Oversikt over Populære CNN-modeller
Sveip for å vise menyen
Konvolusjonsnevrale nettverk (CNN-er) har utviklet seg betydelig, med ulike arkitekturer som forbedrer nøyaktighet, effektivitet og skalerbarhet. Dette kapittelet utforsker fem sentrale CNN-modeller som har formet dyp læring: LeNet, AlexNet, VGGNet, ResNet og InceptionNet.
LeNet: Grunnlaget for CNN-er
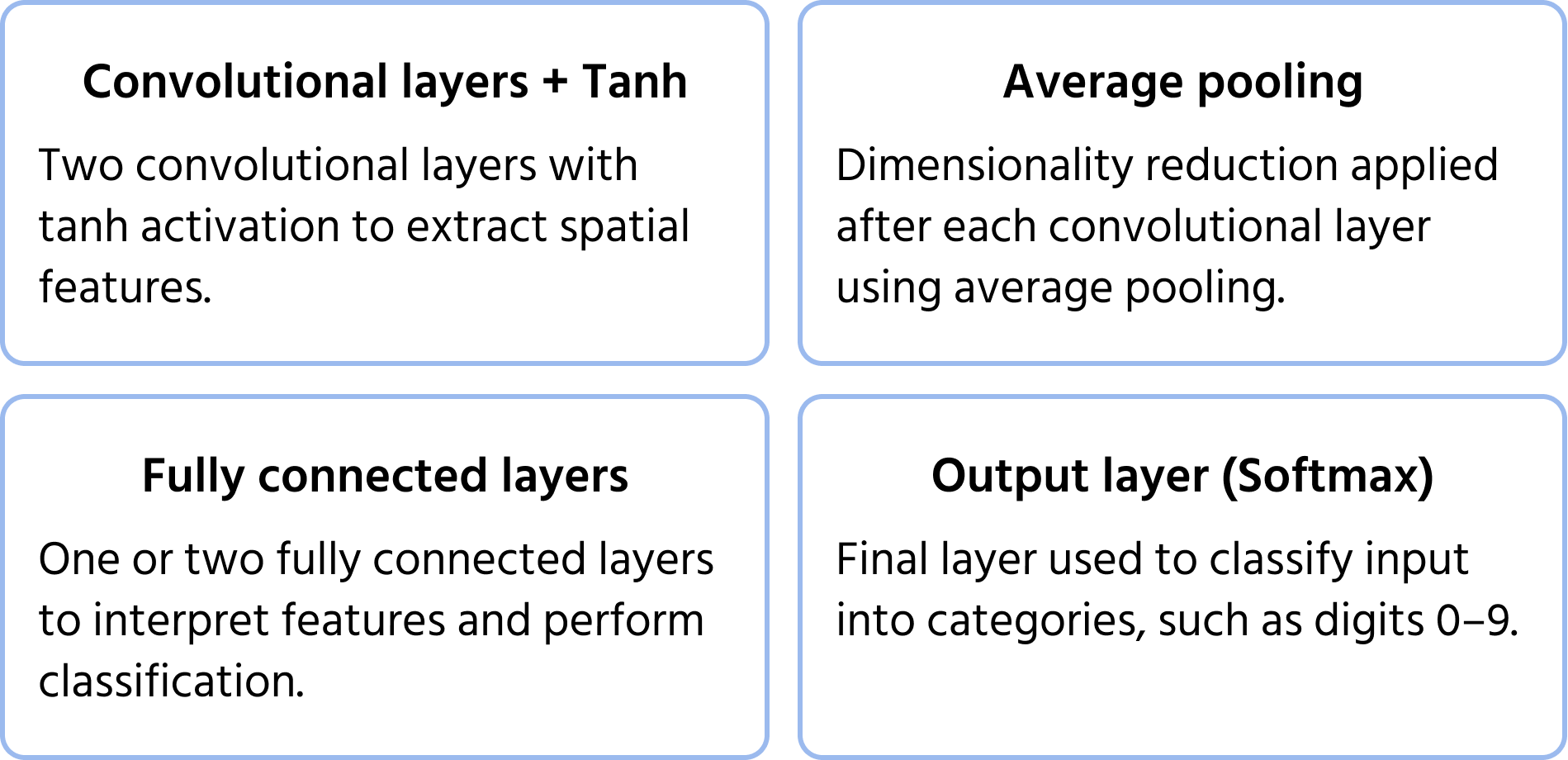
En av de første konvolusjonsnevrale nettverksarkitekturene, foreslått av Yann LeCun i 1998 for håndskrevet siffergjenkjenning. Den la grunnlaget for moderne CNN-er ved å introdusere sentrale komponenter som konvolusjoner, pooling og fullt tilkoblede lag. