Oversikt over bildegenerering
Sveip for å vise menyen
AI-genererte bilder endrer måten folk lager kunst, design og digitalt innhold på. Ved hjelp av kunstig intelligens kan datamaskiner nå lage realistiske bilder, forbedre kreativt arbeid og til og med bistå bedrifter. I dette kapittelet utforsker vi hvordan AI lager bilder, ulike typer bildemodeller og hvordan de brukes i praksis.
Hvordan AI lager bilder
AI-bildegenerering fungerer ved å lære fra en stor samling bilder. AI-en studerer mønstre i bildene og lager deretter nye som ligner. Denne teknologien har utviklet seg mye over tid, og gir nå bilder som er mer realistiske og kreative. Den brukes nå i videospill, filmer, reklame og til og med mote.
Tidlige metoder: PixelRNN og PixelCNN
Før dagens avanserte AI-modeller utviklet forskere tidlige metoder for bildegenerering som PixelRNN og PixelCNN. Disse modellene laget bilder ved å forutsi én piksel om gangen.
- PixelRNN: bruker et system kalt et rekurrent nevralt nettverk (RNN) for å forutsi pikselfarger én etter én. Selv om det fungerte bra, var det veldig tregt;
- PixelCNN: forbedret PixelRNN ved å bruke en annen type nettverk, kalt konvolusjonslag, som gjorde bildeopprettelsen raskere.
Selv om disse modellene var et godt utgangspunkt, var de ikke gode til å lage bilder av høy kvalitet. Dette førte til utviklingen av bedre teknikker.
Autoregressive modeller
Autoregressive modeller lager også bilder én piksel om gangen, ved å bruke tidligere piksler for å forutsi hva som kommer neste. Disse modellene var nyttige, men trege, noe som gjorde dem mindre populære over tid. Likevel bidro de til å inspirere nyere og raskere modeller.
Hvordan KI forstår tekst for bildegenerering
