Prediksjoner av Avgrensningsbokser
Sveip for å vise menyen
Avgrensningsbokser er avgjørende for objektdeteksjon, og gir en metode for å markere objekters plassering. Objektdeteksjonsmodeller bruker disse boksene til å definere posisjon og dimensjoner for detekterte objekter i et bilde. Nøyaktig prediksjon av avgrensningsbokser er grunnleggende for å sikre pålitelig objektdeteksjon.
Hvordan CNN-er predikerer koordinater for avgrensningsbokser
Konvolusjonelle nevrale nettverk (CNN-er) behandler bilder gjennom lag med konvolusjoner og pooling for å trekke ut egenskaper. For objektdeteksjon genererer CNN-er feature maps som representerer ulike deler av et bilde. Prediksjon av avgrensningsbokser oppnås vanligvis ved:
- Uttrekking av egenskapsrepresentasjoner fra bildet;
- Anvendelse av en regresjonsfunksjon for å predikere koordinater for avgrensningsboksen;
- Klassifisering av de detekterte objektene innenfor hver boks.
Prediksjoner av avgrensningsbokser representeres som numeriske verdier tilsvarende:
- (x, y): koordinatene til sentrum av boksen;
- (w, h): bredden og høyden til boksen.
Eksempel: Prediksjon av avgrensningsbokser ved bruk av forhåndstrent modell
I stedet for å trene et CNN fra bunnen av, kan vi bruke en forhåndstrent modell som Faster R-CNN fra TensorFlows model zoo for å predikere avgrensningsbokser på et bilde. Nedenfor vises et eksempel på hvordan man laster inn en forhåndstrent modell, laster inn et bilde, gjør prediksjoner og visualiserer avgrensningsboksene med klasselabels.
Importer biblioteker
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Last inn modell og bilde
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Forbehandle bildet
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Utfør prediksjon og hent ut egenskaper for avgrensningsbokser
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Tegn avgrensningsbokser
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisering
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultat:

Regresjonsbaserte prediksjoner av avgrensningsbokser
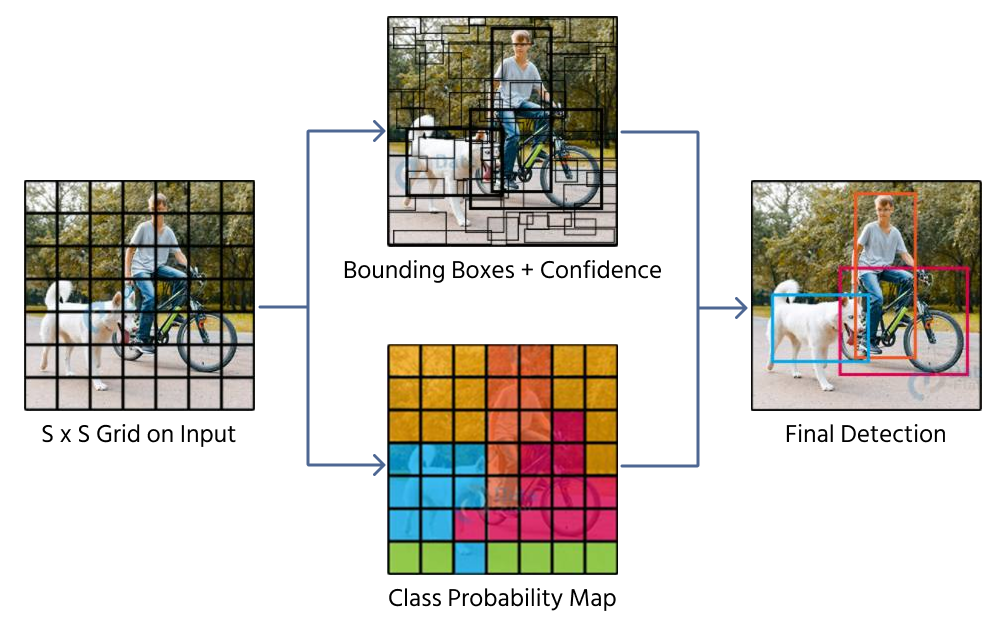
En metode for å predikere avgrensningsbokser er direkte regresjon, hvor et CNN returnerer fire numeriske verdier som representerer boksens posisjon og størrelse. Modeller som YOLO (You Only Look Once) benytter denne teknikken ved å dele et bilde inn i et rutenett og tilordne prediksjoner av avgrensningsbokser til rutenettcellene.
Direkte regresjon har imidlertid begrensninger:
- Vanskelig å håndtere objekter med varierende størrelser og sideforhold;
- Håndterer ikke overlappende objekter effektivt;
- Avgrensningsbokser kan forskyves uforutsigbart, noe som fører til inkonsistens.
Ankerbaserte vs. ankerfrie tilnærminger
Ankerbaserte metoder
Ankerbokser er forhåndsdefinerte avgrensningsbokser med faste størrelser og sideforhold. Modeller som Faster R-CNN og SSD (Single Shot MultiBox Detector) bruker ankerbokser for å forbedre prediksjonsnøyaktigheten. Modellen predikerer justeringer til ankerboksene i stedet for å forutsi avgrensningsbokser fra bunnen av. Denne metoden fungerer godt for å oppdage objekter i ulike skalaer, men øker den beregningsmessige kompleksiteten.
Ankerfrie metoder
Ankerfrie metoder, som CenterNet og FCOS (Fully Convolutional One-Stage Object Detection), eliminerer forhåndsdefinerte ankerbokser og predikerer i stedet objektsentre direkte. Disse metodene gir:
- Enklere modellarkitekturer;
- Raskere inferenshastigheter;
- Bedre generalisering til ukjente objektstørrelser.

