Generative Adversarielle Nettverk (GANs)
Sveip for å vise menyen
Generative Adversarial Networks (GANs) er en klasse av generative modeller introdusert av Ian Goodfellow i 2014. De består av to nevrale nettverk — Generatoren og Diskriminatoren — som trenes samtidig i et spillteoretisk rammeverk. Generatoren forsøker å produsere data som ligner på ekte data, mens diskriminatoren prøver å skille ekte data fra generert data.
GANs lærer å generere datasett fra støy ved å løse et minimaks-spill. I løpet av treningen blir generatoren bedre til å produsere realistiske data, og diskriminatoren blir bedre til å skille mellom ekte og falske data.
Arkitektur for en GAN
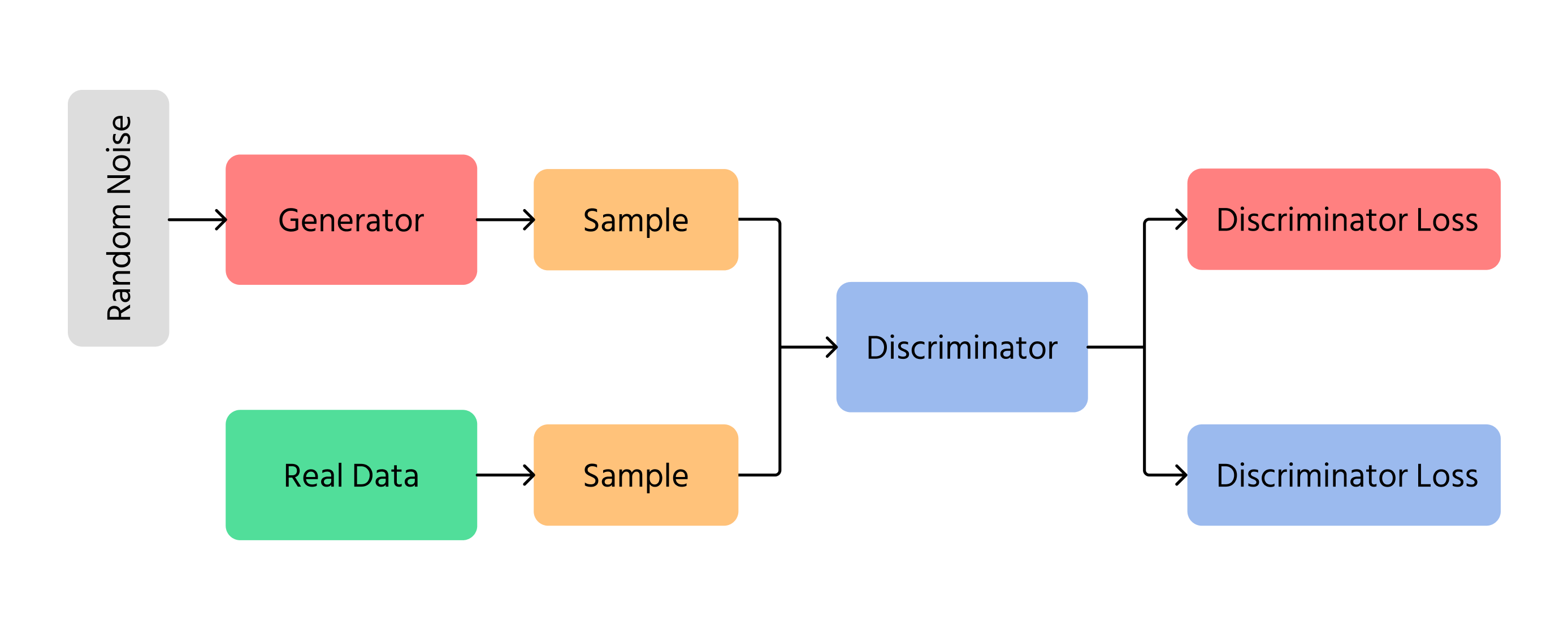
En grunnleggende GAN-modell består av to kjernekomponenter:
1. Generator (G)
- Tar en tilfeldig støyvektor z∼pz(z) som input;
- Transformerer denne gjennom et nevralt nettverk til et datasample G(z) som skal ligne på data fra den sanne fordelingen.
2. Discriminator (D)
- Tar enten et ekte datasample x∼px(x) eller et generert sample G(z);
- Gir ut en skalar mellom 0 og 1, som estimerer sannsynligheten for at inputen er ekte.
Disse to komponentene trenes samtidig. Generatoren har som mål å produsere realistiske eksempler for å lure diskriminatoren, mens diskriminatoren har som mål å korrekt identifisere ekte versus genererte eksempler.
Minimax-spillet i GANs
Kjernen i GANs er minimax-spillet, et begrep fra spillteori. I denne oppstillingen:
- Generatoren G og diskriminatoren D er konkurrerende aktører;
- D har som mål å maksimere sin evne til å skille mellom ekte og genererte data;
- G har som mål å minimere D sin evne til å oppdage dens falske data.
