Ankerbokser
Sveip for å vise menyen
Anchor box er en forhåndsdefinert avgrensningsboks med fast størrelse og sideforhold, plassert på bestemte posisjoner i et bilde.
Hvorfor brukes anchor boxes i objektdeteksjon
Anchor boxes er et grunnleggende konsept i moderne objektdeteksjonsmodeller som Faster R-CNN og YOLO. De fungerer som forhåndsdefinerte referansebokser som hjelper til med å oppdage objekter av ulike størrelser og sideforhold, noe som gjør deteksjonen raskere og mer pålitelig.
I stedet for å oppdage objekter fra bunnen av, bruker modellene anchor boxes som utgangspunkt, og justerer dem for å passe bedre til de oppdagede objektene. Denne tilnærmingen forbedrer effektivitet og nøyaktighet, spesielt ved deteksjon av objekter i ulike skalaer.
Forskjell mellom anchor box og bounding box
- Anchor Box: en forhåndsdefinert mal som fungerer som referanse under objektdeteksjon;
- Bounding Box: den endelige predikerte boksen etter at justeringer er gjort på en anchor box for å tilpasses det faktiske objektet.

I motsetning til avgrensningsbokser, som justeres dynamisk under prediksjon, er ankerbokser faste på bestemte posisjoner før objektdeteksjon utføres. Modeller lærer å forbedre ankerbokser ved å justere størrelse, posisjon og størrelsesforhold, slik at de til slutt blir til endelige avgrensningsbokser som nøyaktig representerer detekterte objekter.
Hvordan et nettverk genererer ankerbokser
Ankerbokser brukes ikke direkte på et bilde, men på funksjonskart som er hentet ut fra bildet. Etter funksjonsekstraksjon plasseres et sett med ankerbokser på disse funksjonskartene, med varierende størrelse og størrelsesforhold. Valg av form på ankerbokser er avgjørende og innebærer en balanse mellom å oppdage små og store objekter.
For å definere størrelser på ankerbokser benytter modeller vanligvis en kombinasjon av manuell utvelgelse og klyngingsalgoritmer som K-Means for å analysere datasettet og finne de vanligste objekttypene og størrelsene. Disse forhåndsdefinerte ankerboksene brukes deretter på ulike steder i funksjonskartene. For eksempel kan en objektdeteksjonsmodell bruke ankerbokser med størrelser (16x16), (32x32), (64x64), med størrelsesforhold som 1:1, 1:2, and 2:1.
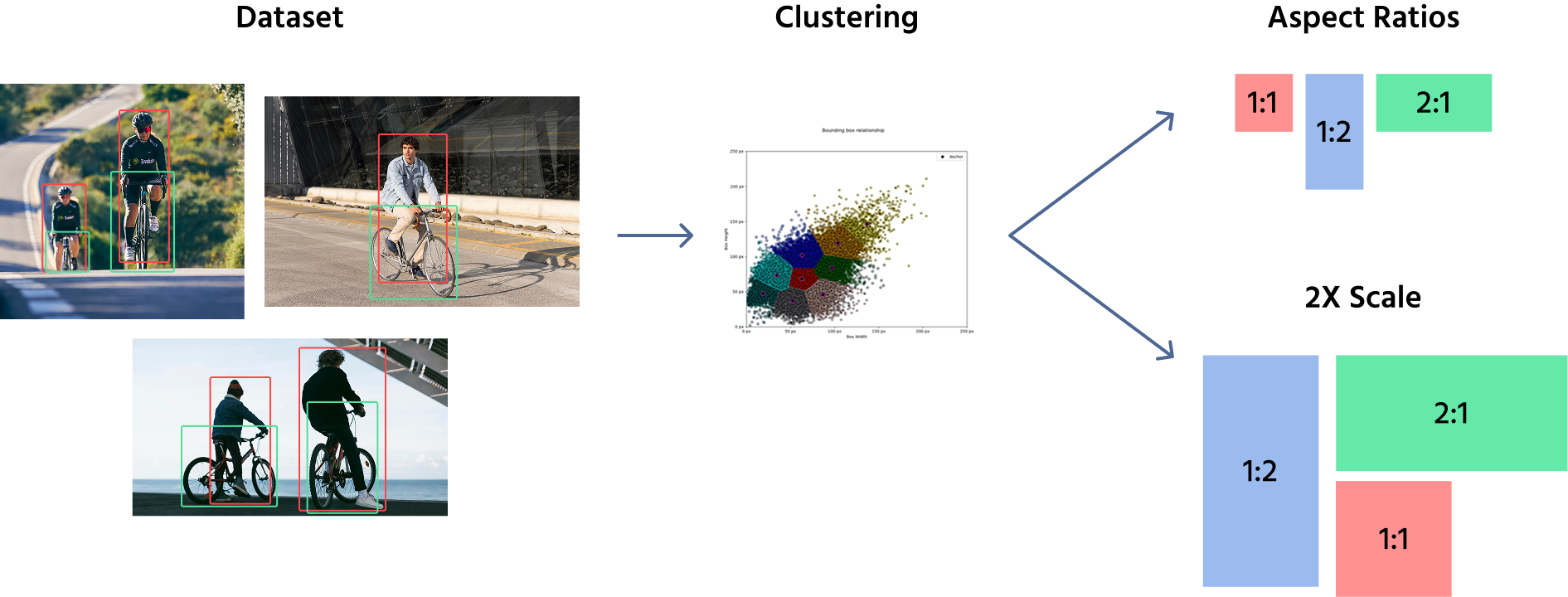
Når disse ankerboksene er definert, brukes de på feature maps, ikke det originale bildet. Modellen tildeler flere ankerbokser til hver posisjon i feature mapet, og dekker ulike former og størrelser. Under trening justerer nettverket ankerboksene ved å forutsi forskyvninger, og forbedrer dermed størrelse og posisjon for å tilpasse seg objektene bedre.