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
AlexNet: Gjennombrudd innen dyp læring
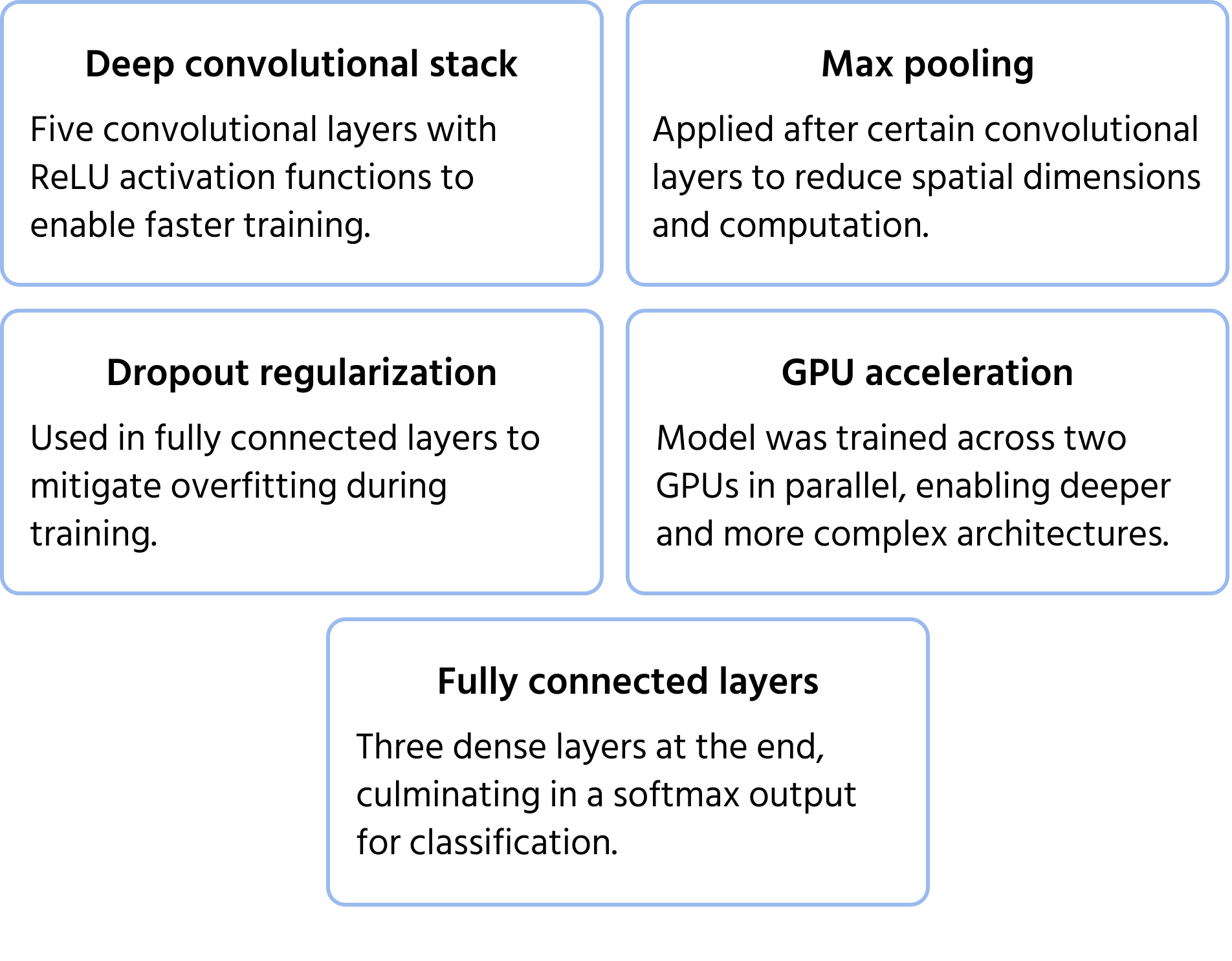
Et banebrytende CNN-arkitektur som vant ImageNet-konkurransen i 2012, AlexNet viste at dype konvolusjonsnettverk kunne overgå tradisjonelle maskinlæringsmetoder betydelig for storskala bildeklassifisering. Den introduserte innovasjoner som har blitt standard i moderne dyp læring. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
VGGNet: Dypere nettverk med ensartede filtre
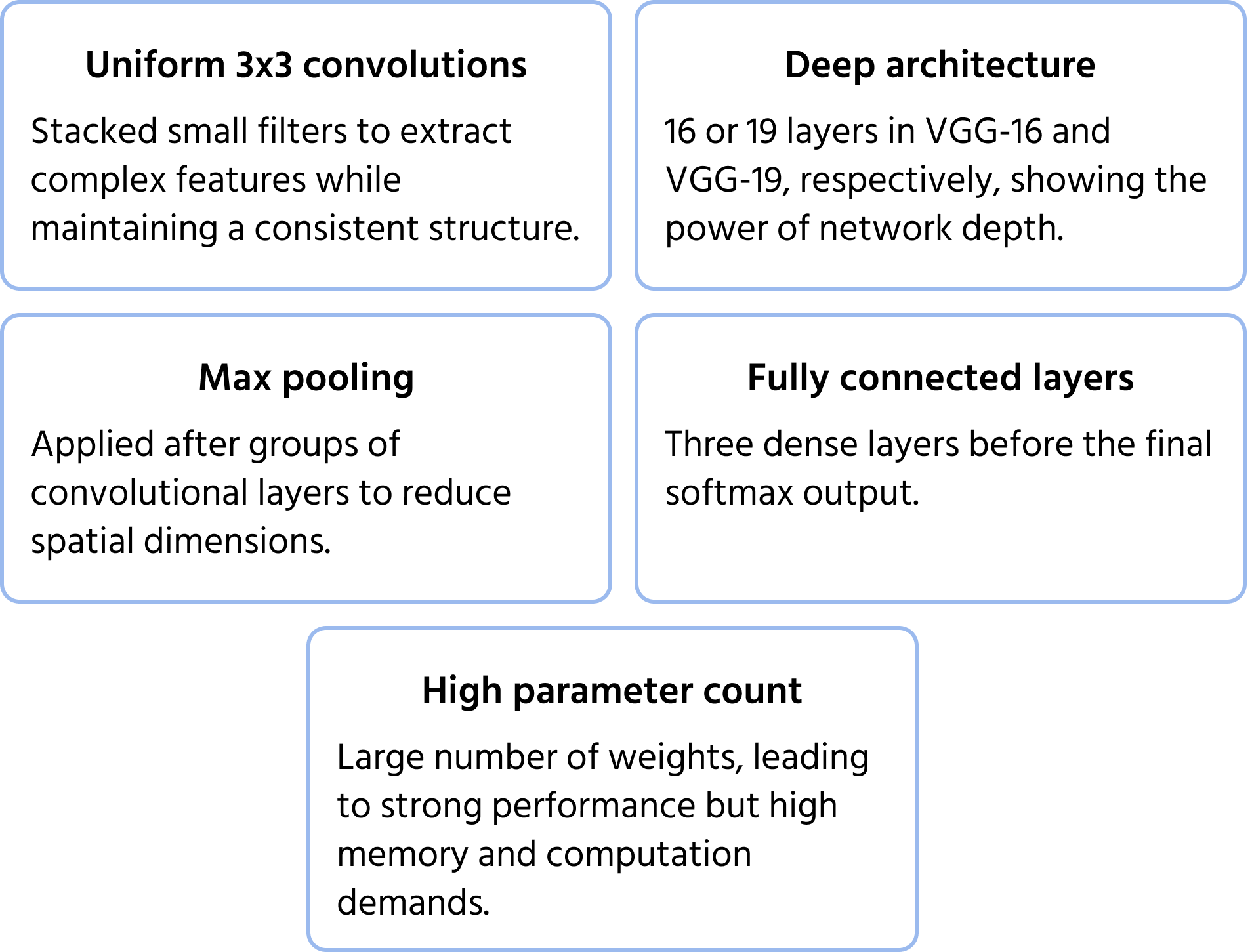
