Implementering av Word2Vec
Sveip for å vise menyen
Etter å ha forstått hvordan Word2Vec fungerer, går vi videre til å implementere det ved hjelp av Python. Gensim-biblioteket, et robust åpen kildekode-verktøy for behandling av naturlig språk, tilbyr en enkel implementasjon gjennom sin Word2Vec-klasse i gensim.models.
Forberedelse av data
Word2Vec krever at tekstdataene er tokenisert, det vil si delt opp i en liste av lister hvor hver indre liste inneholder ordene fra en bestemt setning. I dette eksempelet bruker vi romanen Emma av den engelske forfatteren Jane Austen som vårt korpus. Vi laster inn en CSV-fil som inneholder forhåndsprosesserte setninger, og deler deretter hver setning opp i ord:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() anvender .split()-metoden på hver setning i 'Sentence'-kolonnen, noe som resulterer i en liste med ord for hver setning. Siden setningene allerede er forhåndsbehandlet, med ord adskilt av mellomrom, er .split()-metoden tilstrekkelig for denne tokeniseringen.
Trening av Word2Vec-modellen
Nå skal vi fokusere på å trene Word2Vec-modellen ved å bruke de tokeniserte dataene. Word2Vec-klassen tilbyr en rekke parametere for tilpasning. De mest brukte parameterne er:
vector_size(standardverdi 100): dimensjonaliteten eller størrelsen på ordembeddingene;window(standardverdi 5): størrelsen på kontekstvinduet;min_count(standardverdi 5): ord som forekommer færre ganger enn dette blir ignorert;sg(standardverdi 0): modellarkitekturen som skal brukes (1 for Skip-gram, 0 for CBoW).cbow_mean(standardverdi 1): angir om CBoW-inngangskonteksten summeres (0) eller gjennomsnittberegnes (1)
Når det gjelder modellarkitekturer, er CBoW egnet for større datasett og situasjoner der beregningseffektivitet er avgjørende. Skip-gram er derimot å foretrekke for oppgaver som krever detaljert forståelse av ordkontekster, spesielt effektivt i mindre datasett eller når man arbeider med sjeldne ord.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Her setter vi embedding-størrelsen til 200, kontekstvinduet til 5, og inkluderer alle ord ved å sette min_count=1. Ved å sette sg=0, valgte vi å bruke CBoW-modellen.
Valg av riktig embedding-størrelse og kontekstvindu innebærer avveininger. Større embeddinger fanger opp mer mening, men øker beregningskostnadene og risikoen for overtilpasning. Mindre kontekstvinduer er bedre til å fange opp syntaks, mens større er bedre til å fange opp semantikk.
Finne lignende ord
Når ord er representert som vektorer, kan vi sammenligne dem for å måle likhet. Selv om det er mulig å bruke avstand, bærer retningen til en vektor ofte mer semantisk betydning enn størrelsen, spesielt i ord-embedding.
Å bruke en vinkel som likhetsmål er imidlertid ikke så praktisk. I stedet kan vi bruke cosinus til vinkelen mellom to vektorer, også kjent som cosinuslikhet. Den varierer fra -1 til 1, der høyere verdier indikerer sterkere likhet. Denne tilnærmingen fokuserer på hvor godt vektorene er justert, uavhengig av lengde, noe som gjør den ideell for å sammenligne ords betydning. Her er en illustrasjon:
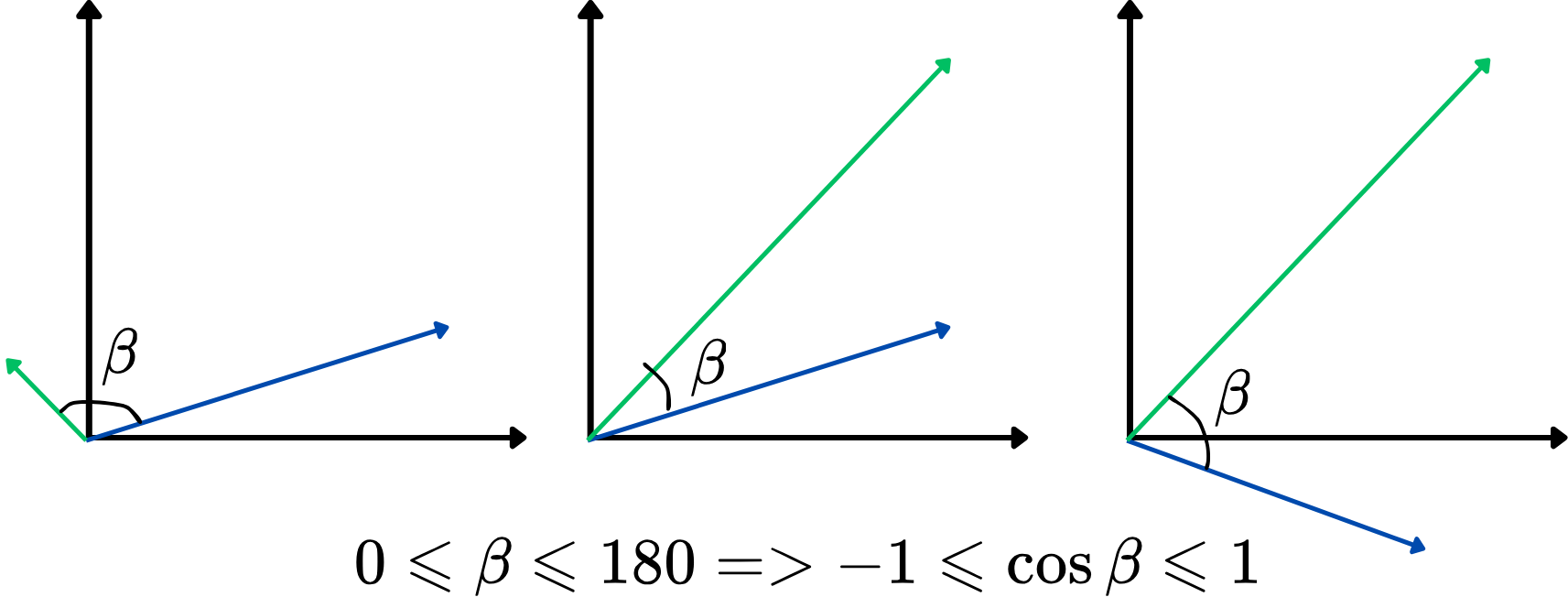
Jo høyere cosinuslikhet, desto mer like er de to vektorene, og omvendt. For eksempel, hvis to ordvektorer har en cosinuslikhet nær 1 (vinkelen nær 0 grader), indikerer det at de er nært beslektet eller like i kontekst innenfor vektorrommet.
La oss nå finne de fem mest like ordene til ordet "man" ved hjelp av cosinuslikhet:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv gir tilgang til ordvektorene i den trente modellen, mens metoden .most_similar() finner ordene hvis embedding er nærmest embedding til det angitte ordet, basert på cosinuslikhet. Parameteren topn bestemmer hvor mange av de N mest like ordene som returneres.
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
