Implementering av nevrale nettverk
Grunnleggende oversikt over nevrale nettverk
Du har nå kommet til et punkt hvor du har den nødvendige kunnskapen om TensorFlow til å lage nevrale nettverk på egen hånd. Selv om de fleste nevrale nettverk i virkeligheten er komplekse og vanligvis bygges med høynivå-biblioteker som Keras, skal vi konstruere et enkelt nettverk ved hjelp av grunnleggende TensorFlow-verktøy. Denne tilnærmingen gir oss praktisk erfaring med lavnivå tensor-manipulering, noe som hjelper oss å forstå de underliggende prosessene.
I tidligere kurs som Introduksjon til nevrale nettverk, husker du kanskje hvor mye tid og arbeid det tok å bygge selv et enkelt nevralt nettverk, der hver nevron ble behandlet individuelt.

TensorFlow forenkler denne prosessen betydelig. Ved å bruke tensorer kan du innkapsle komplekse beregninger, noe som reduserer behovet for innviklet koding. Hovedoppgaven vår er å sette opp en sekvensiell kjede av tensor-operasjoner.
Her er en kort oppsummering av stegene for å få i gang en treningsprosess for et nevralt nettverk:
Datatilrettelegging og modellopprettelse
Den innledende fasen av trening av et nevralt nettverk innebærer tilrettelegging av data, som omfatter både input og output som nettverket skal lære fra. I tillegg fastsettes modellens hyperparametere – dette er parametere som forblir konstante gjennom hele treningsprosessen. Vektene initialiseres, vanligvis trukket fra en normalfordeling, og biasene settes ofte til null.