Utviklet av Visual Geometry Group ved Oxford, la VGGNet vekt på dybde og enkelhet ved å bruke ensartede 3×3 konvolusjonsfiltre. Den demonstrerte at stabling av små filtre i dype nettverk kunne forbedre ytelsen betydelig, noe som førte til mye brukte varianter som VGG-16 og VGG-19. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
ResNet: Løsning på dybdeproblemet
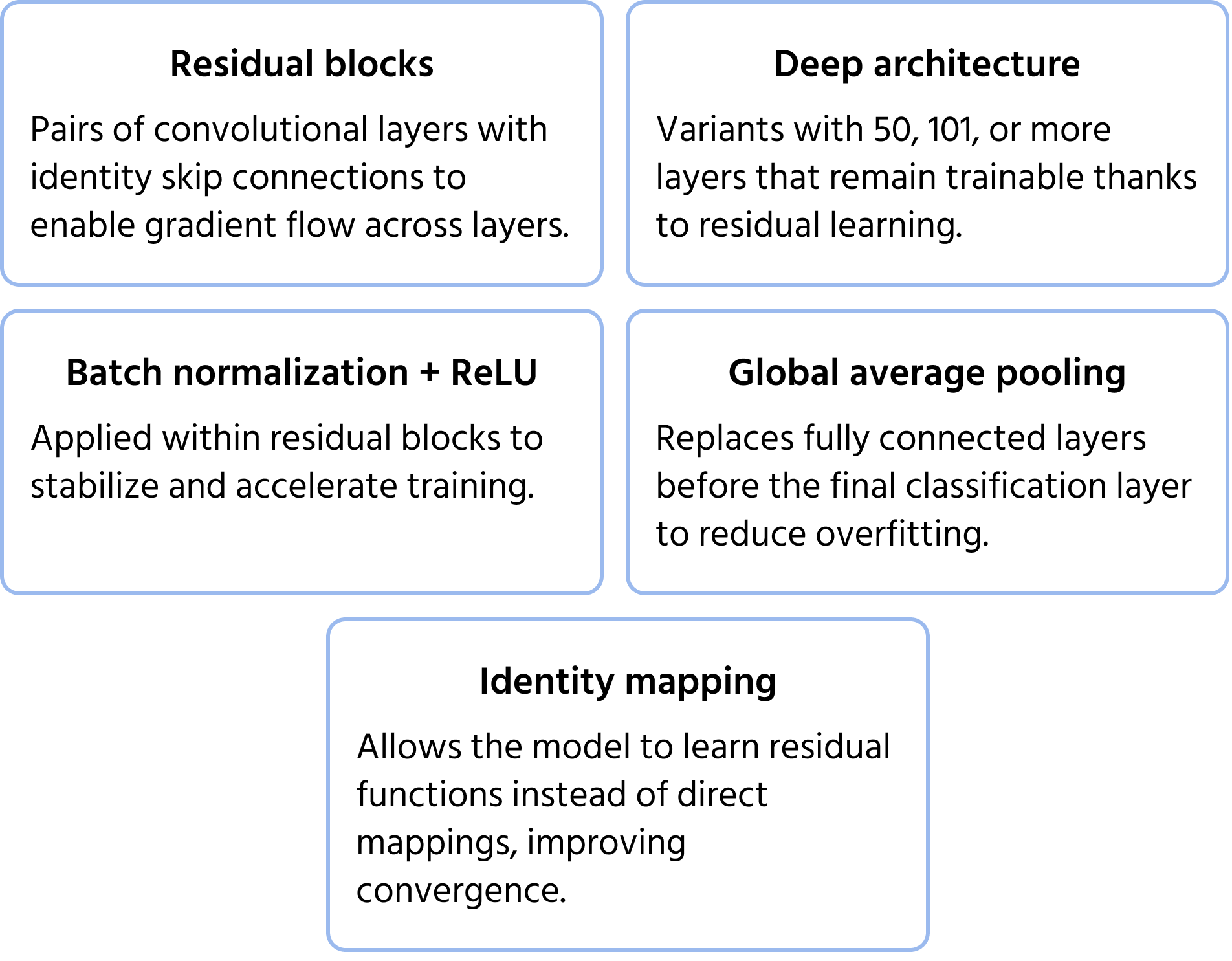
ResNet (Residual Networks), introdusert av Microsoft i 2015, adresserte problemet med forsvinnende gradient, som oppstår ved trening av svært dype nettverk. Tradisjonelle dype nettverk har utfordringer med