Fra ankerboks til avgrensningsboks
Når ankerbokser er tilordnet objekter, forutsier modellen forskyvninger for å forbedre dem. Disse forskyvningene inkluderer:
- Justering av boksens sentrumkoordinater;
- Skalering av bredde og høyde;
- Forskyvning av boksen for bedre tilpasning til objektet.
Ved å bruke disse transformasjonene konverterer modellen ankerbokser til endelige avgrensningsbokser som samsvarer tett med objektene i et bilde.
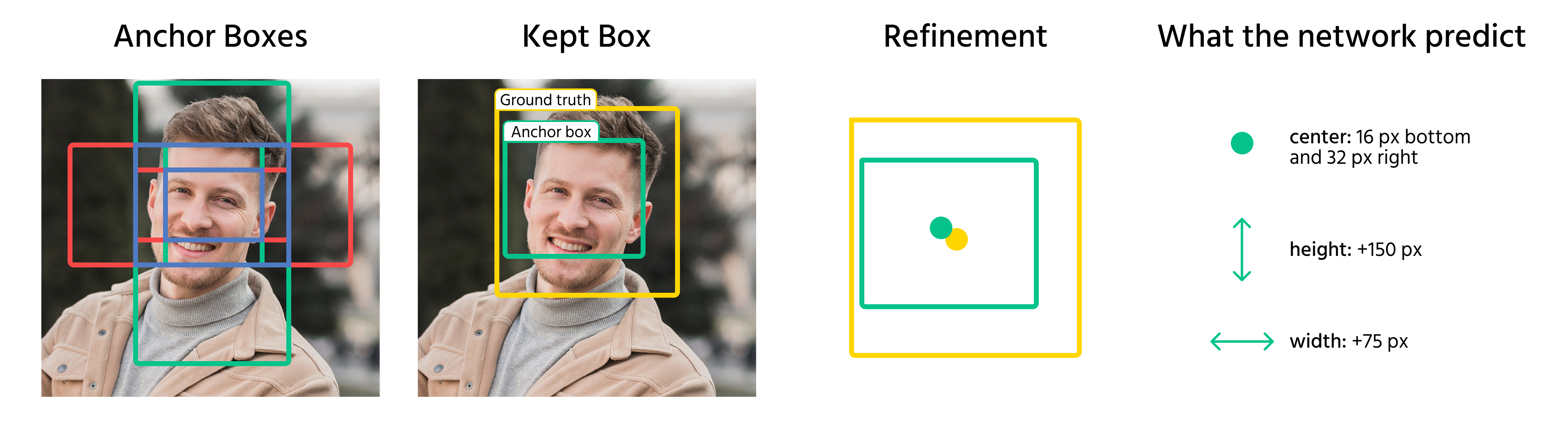
Tilnærminger uten bruk av ankere eller med redusert antall ankere
Selv om ankerbokser er mye brukt, finnes det modeller som forsøker å redusere avhengigheten av dem eller fjerne dem helt:
- Ankerfrie metoder: Modeller som
CenterNetogFCOSpredikerer objekters plassering direkte uten forhåndsdefinerte ankere, noe som reduserer kompleksiteten; - Reduserte anker-tilnærminger:
EfficientDetogYOLOv4optimaliserer antall brukte ankerbokser for å balansere deteksjonshastighet og nøyaktighet.
Disse tilnærmingene har som mål å forbedre effektiviteten i objektdeteksjon samtidig som høy ytelse opprettholdes, spesielt for sanntidsapplikasjoner.
Oppsummert er ankerbokser en sentral del av objektdeteksjon, og hjelper modeller med å oppdage objekter effektivt på tvers av ulike størrelser og størrelsesforhold. Nye fremskritt utforsker imidlertid måter å redusere eller eliminere ankerbokser for enda raskere og mer fleksibel deteksjon.