Fremoverpropagering
I fremoverpropagering følger hvert lag i nettverket vanligvis disse trinnene:
- Multipliser lagets input med dets vekter.
- Legg til en bias til resultatet.
- Bruk en aktiveringsfunksjon på denne summen.
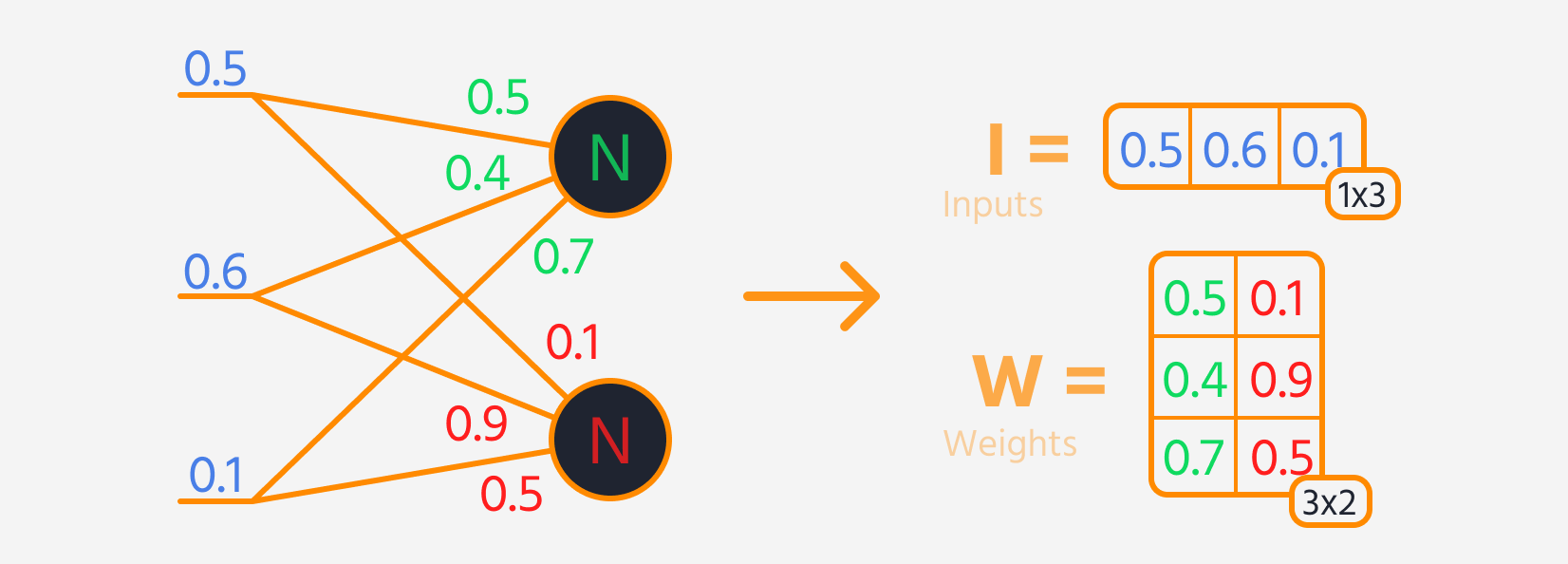
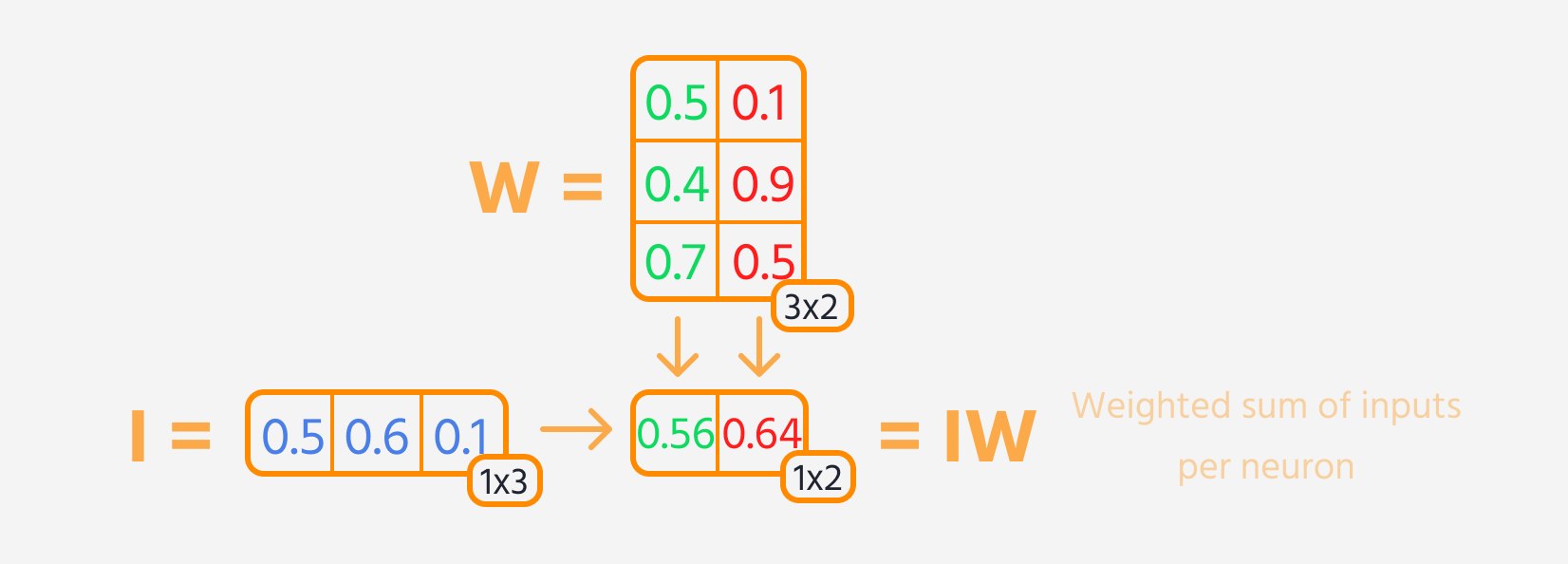
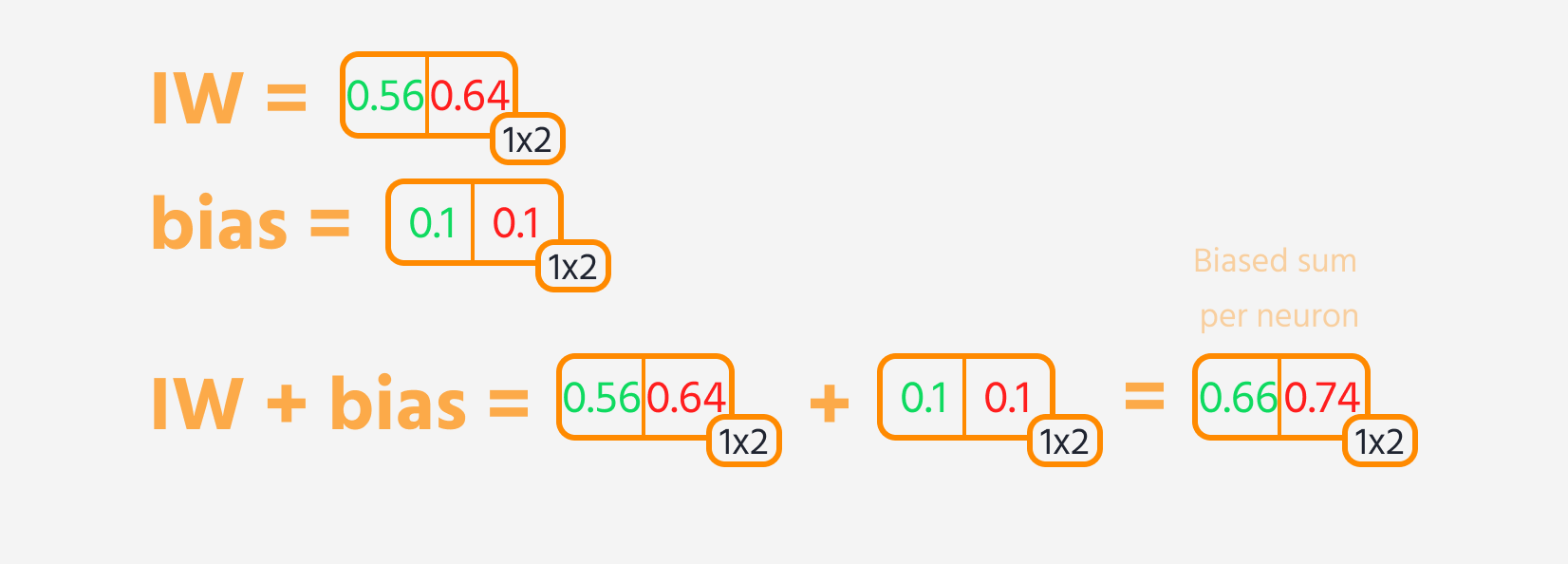


Deretter kan tap beregnes.
Bakoverpropagasjon
Neste steg er bakoverpropagasjon, hvor vekter og biaser justeres basert på deres innflytelse på tapet. Denne innflytelsen representeres av gradienten, som TensorFlows Gradient Tape beregner automatisk. Vektene og biasene oppdateres ved å trekke fra gradienten, skalert med læringsraten.