treningseffektivitet og ytelsesforringelse, men ResNet løste dette med skip connections (residuallæring). Disse snarveiene lar informasjon passere forbi enkelte lag, noe som sikrer at gradientene fortsetter å forplante seg effektivt. ResNet-arkitekturer, som ResNet-50 og ResNet-101, muliggjorde trening av nettverk med hundrevis av lag, noe som betydelig forbedret nøyaktigheten for bildeklassifisering. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
InceptionNet: Multi-skala funksjonsekstraksjon
InceptionNet (også kjent som GoogLeNet) bygger på inception-modulen for å skape en dyp, men effektiv arkitektur. I stedet for å stable lag sekvensielt, bruker InceptionNet parallelle baner for å trekke ut funksjoner på ulike nivåer. Du kan lære mer om modellen i dokumentasjonen.
Viktige optimaliseringer inkluderer:
- Faktorerte konvolusjoner for å redusere beregningskostnader;
- Hjelpeklassifisatorer i mellomliggende lag for å forbedre treningsstabilitet;
- Global gjennomsnittspooling i stedet for fullt tilkoblede lag, noe som reduserer antall parametere og opprettholder ytelsen.
Denne strukturen gjør det mulig for InceptionNet å være dypere enn tidligere CNN-er som VGG, uten å øke de beregningsmessige kravene drastisk.