Noen KI-modeller kan gjøre om skrevne ord til bilder. Disse modellene bruker Large Language Models (LLMs) for å forstå beskrivelser og generere tilsvarende bilder. For eksempel, hvis du skriver “a cat sitting on a beach at sunset”, vil KI-en lage et bilde basert på denne beskrivelsen.
KI-modeller som OpenAI sin DALL-E og Googles Imagen bruker avansert språkforståelse for å forbedre hvor godt tekstbeskrivelser samsvarer med bildene de genererer. Dette er mulig gjennom Natural Language Processing (NLP), som hjelper KI med å bryte ned ord til tall som styrer bildegenereringen.
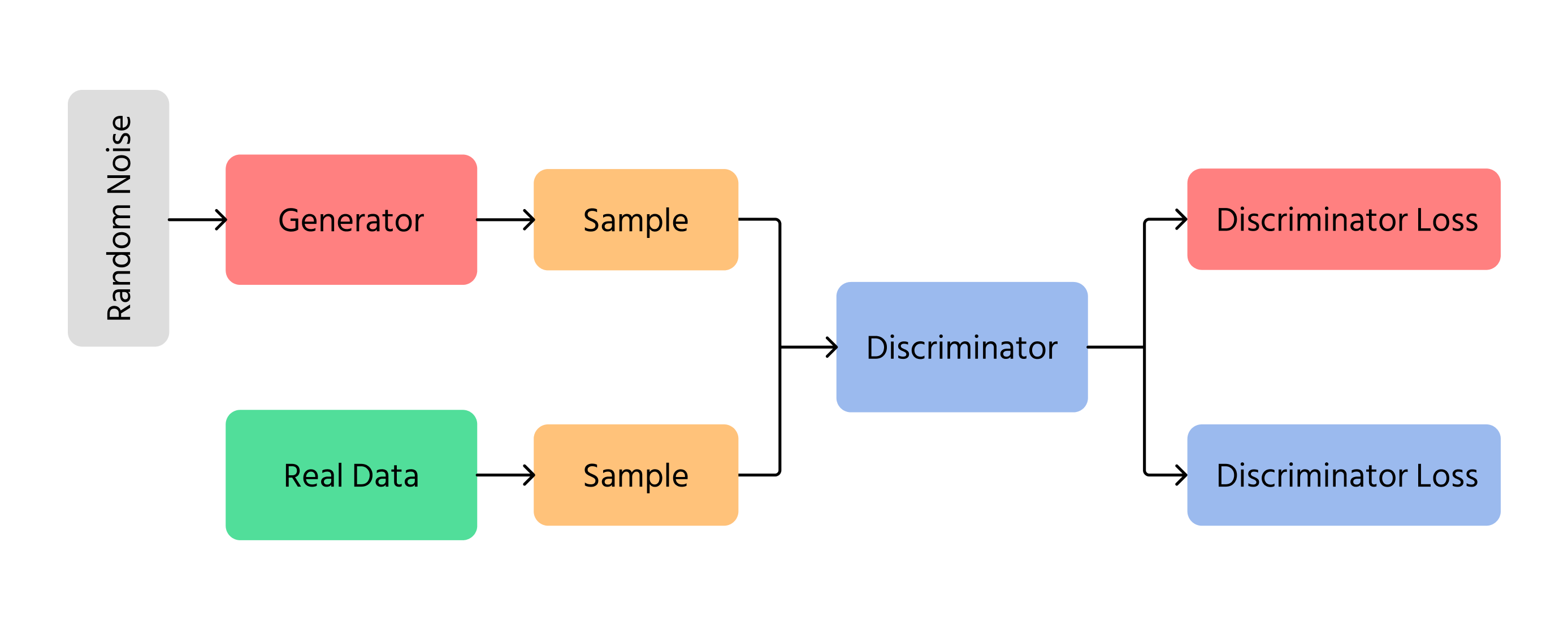
Generative Adversarial Networks (GANs)
En av de viktigste gjennombruddene innen KI-basert bildegenerering var Generative Adversarial Networks (GANs). GANs fungerer ved å bruke to forskjellige nevrale nettverk:
- Generator: lager nye bilder fra bunnen av;
- Discriminator: sjekker om bildene ser ekte eller falske ut.
Generatoren prøver å lage bilder som er så realistiske at diskriminatoren ikke kan se at de er falske. Over tid blir bildene bedre og ser mer ut som ekte fotografier. GANs brukes i deepfake-teknologi, kunstgenerering og forbedring av bildekvalitet.
Variasjonelle autoenkodere (VAE)
VAE-er er en annen metode for at KI kan generere bilder. I stedet for å bruke konkurranse som GAN-er, koder og dekoder VAE-er bilder ved hjelp av sannsynlighet. De fungerer ved å lære de underliggende mønstrene i et bilde og deretter rekonstruere det med små variasjoner. Det sannsynlighetsbaserte elementet i VAE-er sørger for at hvert genererte bilde er litt forskjellig, noe som gir variasjon og kreativitet.
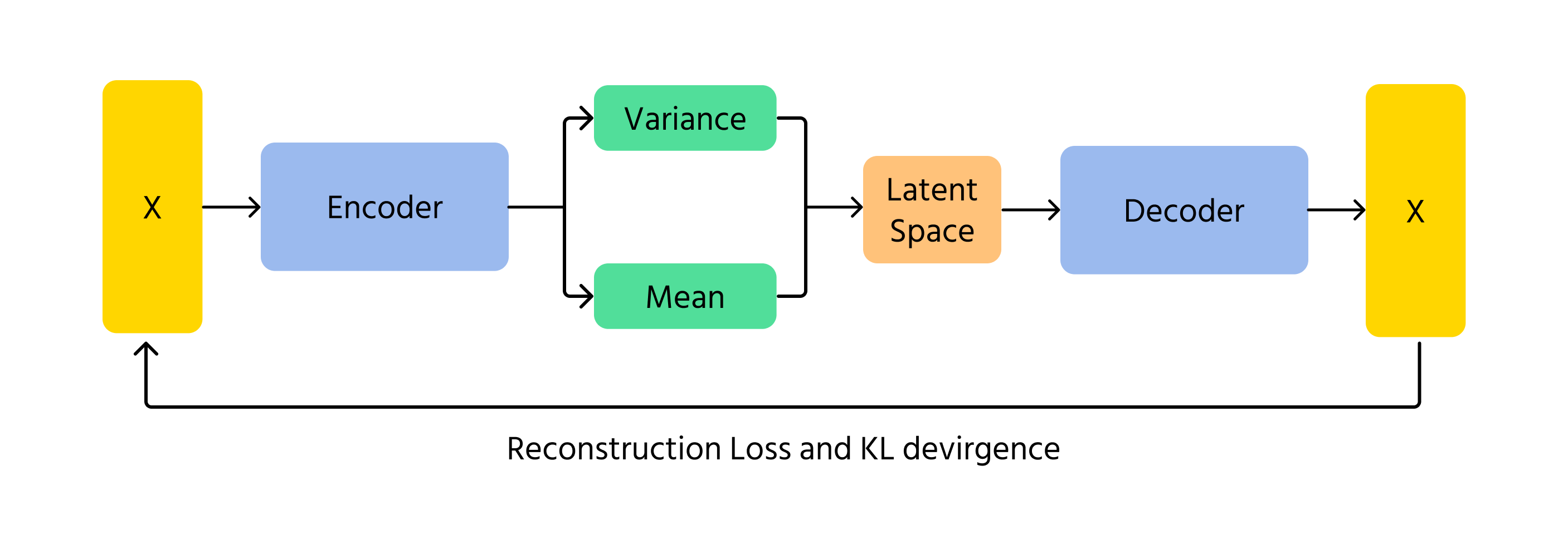
Et sentralt konsept i VAE-er er Kullback-Leibler (KL) divergens, som måler forskjellen mellom den lærte fordelingen og en standard normalfordeling. Ved å minimere KL-divergens sikrer VAE-er at genererte bilder forblir realistiske, samtidig som de tillater kreative variasjoner.
