Introduksjon til konvolusjonsnevrale nettverk
Sveip for å vise menyen
Hva er et CNN, og hvorfor er det annerledes enn tradisjonelle nevrale nettverk?
Et konvolusjonsnevralt nettverk (CNN) er en type kunstig intelligens som hjelper datamaskiner å "se" og forstå bilder. I motsetning til vanlige nevrale nettverk som behandler bilder som en liste med tall, ser CNN-er på bilder i seksjoner og gjenkjenner mønstre som kanter, former og teksturer. Dette gjør dem mye bedre til å håndtere bilder og videoer.
Hvordan CNN-er er inspirert av det menneskelige øyet
CNN-er fungerer på en måte som ligner på hvordan hjernen vår prosesserer bilder. Når vi ser på noe, sender øynene våre informasjon til hjernen, som først gjenkjenner enkle former som kanter og farger. Deretter setter dypere lag i hjernen sammen disse delene for å forstå objekter, ansikter eller hele scener. CNN-er følger samme prinsipp, starter med enkle trekk og bygger opp til å gjenkjenne komplekse objekter.
Akkurat som øynene våre fokuserer på bestemte områder, behandler også CNN-er bilder i små seksjoner, noe som hjelper dem å gjenkjenne mønstre uansett hvor de dukker opp. Men i motsetning til mennesker, trenger CNN-er tusenvis av merkede bilder for å lære, mens mennesker kan gjenkjenne objekter selv om de bare har sett dem noen få ganger.
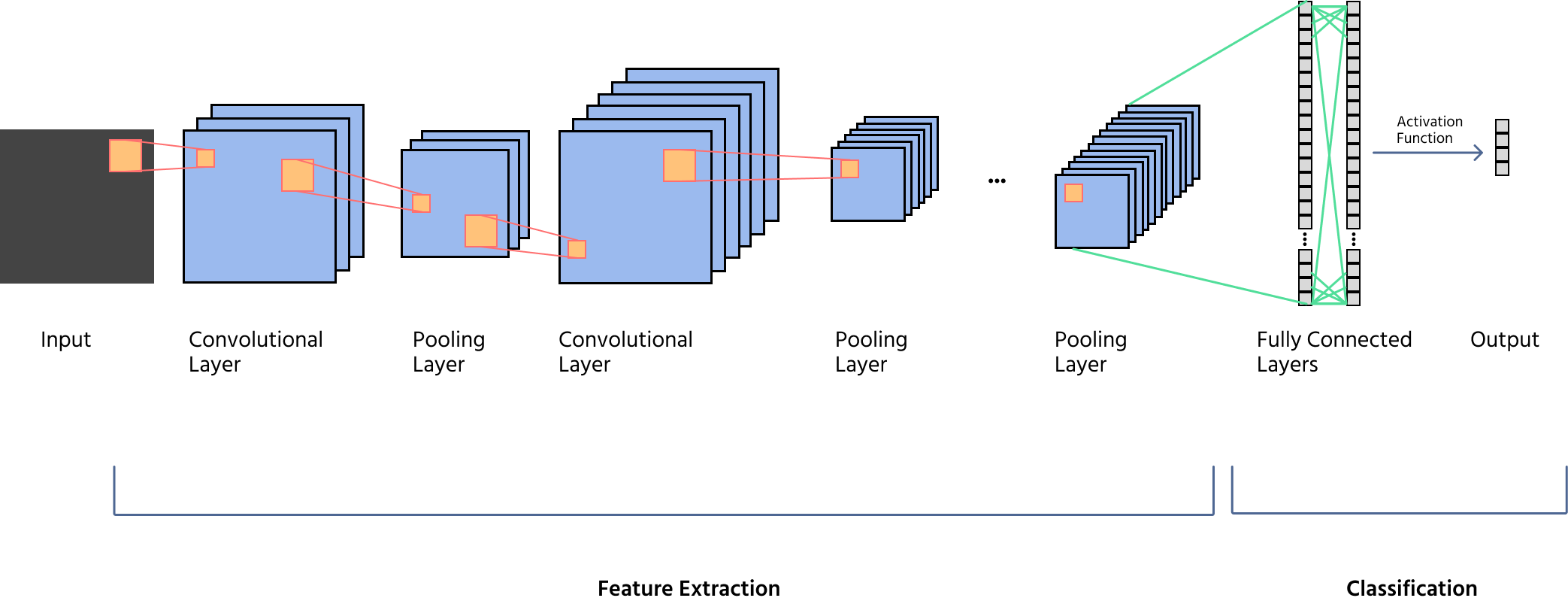
Oversikt over nøkkelkomponenter: Konvolusjon, pooling, aktivering og fullt tilkoblede lag
Et CNN består av flere lag, hvor hvert lag har en bestemt rolle i bildebehandling:
- Bruk av filtre (kjerner) for å oppdage mønstre som kanter, teksturer og former;
- Bruk av steglengde og utfylling for å kontrollere dimensjonene til feature maps;
- Generering av flere feature maps for dyp funksjonsekstraksjon.