Viktige arkitekturegenskaper
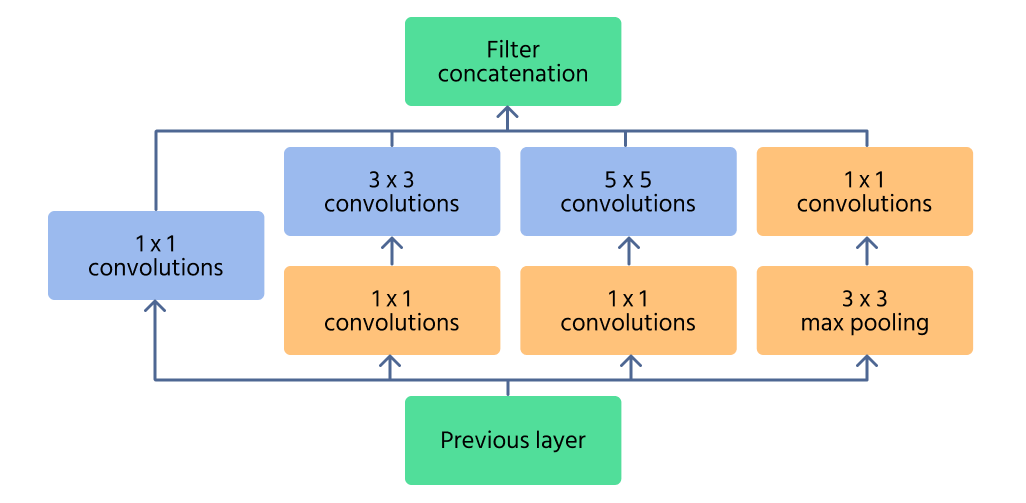
Inception-modul
Inception-modulen er kjernen i InceptionNet, utviklet for effektivt å fange opp trekk i flere skalaer. I stedet for å bruke én enkelt konvolusjonsoperasjon, behandler modulen input med flere filterstørrelser (1×1, 3×3, 5×5) parallelt. Dette gjør det mulig for nettverket å gjenkjenne både fine detaljer og store mønstre i et bilde.
For å redusere beregningskostnader benyttes 1×1 convolutions før større filtre anvendes. Disse reduserer antall inngangskanaler, noe som gjør nettverket mer effektivt. I tillegg bidrar maks-pooling-lag i modulen til å bevare essensielle trekk samtidig som dimensjonaliteten kontrolleres.
Eksempel
Vurder et eksempel for å se hvordan reduksjon av dimensjoner minsker den beregningsmessige belastningen. Anta at vi må konvolvere 28 × 28 × 192 input feature maps med 5 × 5 × 32 filters. Denne operasjonen vil kreve omtrent 120,42 millioner beregninger.

Number of operations = (2828192) * (5532) = 120,422,400 operations
La oss utføre beregningene på nytt, men denne gangen setter vi et 1×1 convolutional layer før vi bruker 5×5 convolution på de samme inngående feature-kartene.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Hver av disse CNN-arkitekturene har spilt en avgjørende rolle i utviklingen av datamaskinsyn, og har påvirket anvendelser innen helsetjenester, autonome systemer, sikkerhet og sanntids bildebehandling. Fra LeNet sine grunnleggende prinsipper til InceptionNet sin fler-skala funksjonsekstraksjon, har disse modellene kontinuerlig presset grensene for dyp læring og banet vei for enda mer avanserte arkitekturer i fremtiden.
1. Hva var den primære innovasjonen introdusert av ResNet som gjorde det mulig å trene ekstremt dype nettverk?
2. Hvordan forbedrer InceptionNet beregningseffektiviteten sammenlignet med tradisjonelle CNN-er?
3. Hvilken CNN-arkitektur introduserte først konseptet med å bruke små 3×3 konvolusjonsfiltre gjennom hele nettverket?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Oversikt over Populære CNN-modeller
Konvolusjonsnevrale nettverk (CNN-er) har utviklet seg betydelig, med ulike arkitekturer som forbedrer nøyaktighet, effektivitet og skalerbarhet. Dette kapittelet utforsker fem sentrale CNN-modeller som har formet dyp læring: LeNet, AlexNet, VGGNet, ResNet og InceptionNet.