A (Anchor-basert): predikerer forskyvninger (grønne linjer) fra forhåndsdefinerte ankre (blå) for å matche fasiten (rød). B (Anchor-fri): estimerer direkte forskyvninger fra et punkt til dets grenser.
Prediksjon av avgrensningsbokser er en sentral komponent i objektdeteksjon, og ulike tilnærminger balanserer nøyaktighet og effektivitet. Mens ankerbaserte metoder forbedrer presisjonen ved å bruke forhåndsdefinerte former, forenkler ankerfrie metoder deteksjonen ved å predikere objektenes plasseringer direkte. Forståelse av disse teknikkene bidrar til å utforme bedre objektdeteksjonssystemer for ulike praktiske bruksområder.
1. Hvilken informasjon inneholder vanligvis en bounding box-forutsigelse?
2. Hva er den primære fordelen med forankringsbaserte metoder i objektdeteksjon?
3. Hvilken utfordring møter direkte regresjon i bounding box-forutsigelse?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Prediksjoner av Avgrensningsbokser
Avgrensningsbokser er avgjørende for objektdeteksjon, og gir en metode for å markere objekters plassering. Objektdeteksjonsmodeller bruker disse boksene til å definere posisjon og dimensjoner for detekterte objekter i et bilde. Nøyaktig prediksjon av avgrensningsbokser er grunnleggende for å sikre pålitelig objektdeteksjon.
Hvordan CNN-er predikerer koordinater for avgrensningsbokser
Konvolusjonelle nevrale nettverk (CNN-er) behandler bilder gjennom lag med konvolusjoner og pooling for å trekke ut egenskaper. For objektdeteksjon genererer CNN-er feature maps som representerer ulike deler av et bilde. Prediksjon av avgrensningsbokser oppnås vanligvis ved:
- Uttrekking av egenskapsrepresentasjoner fra bildet;
- Anvendelse av en regresjonsfunksjon for å predikere koordinater for avgrensningsboksen;
- Klassifisering av de detekterte objektene innenfor hver boks.
Prediksjoner av avgrensningsbokser representeres som numeriske verdier tilsvarende:
- (x, y): koordinatene til sentrum av boksen;
- (w, h): bredden og høyden til boksen.
Eksempel: Prediksjon av avgrensningsbokser ved bruk av forhåndstrent modell
I stedet for å trene et CNN fra bunnen av, kan vi bruke en forhåndstrent modell som Faster R-CNN fra TensorFlows model zoo for å predikere avgrensningsbokser på et bilde. Nedenfor vises et eksempel på hvordan man laster inn en forhåndstrent modell, laster inn et bilde, gjør prediksjoner og visualiserer avgrensningsboksene med klasselabels.
Importer biblioteker
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Last inn modell og bilde
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Forbehandle bildet
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Utfør prediksjon og hent ut egenskaper for avgrensningsbokser
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Tegn avgrensningsbokser
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisering
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultat:
Regresjonsbaserte prediksjoner av avgrensningsbokser
En metode for å predikere avgrensningsbokser er direkte regresjon, hvor et CNN returnerer fire numeriske verdier som representerer boksens posisjon og størrelse. Modeller som YOLO (You Only Look Once) benytter denne teknikken ved å dele et bilde inn i et rutenett og tilordne prediksjoner av avgrensningsbokser til rutenettcellene.
Direkte regresjon har imidlertid begrensninger:
- Vanskelig å håndtere objekter med varierende størrelser og sideforhold;
- Håndterer ikke overlappende objekter effektivt;
- Avgrensningsbokser kan forskyves uforutsigbart, noe som fører til inkonsistens.
Ankerbaserte vs. ankerfrie tilnærminger
Ankerbaserte metoder
Ankerbokser er forhåndsdefinerte avgrensningsbokser med faste størrelser og sideforhold. Modeller som Faster R-CNN og SSD (Single Shot MultiBox Detector) bruker ankerbokser for å forbedre prediksjonsnøyaktigheten. Modellen predikerer justeringer til ankerboksene i stedet for å forutsi avgrensningsbokser fra bunnen av. Denne metoden fungerer godt for å oppdage objekter i ulike skalaer, men øker den beregningsmessige kompleksiteten.
Ankerfrie metoder
Ankerfrie metoder, som CenterNet og FCOS (Fully Convolutional One-Stage Object Detection), eliminerer forhåndsdefinerte ankerbokser og predikerer i stedet objektsentre direkte. Disse metodene gir:
- Enklere modellarkitekturer;
- Raskere inferenshastigheter;
- Bedre generalisering til ukjente objektstørrelser.
A (Anchor-basert): predikerer forskyvninger (grønne linjer) fra forhåndsdefinerte ankre (blå) for å matche fasiten (rød). B (Anchor-fri): estimerer direkte forskyvninger fra et punkt til dets grenser.
Prediksjon av avgrensningsbokser er en sentral komponent i objektdeteksjon, og ulike tilnærminger balanserer nøyaktighet og effektivitet. Mens ankerbaserte metoder forbedrer presisjonen ved å bruke forhåndsdefinerte former, forenkler ankerfrie metoder deteksjonen ved å predikere objektenes plasseringer direkte. Forståelse av disse teknikkene bidrar til å utforme bedre objektdeteksjonssystemer for ulike praktiske bruksområder.
Takk for tilbakemeldingene dine!
