Aktiveringsfunksjoner
Sveip for å vise menyen
Hvorfor aktiveringsfunksjoner er avgjørende i CNN-er
Aktiveringsfunksjoner tilfører ikke-linearitet til CNN-er, noe som gjør det mulig å lære komplekse mønstre utover det en enkel lineær modell kan oppnå. Uten aktiveringsfunksjoner ville CNN-er hatt vanskeligheter med å oppdage intrikate sammenhenger i data, noe som begrenser deres effektivitet i bildegjenkjenning og klassifisering. Valg av riktig aktiveringsfunksjon påvirker treningshastighet, stabilitet og total ytelse.
Vanlige aktiveringsfunksjoner
- ReLU (rectified linear unit): den mest brukte aktiveringsfunksjonen i CNN-er. Den slipper kun gjennom positive verdier og setter alle negative input til null, noe som gjør den beregningseffektiv og forhindrer forsvinnende gradienter. Noen nevroner kan imidlertid bli inaktive på grunn av "døende ReLU"-problemet;

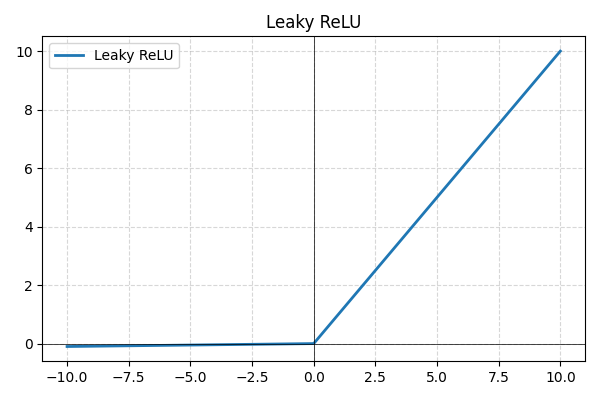
- Leaky ReLU: en variant av ReLU som tillater små negative verdier i stedet for å sette dem til null, noe som forhindrer inaktive nevroner og forbedrer gradientflyten;
- Sigmoid: komprimerer inngangsverdier til et område mellom 0 og 1, noe som gjør den nyttig for binær klassifisering. Den har imidlertid utfordringer med forsvinnende gradienter i dype nettverk;

- Tanh: ligner på Sigmoid, men gir verdier mellom -1 og 1, og sentrerer aktiveringer rundt null;

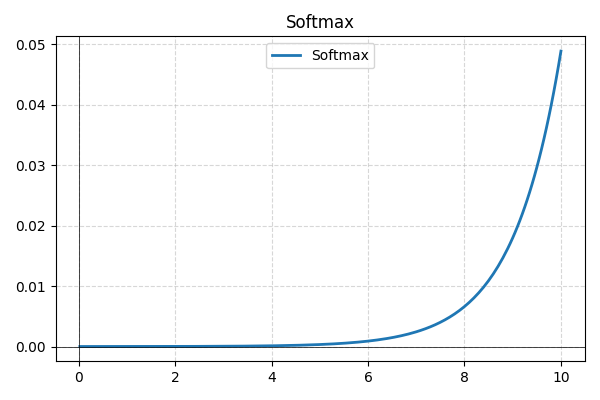
- Softmax: vanligvis brukt i det siste laget for multiklasseklassifisering, Softmax konverterer rå nettverksutganger til sannsynligheter, og sikrer at de summeres til én for bedre tolkbarhet.
Valg av riktig aktiveringsfunksjon
ReLU er standardvalget for skjulte lag på grunn av effektivitet og god ytelse, mens Leaky ReLU er et bedre alternativ når inaktivitet i nevroner oppstår. Sigmoid og Tanh unngås vanligvis i dype CNN-er, men kan fortsatt være nyttige i spesifikke applikasjoner. Softmax er fortsatt essensiell for oppgaver med flere klasser, og sikrer tydelige sannsynlighetsbaserte prediksjoner.
Å velge riktig aktiveringsfunksjon er avgjørende for å optimalisere ytelsen til CNN, balansere effektivitet og forhindre problemer som forsvinnende eller eksploderende gradienter. Hver funksjon bidrar unikt til hvordan et nettverk prosesserer og lærer fra visuelle data.
1. Hvorfor foretrekkes ReLU fremfor Sigmoid i dype CNN-er?
2. Hvilken aktiveringsfunksjon brukes vanligvis i det siste laget av et multi-klasse klassifiserings-CNN?
3. Hva er hovedfordelen med Leaky ReLU sammenlignet med standard ReLU?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Aktiveringsfunksjoner
Hvorfor aktiveringsfunksjoner er avgjørende i CNN-er
Aktiveringsfunksjoner tilfører ikke-linearitet til CNN-er, noe som gjør det mulig å lære komplekse mønstre utover det en enkel lineær modell kan oppnå. Uten aktiveringsfunksjoner ville CNN-er hatt vanskeligheter med å oppdage intrikate sammenhenger i data, noe som begrenser deres effektivitet i bildegjenkjenning og klassifisering. Valg av riktig aktiveringsfunksjon påvirker treningshastighet, stabilitet og total ytelse.
Vanlige aktiveringsfunksjoner
- ReLU (rectified linear unit): den mest brukte aktiveringsfunksjonen i CNN-er. Den slipper kun gjennom positive verdier og setter alle negative input til null, noe som gjør den beregningseffektiv og forhindrer forsvinnende gradienter. Noen nevroner kan imidlertid bli inaktive på grunn av "døende ReLU"-problemet;
- Leaky ReLU: en variant av ReLU som tillater små negative verdier i stedet for å sette dem til null, noe som forhindrer inaktive nevroner og forbedrer gradientflyten;
- Sigmoid: komprimerer inngangsverdier til et område mellom 0 og 1, noe som gjør den nyttig for binær klassifisering. Den har imidlertid utfordringer med forsvinnende gradienter i dype nettverk;
- Tanh: ligner på Sigmoid, men gir verdier mellom -1 og 1, og sentrerer aktiveringer rundt null;
- Softmax: vanligvis brukt i det siste laget for multiklasseklassifisering, Softmax konverterer rå nettverksutganger til sannsynligheter, og sikrer at de summeres til én for bedre tolkbarhet.
Valg av riktig aktiveringsfunksjon
ReLU er standardvalget for skjulte lag på grunn av effektivitet og god ytelse, mens Leaky ReLU er et bedre alternativ når inaktivitet i nevroner oppstår. Sigmoid og Tanh unngås vanligvis i dype CNN-er, men kan fortsatt være nyttige i spesifikke applikasjoner. Softmax er fortsatt essensiell for oppgaver med flere klasser, og sikrer tydelige sannsynlighetsbaserte prediksjoner.
Å velge riktig aktiveringsfunksjon er avgjørende for å optimalisere ytelsen til CNN, balansere effektivitet og forhindre problemer som forsvinnende eller eksploderende gradienter. Hver funksjon bidrar unikt til hvordan et nettverk prosesserer og lærer fra visuelle data.
Takk for tilbakemeldingene dine!