LeNet: Grunnlaget for CNN-er
En av de første konvolusjonsnevrale nettverksarkitekturene, foreslått av Yann LeCun i 1998 for håndskrevet siffergjenkjenning. Den la grunnlaget for moderne CNN-er ved å introdusere sentrale komponenter som konvolusjoner, pooling og fullt tilkoblede lag. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
AlexNet: Gjennombrudd innen dyp læring
Et banebrytende CNN-arkitektur som vant ImageNet-konkurransen i 2012, AlexNet viste at dype konvolusjonsnettverk kunne overgå tradisjonelle maskinlæringsmetoder betydelig for storskala bildeklassifisering. Den introduserte innovasjoner som har blitt standard i moderne dyp læring. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
VGGNet: Dypere nettverk med ensartede filtre
Utviklet av Visual Geometry Group ved Oxford, la VGGNet vekt på dybde og enkelhet ved å bruke ensartede 3×3 konvolusjonsfiltre. Den demonstrerte at stabling av små filtre i dype nettverk kunne forbedre ytelsen betydelig, noe som førte til mye brukte varianter som VGG-16 og VGG-19. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
ResNet: Løsning på dybdeproblemet
ResNet (Residual Networks), introdusert av Microsoft i 2015, adresserte problemet med forsvinnende gradient, som oppstår ved trening av svært dype nettverk. Tradisjonelle dype nettverk har utfordringer med treningseffektivitet og ytelsesforringelse, men ResNet løste dette med skip connections (residuallæring). Disse snarveiene lar informasjon passere forbi enkelte lag, noe som sikrer at gradientene fortsetter å forplante seg effektivt. ResNet-arkitekturer, som ResNet-50 og ResNet-101, muliggjorde trening av nettverk med hundrevis av lag, noe som betydelig forbedret nøyaktigheten for bildeklassifisering. Du kan lære mer om modellen i dokumentasjonen.
Viktige arkitekturelle egenskaper
InceptionNet: Multi-skala funksjonsekstraksjon
InceptionNet (også kjent som GoogLeNet) bygger på inception-modulen for å skape en dyp, men effektiv arkitektur. I stedet for å stable lag sekvensielt, bruker InceptionNet parallelle baner for å trekke ut funksjoner på ulike nivåer. Du kan lære mer om modellen i dokumentasjonen.
Viktige optimaliseringer inkluderer:
- Faktorerte konvolusjoner for å redusere beregningskostnader;
- Hjelpeklassifisatorer i mellomliggende lag for å forbedre treningsstabilitet;
- Global gjennomsnittspooling i stedet for fullt tilkoblede lag, noe som reduserer antall parametere og opprettholder ytelsen.
Denne strukturen gjør det mulig for InceptionNet å være dypere enn tidligere CNN-er som VGG, uten å øke de beregningsmessige kravene drastisk.
Viktige arkitekturegenskaper
Inception-modul
Inception-modulen er kjernen i InceptionNet, utviklet for effektivt å fange opp trekk i flere skalaer. I stedet for å bruke én enkelt konvolusjonsoperasjon, behandler modulen input med flere filterstørrelser (1×1, 3×3, 5×5) parallelt. Dette gjør det mulig for nettverket å gjenkjenne både fine detaljer og store mønstre i et bilde.
For å redusere beregningskostnader benyttes 1×1 convolutions før større filtre anvendes. Disse reduserer antall inngangskanaler, noe som gjør nettverket mer effektivt. I tillegg bidrar maks-pooling-lag i modulen til å bevare essensielle trekk samtidig som dimensjonaliteten kontrolleres.
Eksempel
Vurder et eksempel for å se hvordan reduksjon av dimensjoner minsker den beregningsmessige belastningen. Anta at vi må konvolvere 28 × 28 × 192 input feature maps med 5 × 5 × 32 filters. Denne operasjonen vil kreve omtrent 120,42 millioner beregninger.
Number of operations = (2828192) * (5532) = 120,422,400 operations
La oss utføre beregningene på nytt, men denne gangen setter vi et 1×1 convolutional layer før vi bruker 5×5 convolution på de samme inngående feature-kartene.
Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Hver av disse CNN-arkitekturene har spilt en avgjørende rolle i utviklingen av datamaskinsyn, og har påvirket anvendelser innen helsetjenester, autonome systemer, sikkerhet og sanntids bildebehandling. Fra LeNet sine grunnleggende prinsipper til InceptionNet sin fler-skala funksjonsekstraksjon, har disse modellene kontinuerlig presset grensene for dyp læring og banet vei for enda mer avanserte arkitekturer i fremtiden.
Takk for tilbakemeldingene dine!
