Oversikt Over YOLO-Modellen
Sveip for å vise menyen
YOLO (You Only Look Once)-algoritmen er en rask og effektiv modell for objektdeteksjon. I motsetning til tradisjonelle tilnærminger som R-CNN, som benytter flere steg, behandler YOLO hele bildet i én enkelt gjennomgang, noe som gjør den ideell for sanntidsapplikasjoner.
Hvordan YOLO skiller seg fra R-CNN-tilnærminger
Tradisjonelle metoder for objektdeteksjon, som R-CNN og dens varianter, benytter en tostegsprosess: først genereres region proposals, deretter klassifiseres hver foreslåtte region. Selv om denne tilnærmingen er effektiv, er den beregningstung og gir tregere inferens, noe som gjør den mindre egnet for sanntidsapplikasjoner.
YOLO (You Only Look Once) benytter en radikalt annerledes metode. Den deler inngangsbildet inn i et rutenett og predikerer avgrensningsbokser og klasse-sannsynligheter for hver celle i én enkelt gjennomgang. Denne utformingen gjør objektdeteksjon til et enkelt regresjonsproblem, slik at YOLO oppnår sanntidsytelse.
I motsetning til R-CNN-baserte metoder som kun fokuserer på lokale områder, behandler YOLO hele bildet samtidig, noe som gjør det mulig å fange opp global kontekstuell informasjon. Dette gir bedre ytelse ved deteksjon av flere eller overlappende objekter, samtidig som høy hastighet og nøyaktighet opprettholdes.
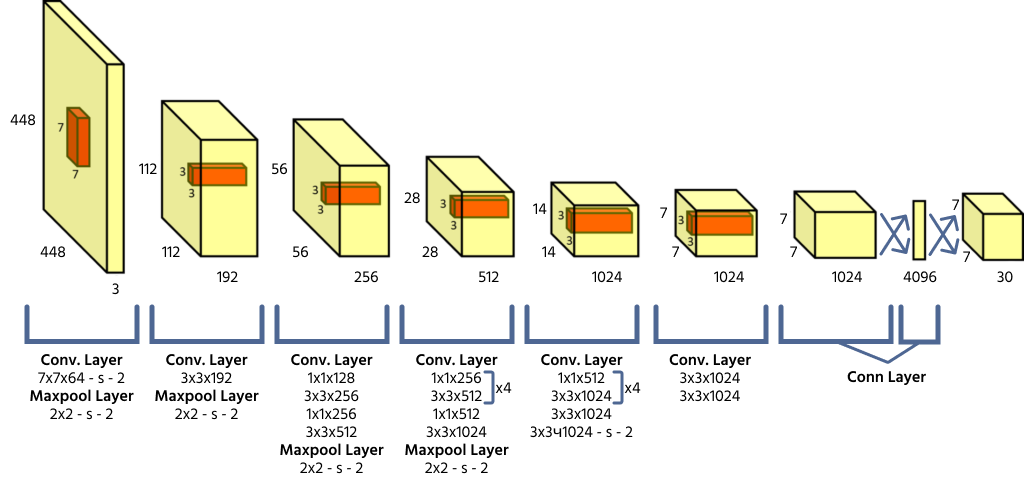
YOLO-arkitektur og rutenettbaserte prediksjoner
YOLO deler et inngangsbilde inn i et S × S-rutenett, der hver rutenettcelle er ansvarlig for å detektere objekter hvis sentrum faller innenfor cellen. Hver celle predikerer koordinater for avgrensningsboks (x, y, bredde, høyde), en objekttillitsverdi og klasse-sannsynligheter. Siden YOLO behandler hele bildet i én gjennomgang, er den svært effektiv sammenlignet med tidligere modeller for objektdeteksjon.
Tapefunksjon og klassesikkerhetspoeng
YOLO optimaliserer deteksjonsnøyaktighet ved hjelp av en tilpasset tapefunksjon, som inkluderer:
- Lokaliserings-tap: måler nøyaktigheten til avgrensningsbokser;
- Konfidens-tap: sikrer at prediksjoner korrekt indikerer tilstedeværelse av objekt;
- Klassifiseringstap: vurderer hvor godt den predikerte klassen samsvarer med den faktiske klassen.