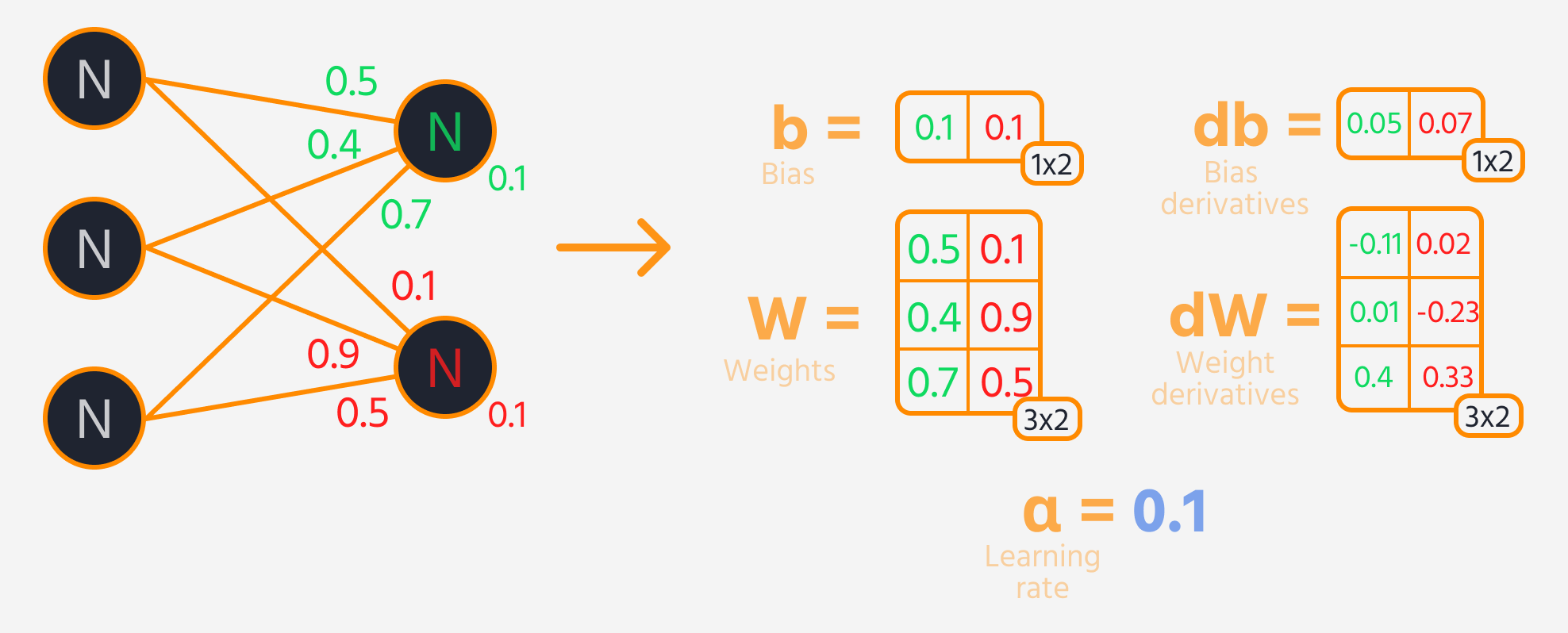
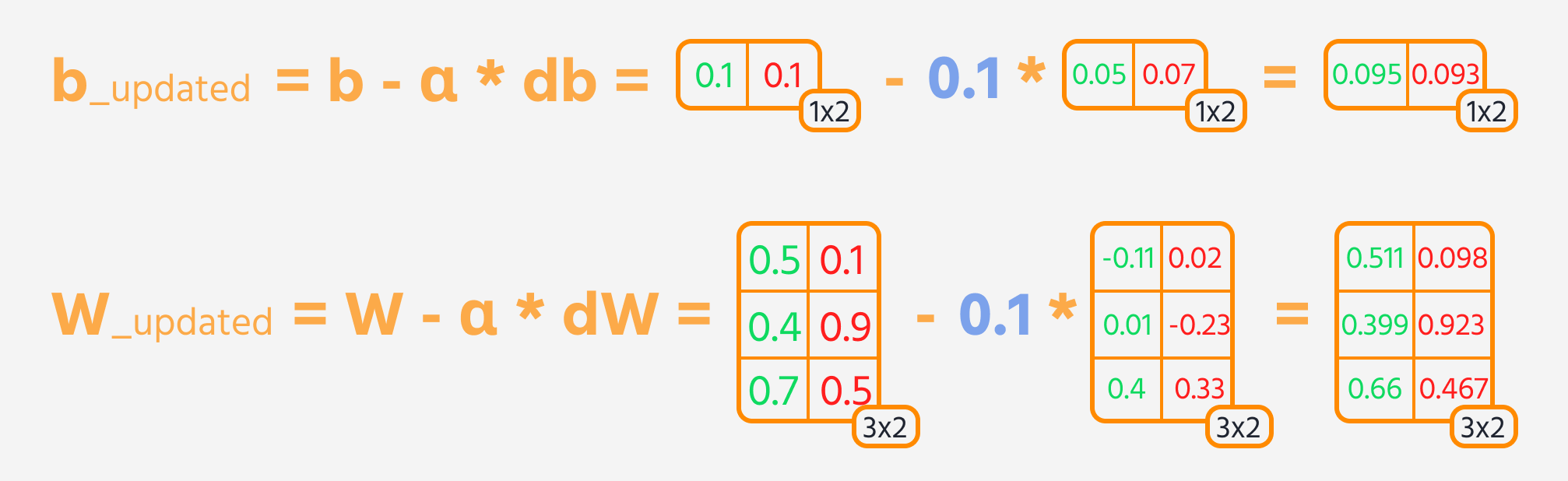
Treningssløyfe
For å trene nevrale nettverk effektivt, gjentas treningsstegene flere ganger mens modellens ytelse overvåkes. Ideelt sett bør tapet reduseres over epoker.