Hvordan VAE-er fungerer
- Koding: inndata x mates inn i koderen, som gir ut parameterne til den latente romfordelingen q(z∣x) (gjennomsnitt μ og varians σ²);
- Prøvetaking i latent rom: latente variabler z trekkes fra fordelingen q(z∣x) ved hjelp av teknikker som reparametriseringstrikset;
- Dekoding og rekonstruksjon: den prøvetatte z sendes gjennom dekoderen for å produsere de rekonstruerte dataene x̂, som bør være lik den opprinnelige inndataen x.
VAE-er er nyttige for oppgaver som å rekonstruere ansikter, generere nye versjoner av eksisterende bilder, og lage jevne overganger mellom ulike bilder.
Diffusjonsmodeller
Diffusjonsmodeller er det nyeste gjennombruddet innen AI-genererte bilder. Disse modellene starter med tilfeldig støy og forbedrer bildet gradvis, steg for steg, omtrent som å fjerne statisk støy fra et uklart foto. I motsetning til GAN-er, som noen ganger skaper begrensede variasjoner, kan diffusjonsmodeller produsere et bredere spekter av bilder med høy kvalitet.
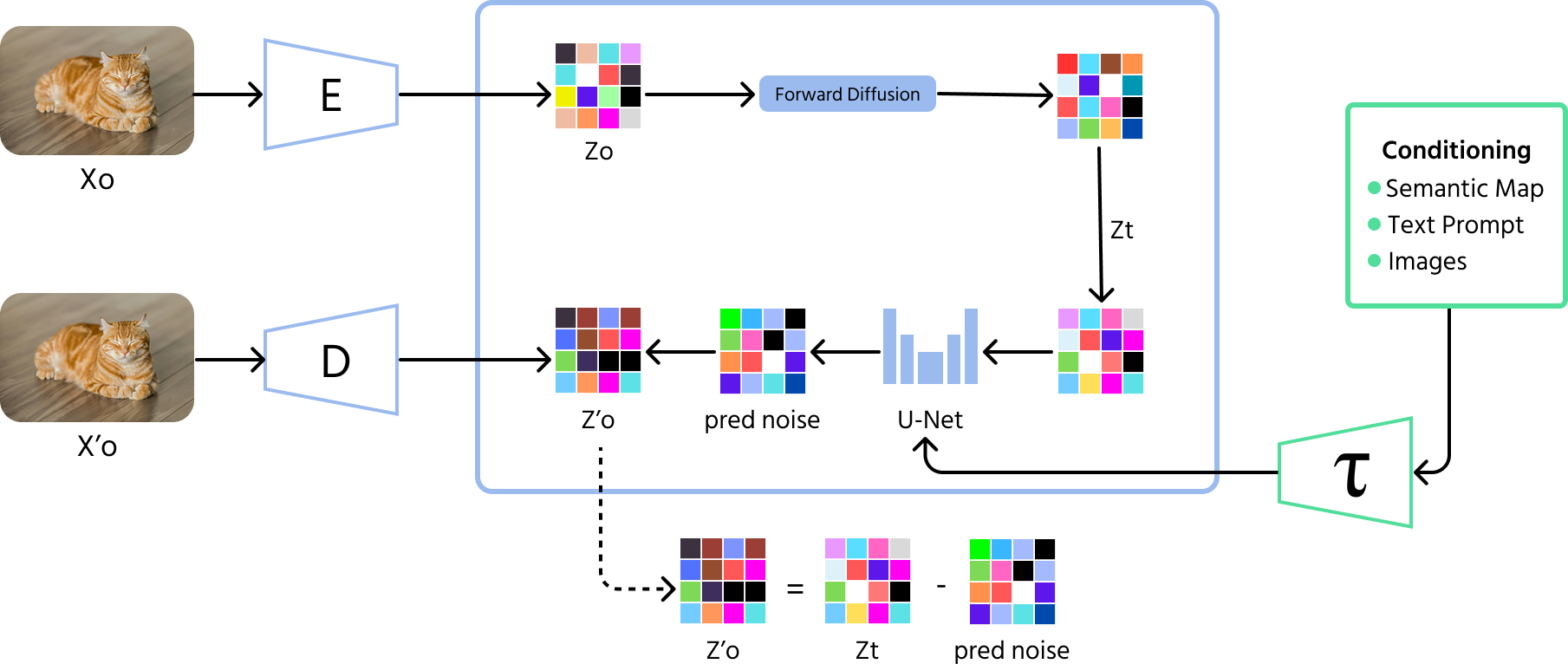
Hvordan diffusjonsmodeller fungerer
- Fremoverprosess (støytilføyelse): modellen starter med å legge til tilfeldig støy til et bilde over mange steg til det blir helt ugjenkjennelig;
- Omvendt prosess (støyfjerning): modellen lærer deretter å reversere denne prosessen, og fjerner gradvis støyen steg for steg for å gjenvinne et meningsfullt bilde;
- Trening: diffusjonsmodeller trenes til å forutsi og fjerne støy i hvert steg, noe som hjelper dem å generere klare og høyoppløselige bilder fra tilfeldig støy.