For å forbedre resultatene benytter YOLO ankerbokser og non-max suppression (NMS) for å fjerne overflødige deteksjoner.
Fordeler med YOLO: Avveining mellom hastighet og nøyaktighet
YOLOs hovedfordel er hastighet. Siden deteksjon skjer i én enkelt gjennomgang, er YOLO mye raskere enn R-CNN-baserte metoder, noe som gjør det egnet for sanntidsapplikasjoner som autonom kjøring og overvåkning. Tidlige versjoner av YOLO hadde utfordringer med deteksjon av små objekter, noe som senere versjoner har forbedret.
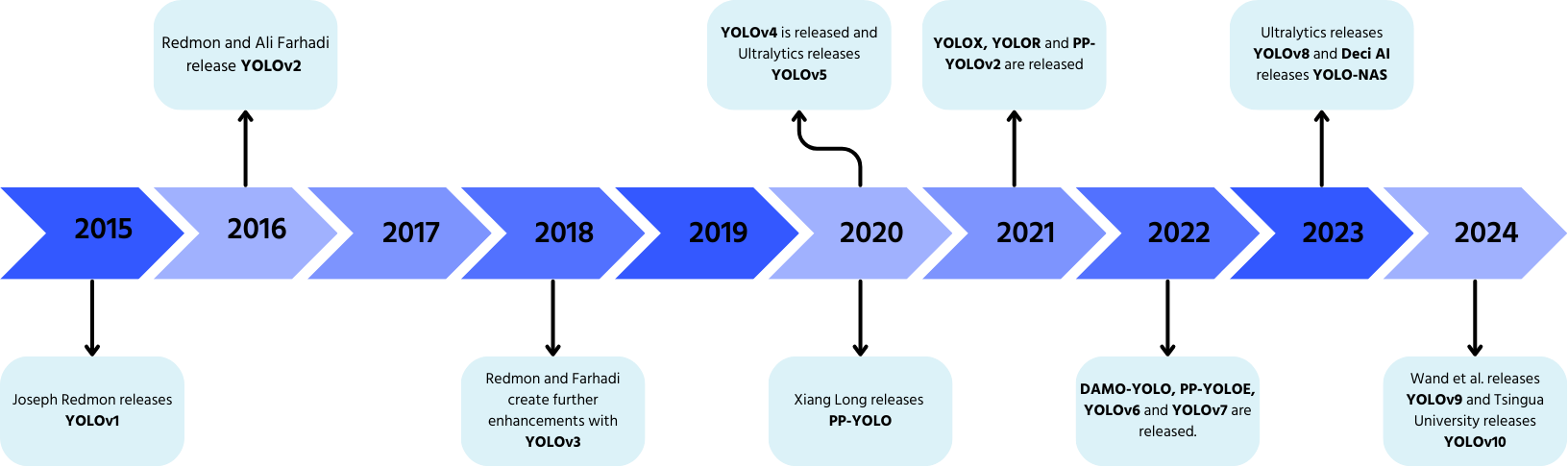
YOLO: En kort historikk
YOLO, utviklet av Joseph Redmon og Ali Farhadi i 2015, revolusjonerte objektdeteksjon med én-pass prosessering.
- YOLOv2 (2016): la til batch-normalisering, ankerbokser og dimensjonsklynger;
- YOLOv3 (2018): introduserte en mer effektiv ryggrad, flere ankre og romlig pyramidepooling;
- YOLOv4 (2020): la til Mosaic dataforsterkning, et ankerfritt deteksjonshode og en ny tapsfunksjon;
- YOLOv5: forbedret ytelse med hyperparameteroptimalisering, eksperimentsporing og automatisk eksport;
- YOLOv6 (2022): åpen kildekode fra Meituan og brukt i autonome leveringsroboter;
- YOLOv7: utvidet funksjonalitet til å inkludere posestimering;
- YOLOv8 (2023): forbedret hastighet, fleksibilitet og effektivitet for visuelle AI-oppgaver;
- YOLOv9: introduserte Programmable Gradient Information (PGI) og Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: utviklet av Tsinghua University, eliminerer Non-Maximum Suppression (NMS) med et ende-til-ende deteksjonshode;
- YOLOv11: den nyeste modellen med topp moderne ytelse innen objektdeteksjon, segmentering og klassifisering.
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