Denne dynamikken definerer et nullsumspill, der én aktørs gevinst er den andres tap. Optimaliseringen er definert som:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Generatoren forsøker å lure diskriminatoren ved å generere eksempler G(z) som er så nær ekte data som mulig.
Tapfunksjoner
Selv om det opprinnelige GAN-målet definerer et minimax-spill, brukes alternative tapfunksjoner i praksis for å stabilisere treningen.
- Ikke-metnings generator-tap:
Dette hjelper generatoren å motta sterke gradienter selv når diskriminatoren presterer godt.
- Diskriminator-tap:
Disse tapene oppmuntrer generatoren til å produsere eksempler som øker diskriminatorens usikkerhet og forbedrer konvergensen under trening.
Viktige varianter av GAN-arkitekturer
Flere typer GANs har oppstått for å håndtere spesifikke begrensninger eller for å forbedre ytelsen:

Betinget GAN (cGAN)
Betingede GAN-er utvider det standard GAN-rammeverket ved å introdusere tilleggsinformasjon (vanligvis etiketter) i både generatoren og diskriminatoren. I stedet for å generere data kun fra tilfeldig støy, mottar generatoren både støy z og en betingelse y (f.eks. en klasseetikett). Diskriminatoren mottar også y for å vurdere om eksempelet er realistisk under den betingelsen.
- Bruksområder: klassebetinget bildegenerering, bilde-til-bilde-oversettelse, tekst-til-bilde-generering.
Dyp Konvolusjonell GAN (DCGAN)
DCGAN-er erstatter de fullt tilkoblede lagene i de opprinnelige GAN-ene med konvolusjons- og transponerte konvolusjonslag, noe som gjør dem mer effektive for bildegenerering. De introduserer også arkitektoniske retningslinjer som å fjerne fullt tilkoblede lag, bruke batch-normalisering og benytte ReLU/LeakyReLU-aktiveringer.
- Bruksområder: fotorealistisk bildegenerering, læring av visuelle representasjoner, usupervised egenskapslæring.
CycleGAN CycleGAN løser problemet med bilde-til-bilde-oversettelse uten parvise datasett. I motsetning til andre modeller som krever parvise datasett (for eksempel det samme bildet i to ulike stiler), kan CycleGAN lære sammenhenger mellom to domener uten parvise eksempler. Modellen introduserer to generatorer og to diskriminatorer, hvor hver er ansvarlig for å mappe i én retning (for eksempel fra foto til maleri og omvendt), og benytter et sykluskonsistens-tap for å sikre at oversettelse fra ett domene og tilbake gir det opprinnelige bildet. Dette tapet er avgjørende for å bevare innhold og struktur.
Sykluskonsistens-tap sikrer:
GBA(GAB(x))≈x og GAB(GBA(y))≈yhvor:
- GAB mapper bilder fra domene A til domene B;
- GBA mapper fra domene B til domene A.
- x∈A,y∈B.
Bruksområder: konvertering fra foto til kunstverk, oversettelse fra hest til sebra, stemmekonvertering mellom talere.
StyleGAN
StyleGAN, utviklet av NVIDIA, introduserer stilbasert kontroll i generatoren. I stedet for å sende en støyvektor direkte til generatoren, går den gjennom et kartleggingsnettverk for å produsere "stilvektorer" som påvirker hvert lag i generatoren. Dette gir detaljert kontroll over visuelle egenskaper som hårfarge, ansiktsuttrykk eller belysning.
Viktige innovasjoner:
- Stilblanding, som gjør det mulig å kombinere flere latente koder;
- Adaptive Instance Normalization (AdaIN), styrer feature maps i generatoren;
- Progressiv økning, der treningen starter med lav oppløsning og øker over tid.
Bruksområder: generering av bilder med svært høy oppløsning (for eksempel ansikter), kontroll over visuelle attributter, kunstgenerering.
Sammenligning: GANs vs VAEs
GAN-er er en kraftig klasse av generative modeller som kan produsere svært realistiske data gjennom en adversariell treningsprosess. Kjernen består av et minimax-spill mellom to nettverk, hvor adversarielle tap brukes for å forbedre begge komponentene iterativt. God forståelse av deres arkitektur, tapfunksjoner—inkludert varianter som cGAN, DCGAN, CycleGAN og StyleGAN—og deres kontrast til andre modeller som VAE-er gir et nødvendig grunnlag for anvendelser innen blant annet generering av bilder, videosyntese, datautvidelse og mer.
1. Hvilket av følgende beskriver best komponentene i en grunnleggende GAN-arkitektur?
2. Hva er målet med minimax-spillet i GANs?
3. Hvilket av følgende utsagn er sant om forskjellen mellom GANs og VAEs?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