Et populært eksempel er MidJourney, DALL-E og Stable Diffusion, som er kjent for å lage realistiske og kunstneriske bilder. Diffusjonsmodeller brukes mye til AI-generert kunst, høyoppløselig bildesyntese og kreative designapplikasjoner.
Eksempler på bilder generert av diffusjonsmodeller

Realistisk bilde av en basketballspiller med skjegg i gul-lilla drakt som dunker og beseirer demoner i en basketballkamp, all handling foregår i helvete.

Et surrealistisk vakkert kunstnerisk foto av en hvit 1990 Volkswagen Golf GTI i en endeløs eng av hvite blomster i harmoni med naturen, midt i endeløse åser fulle av blomster, botanisk, naturlig lys, kunstnerisk, tåkete fotorealistisk surrealistisk ultradetaljert, kodak-film, naturlig lys, vidvinkelobjektiv, f 1.20

Maleri av beige puddelhund som ligger på grønn sofa med grønn og hvit stripete pute i stil med Fairfield Porter, abstrakt ekspresjonisme, med dristige penselstrøk på beige bakgrunn

Ekstremt nærbilde av huden til en middelhavs- eller latinamerikansk kvinne, med fokus på en kombinasjonshudtype med synlig oljethet i pannen og på nesen, mens kinnene fremstår tørrere og litt flassende. Porene er mer synlige i T-sonen, og det er en naturlig glans som reflekterer talgproduksjonen. Huden har en blanding av varme og gyldne undertoner, med ujevn tekstur på grunn av varierende fuktighetsnivåer. Mykt, naturlig lys fremhever den realistiske kontrasten mellom de tørre og oljete områdene. Bakgrunnen er uskarp, slik at oppmerksomheten holdes på hudtonen hennes.
Utfordringer og etiske bekymringer
Selv om AI-genererte bilder er imponerende, følger det med utfordringer:
- Manglende kontroll: AI genererer ikke alltid nøyaktig det brukeren ønsker;
- Datakraft: å lage AI-bilder av høy kvalitet krever dyre og kraftige datamaskiner;
- Skjevhet i AI-modeller: siden AI lærer fra eksisterende bilder, kan den noen ganger gjenta skjevheter som finnes i dataene.
Det finnes også etiske bekymringer:
- Hvem eier AI-kunst?: hvis en AI lager et kunstverk, eier personen som brukte AI-en det, eller tilhører det AI-selskapet?
- Falske bilder og deepfakes: GAN-er kan brukes til å lage falske bilder som ser ekte ut, noe som kan føre til feilinformasjon og personvernutfordringer.
Hvordan AI-bildegenerering brukes i dag
AI-genererte bilder har allerede stor innvirkning i ulike bransjer:
- Underholdning: videospill, filmer og animasjon bruker AI til å lage bakgrunner, karakterer og effekter;
- Mote: designere bruker AI til å skape nye klesstiler, og nettbutikker tilbyr virtuelle prøverom for kunder;
- Grafisk design: AI hjelper kunstnere og designere med å raskt lage logoer, plakater og markedsføringsmateriell.
Fremtiden for AI-bildegenerering
Etter hvert som AI-bildegenerering stadig forbedres, vil det fortsette å endre måten folk lager og bruker bilder på. Enten det gjelder kunst, næringsliv eller underholdning, åpner AI nye muligheter og gjør kreativt arbeid enklere og mer spennende.
1. Hva er hovedformålet med AI-bildegenerering?
2. Hvordan fungerer Generative Adversarial Networks (GANs)?
3. Hvilken AI-modell starter med tilfeldig støy og forbedrer bildet trinn for trinn?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
