に注目が集まる。
課題と倫理的懸念
AI生成画像は非常に優れていますが、いくつかの課題があります。
- 制御の難しさ:AIは必ずしもユーザーの意図通りの画像を生成できるとは限らない;
- 計算資源の必要性:高品質なAI画像の生成には高価で高性能なコンピュータが必要;
- AIモデルのバイアス:AIは既存の画像から学習するため、データに含まれるバイアスを繰り返すことがある。
また、倫理的懸念も存在します。
- AIアートの所有権:AIが作品を生成した場合、その作品の所有権はAIを使った人にあるのか、それともAI企業にあるのか?
- 偽画像やディープフェイク:GANsは本物のように見える偽画像を作成でき、誤情報やプライバシー問題につながる可能性がある。
AI画像生成の現代での活用例
AI生成画像はすでにさまざまな業界で大きな影響を与えています。
- エンターテインメント:ビデオゲーム、映画、アニメーションで背景やキャラクター、エフェクトの作成にAIを活用;
- ファッション:デザイナーが新しい服のスタイルを作成したり、オンラインストアでバーチャル試着を提供;
- グラフィックデザイン:アーティストやデザイナーがロゴ、ポスター、マーケティング素材を迅速に作成するのにAIが役立つ。
AI画像生成の未来
AI画像生成技術の進化により、人々の画像の作成や利用方法が今後も変化し続けます。アート、ビジネス、エンターテインメントなど、さまざまな分野でAIは新たな可能性を切り開き、創造的な作業をより簡単かつ魅力的にしています。
フィードバックありがとうございます!