Takk for tilbakemeldingene dine!
single
Implementering av nevrale nettverk
Sveip for å vise menyen
Grunnleggende oversikt over nevrale nettverk
Du har nå kommet til et punkt hvor du har den nødvendige kunnskapen om TensorFlow til å lage nevrale nettverk på egen hånd. Selv om de fleste nevrale nettverk i virkeligheten er komplekse og vanligvis bygges med høynivå-biblioteker som Keras, skal vi konstruere et enkelt nettverk ved hjelp av grunnleggende TensorFlow-verktøy. Denne tilnærmingen gir oss praktisk erfaring med lavnivå tensor-manipulering, noe som hjelper oss å forstå de underliggende prosessene.
I tidligere kurs som Introduksjon til nevrale nettverk, husker du kanskje hvor mye tid og arbeid det tok å bygge selv et enkelt nevralt nettverk, der hver nevron ble behandlet individuelt.
TensorFlow forenkler denne prosessen betydelig. Ved å bruke tensorer kan du innkapsle komplekse beregninger, noe som reduserer behovet for innviklet koding. Hovedoppgaven vår er å sette opp en sekvensiell kjede av tensor-operasjoner.
Her er en kort oppsummering av stegene for å få i gang en treningsprosess for et nevralt nettverk:
Datatilrettelegging og modellopprettelse
Den innledende fasen av trening av et nevralt nettverk innebærer tilrettelegging av data, som omfatter både input og output som nettverket skal lære fra. I tillegg fastsettes modellens hyperparametere – dette er parametere som forblir konstante gjennom hele treningsprosessen. Vektene initialiseres, vanligvis trukket fra en normalfordeling, og biasene settes ofte til null.
Fremoverpropagering
I fremoverpropagering følger hvert lag i nettverket vanligvis disse trinnene:
- Multipliser lagets input med dets vekter.
- Legg til en bias til resultatet.
- Bruk en aktiveringsfunksjon på denne summen.
Deretter kan tap beregnes.
Bakoverpropagasjon
Neste steg er bakoverpropagasjon, hvor vekter og biaser justeres basert på deres innflytelse på tapet. Denne innflytelsen representeres av gradienten, som TensorFlows Gradient Tape beregner automatisk. Vektene og biasene oppdateres ved å trekke fra gradienten, skalert med læringsraten.
Treningssløyfe
For å trene nevrale nettverk effektivt, gjentas treningsstegene flere ganger mens modellens ytelse overvåkes. Ideelt sett bør tapet reduseres over epoker.
Sveip for å begynne å kode
Lag et nevralt nettverk designet for å forutsi utfallene av XOR-operasjonen. Nettverket skal bestå av 2 input-nevroner, et skjult lag med 2 nevroner, og 1 output-nevron.