1. Hva er hovedrollen til anchor-bokser i objektdeteksjon?
2. Hvordan skiller anchor-bokser seg fra bounding-bokser?
3. Hvilken metode brukes ofte for å bestemme optimale størrelser på anchor-bokser?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Ankerbokser
Anchor box er en forhåndsdefinert avgrensningsboks med fast størrelse og sideforhold, plassert på bestemte posisjoner i et bilde.
Hvorfor brukes anchor boxes i objektdeteksjon
Anchor boxes er et grunnleggende konsept i moderne objektdeteksjonsmodeller som Faster R-CNN og YOLO. De fungerer som forhåndsdefinerte referansebokser som hjelper til med å oppdage objekter av ulike størrelser og sideforhold, noe som gjør deteksjonen raskere og mer pålitelig.
I stedet for å oppdage objekter fra bunnen av, bruker modellene anchor boxes som utgangspunkt, og justerer dem for å passe bedre til de oppdagede objektene. Denne tilnærmingen forbedrer effektivitet og nøyaktighet, spesielt ved deteksjon av objekter i ulike skalaer.
Forskjell mellom anchor box og bounding box
- Anchor Box: en forhåndsdefinert mal som fungerer som referanse under objektdeteksjon;
- Bounding Box: den endelige predikerte boksen etter at justeringer er gjort på en anchor box for å tilpasses det faktiske objektet.
I motsetning til avgrensningsbokser, som justeres dynamisk under prediksjon, er ankerbokser faste på bestemte posisjoner før objektdeteksjon utføres. Modeller lærer å forbedre ankerbokser ved å justere størrelse, posisjon og størrelsesforhold, slik at de til slutt blir til endelige avgrensningsbokser som nøyaktig representerer detekterte objekter.
Hvordan et nettverk genererer ankerbokser
Ankerbokser brukes ikke direkte på et bilde, men på funksjonskart som er hentet ut fra bildet. Etter funksjonsekstraksjon plasseres et sett med ankerbokser på disse funksjonskartene, med varierende størrelse og størrelsesforhold. Valg av form på ankerbokser er avgjørende og innebærer en balanse mellom å oppdage små og store objekter.
For å definere størrelser på ankerbokser benytter modeller vanligvis en kombinasjon av manuell utvelgelse og klyngingsalgoritmer som K-Means for å analysere datasettet og finne de vanligste objekttypene og størrelsene. Disse forhåndsdefinerte ankerboksene brukes deretter på ulike steder i funksjonskartene. For eksempel kan en objektdeteksjonsmodell bruke ankerbokser med størrelser (16x16), (32x32), (64x64), med størrelsesforhold som 1:1, 1:2, and 2:1.
Når disse ankerboksene er definert, brukes de på feature maps, ikke det originale bildet. Modellen tildeler flere ankerbokser til hver posisjon i feature mapet, og dekker ulike former og størrelser. Under trening justerer nettverket ankerboksene ved å forutsi forskyvninger, og forbedrer dermed størrelse og posisjon for å tilpasse seg objektene bedre.
Fra ankerboks til avgrensningsboks
Når ankerbokser er tilordnet objekter, forutsier modellen forskyvninger for å forbedre dem. Disse forskyvningene inkluderer:
- Justering av boksens sentrumkoordinater;
- Skalering av bredde og høyde;
- Forskyvning av boksen for bedre tilpasning til objektet.
Ved å bruke disse transformasjonene konverterer modellen ankerbokser til endelige avgrensningsbokser som samsvarer tett med objektene i et bilde.
Tilnærminger uten bruk av ankere eller med redusert antall ankere
Selv om ankerbokser er mye brukt, finnes det modeller som forsøker å redusere avhengigheten av dem eller fjerne dem helt:
- Ankerfrie metoder: Modeller som
CenterNetogFCOSpredikerer objekters plassering direkte uten forhåndsdefinerte ankere, noe som reduserer kompleksiteten; - Reduserte anker-tilnærminger:
EfficientDetogYOLOv4optimaliserer antall brukte ankerbokser for å balansere deteksjonshastighet og nøyaktighet.
Disse tilnærmingene har som mål å forbedre effektiviteten i objektdeteksjon samtidig som høy ytelse opprettholdes, spesielt for sanntidsapplikasjoner.
Oppsummert er ankerbokser en sentral del av objektdeteksjon, og hjelper modeller med å oppdage objekter effektivt på tvers av ulike størrelser og størrelsesforhold. Nye fremskritt utforsker imidlertid måter å redusere eller eliminere ankerbokser for enda raskere og mer fleksibel deteksjon.
Takk for tilbakemeldingene dine!