- Innføring av ikke-linearitet, som gjør det mulig for CNN-er å lære komplekse representasjoner;
- Vanlige funksjoner inkluderer ReLU (Rectified Linear Unit), Leaky ReLU og Sigmoid.
- Reduksjon av de romlige dimensjonene til feature maps samtidig som viktig informasjon bevares;
- Typer inkluderer maks pooling (fanger opp dominerende trekk) og gjennomsnittspooling (utjevner representasjoner);
- Bidrar til translasjonsinvarians og beregningseffektivitet.
- Flater ut feature maps til en 1D-vektor for klassifisering;
- Kobles til et siste utgangslag ved bruk av Softmax (for flerkategoriklassifisering) eller Sigmoid (for binær klassifisering).
CNN-er er kraftige fordi de automatisk kan lære funksjoner fra bilder uten at mennesker må programmere hver detalj. Derfor brukes de i selvkjørende biler, ansiktsgjenkjenning, medisinsk bildediagnostikk og mange andre virkelige applikasjoner.
1. Hva er den viktigste fordelen med CNN-er sammenlignet med tradisjonelle nevrale nettverk ved bildebehandling?
2. Koble elementet i CNN til dets funksjon.
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Introduksjon til konvolusjonsnevrale nettverk
Hva er et CNN, og hvorfor er det annerledes enn tradisjonelle nevrale nettverk?
Et konvolusjonsnevralt nettverk (CNN) er en type kunstig intelligens som hjelper datamaskiner å "se" og forstå bilder. I motsetning til vanlige nevrale nettverk som behandler bilder som en liste med tall, ser CNN-er på bilder i seksjoner og gjenkjenner mønstre som kanter, former og teksturer. Dette gjør dem mye bedre til å håndtere bilder og videoer.
Hvordan CNN-er er inspirert av det menneskelige øyet
CNN-er fungerer på en måte som ligner på hvordan hjernen vår prosesserer bilder. Når vi ser på noe, sender øynene våre informasjon til hjernen, som først gjenkjenner enkle former som kanter og farger. Deretter setter dypere lag i hjernen sammen disse delene for å forstå objekter, ansikter eller hele scener. CNN-er følger samme prinsipp, starter med enkle trekk og bygger opp til å gjenkjenne komplekse objekter.
Akkurat som øynene våre fokuserer på bestemte områder, behandler også CNN-er bilder i små seksjoner, noe som hjelper dem å gjenkjenne mønstre uansett hvor de dukker opp. Men i motsetning til mennesker, trenger CNN-er tusenvis av merkede bilder for å lære, mens mennesker kan gjenkjenne objekter selv om de bare har sett dem noen få ganger.
Oversikt over nøkkelkomponenter: Konvolusjon, pooling, aktivering og fullt tilkoblede lag
Et CNN består av flere lag, hvor hvert lag har en bestemt rolle i bildebehandling:
- Bruk av filtre (kjerner) for å oppdage mønstre som kanter, teksturer og former;
- Bruk av steglengde og utfylling for å kontrollere dimensjonene til feature maps;
- Generering av flere feature maps for dyp funksjonsekstraksjon.
- Innføring av ikke-linearitet, som gjør det mulig for CNN-er å lære komplekse representasjoner;
- Vanlige funksjoner inkluderer ReLU (Rectified Linear Unit), Leaky ReLU og Sigmoid.
- Reduksjon av de romlige dimensjonene til feature maps samtidig som viktig informasjon bevares;
- Typer inkluderer maks pooling (fanger opp dominerende trekk) og gjennomsnittspooling (utjevner representasjoner);
- Bidrar til translasjonsinvarians og beregningseffektivitet.
- Flater ut feature maps til en 1D-vektor for klassifisering;
- Kobles til et siste utgangslag ved bruk av Softmax (for flerkategoriklassifisering) eller Sigmoid (for binær klassifisering).
CNN-er er kraftige fordi de automatisk kan lære funksjoner fra bilder uten at mennesker må programmere hver detalj. Derfor brukes de i selvkjørende biler, ansiktsgjenkjenning, medisinsk bildediagnostikk og mange andre virkelige applikasjoner.
Takk for tilbakemeldingene dine!