- Start med å sette opp initiale vekter og biaser. Vektene skal initialiseres ved hjelp av en normalfordeling, og alle biaser skal initialiseres til null. Bruk hyperparametrene
input_size,hidden_sizeogoutput_sizefor å definere de riktige formene for disse tensorene. - Benytt en funksjonsdekoratør for å gjøre om
train_step()-funksjonen til en TensorFlow graf. - Utfør fremoverpropagering gjennom både det skjulte og utgangslaget i nettverket. Bruk sigmoid aktiveringsfunksjon.
- Bestem gradientene for å forstå hvordan hver vekt og bias påvirker tapet. Sørg for at gradientene beregnes i riktig rekkefølge, i samsvar med navnene på utgangsvariablene.
- Juster vekter og biaser basert på deres tilsvarende gradienter. Inkluder
learning_ratei denne justeringsprosessen for å kontrollere størrelsen på hver oppdatering.
Løsning
Dataklargjøring
X_data: dette er inndataene for XOR-funksjonen. Det er en NumPy-array med form (4, 2), som representerer de fire mulige kombinasjonene av XOR-innganger (0,0), (0,1), (1,0) og (1,1);Y_data: dette er målverdiene for hver inndatakombinasjon iX_data. Det er også en NumPy-array, men med form (4, 1), som representerer XOR-utdata for hvert inndatapars.
Nettverksparametere
input_size: størrelsen på inndatalaget, satt til 2, tilsvarende de to inngangsnodene (for de to inngangene til XOR-funksjonen);hidden_size: størrelsen på det skjulte laget, også satt til 2. Dette valget er noe vilkårlig, men er tilstrekkelig for å lære XOR-funksjonen;output_size: størrelsen på utgangslaget, satt til 1, tilsvarende den ene utgangsnoden (resultatet av XOR-operasjonen);learning_rate: dette er læringsraten for optimaliseringsalgoritmen, som styrer hvor mye vektene justeres under trening.
Vekter og bias
W1ogb1: vektene (W1) og biasene (b1) for forbindelsene fra inndatalaget til det skjulte laget.W1er en TensorFlow-variabel initialisert med tilfeldige verdier og har form(input_size, hidden_size), altså(2, 2).b1er en TensorFlow-variabel initialisert med nuller og har form(hidden_size), altså(2);W2ogb2: vektene (W2) og biasene (b2) for forbindelsene fra det skjulte laget til utgangslaget.W2er initialisert med tilfeldige verdier og har form(hidden_size, output_size), altså(2, 1).b2er initialisert med nuller og har form(output_size), altså(1).
Treningsfunksjon
train_step(): dette er kjernen i treningsfunksjonen. Den brukertf.GradientTape()for automatisk differensiering. I foroverpasset beregnes aktiveringen i det skjulte laget (a1) og utgangsprediksjonene (Y_pred). Tapet beregnes som gjennomsnittlig kvadratfeil mellomY_predogY. Funksjonen beregner deretter gradientene og oppdaterer vektene og biasene;tf.sigmoid(): en sigmoid aktiveringsfunksjon brukes, som transformerer inndata til en verdi mellom0og1. Dette brukes både for det skjulte laget og utgangslaget.
Treningssløyfe
- Nettverket trenes i
2500epoker. I hver epoke kallestrain_step()-funksjonen, og vektene oppdateres. Tapet skrives ut hver500epoke for å overvåke treningsfremdriften.
Konklusjon
Siden XOR-funksjonen er en relativt enkel oppgave, trenger vi ikke avanserte teknikker som hyperparameterjustering, datasett-deling eller å bygge komplekse datapipelines på dette stadiet. Denne øvelsen er bare et steg mot å bygge mer sofistikerte nevrale nettverk for virkelige applikasjoner.
Å mestre disse grunnleggende prinsippene er avgjørende før man går videre til avanserte teknikker for bygging av nevrale nettverk i kommende kurs, hvor vi vil bruke Keras-biblioteket og utforske metoder for å forbedre modellkvalitet med TensorFlows omfattende funksjoner.
Takk for tilbakemeldingene dine!
single
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
