Objektdeteksjon
Sveip for å vise menyen
Objektdeteksjon er et viktig fremskritt utover bildeklassifisering og lokalisering. Mens klassifisering avgjør hvilket objekt som er til stede i et bilde, og lokalisering identifiserer hvor et enkelt objekt befinner seg, utvider objektdeteksjon dette ved å gjenkjenne flere objekter og deres plasseringer i et bilde.
Hva gjør objektdeteksjon annerledes?
I motsetning til klassifisering, som tildeler én etikett til et helt bilde, innebærer objektdeteksjon både klassifisering og lokalisering for flere objekter. En deteksjonsmodell må forutsi avgrensningsbokser rundt hvert objekt og klassifisere dem korrekt. Dette gjør objektdeteksjon til en mer kompleks og ressurskrevende oppgave enn enkel klassifisering.

Sliding Window-metoden og dens begrensninger
En tradisjonell metode for objektdeteksjon er sliding window-metoden, der et vindu med fast størrelse beveger seg over et bilde for å klassifisere hver seksjon. Selv om metoden er konseptuelt enkel, har den flere begrensninger:
- Krevende beregningsmessig: krever skanning av bildet på flere skalaer og posisjoner, noe som gir høy behandlingstid;
- Stive vindusstørrelser: objekter varierer i størrelse og sideforhold, noe som gjør vinduer med fast størrelse ineffektive;
- Redundante beregninger: overlappende vinduer behandler gjentatte ganger lignende bilderegioner, noe som sløser med ressurser.
På grunn av disse ineffektivitetene har dyp læringsbaserte objektdeteksjonsmetoder i stor grad erstattet sliding window-metoden.

Regionbaserte metoder: Selective Search og Region Proposal Networks (RPN)
For å forbedre effektiviteten foreslår regionbaserte metoder Regions of Interest (RoIs) i stedet for å skanne hele bildet. To hovedteknikker er:
-
Selective search: en tradisjonell metode som grupperer lignende piksler til regionforslag, og reduserer antall prediksjoner av avgrensningsbokser. Selv om den er mer effektiv enn sliding window, er den fortsatt treg;
-
Region proposal networks (RPNs): brukt i Faster R-CNN, benytter RPNs et nevralt nettverk for å generere potensielle objektsregioner direkte, noe som gir betydelig bedre hastighet og nøyaktighet enn selective search.
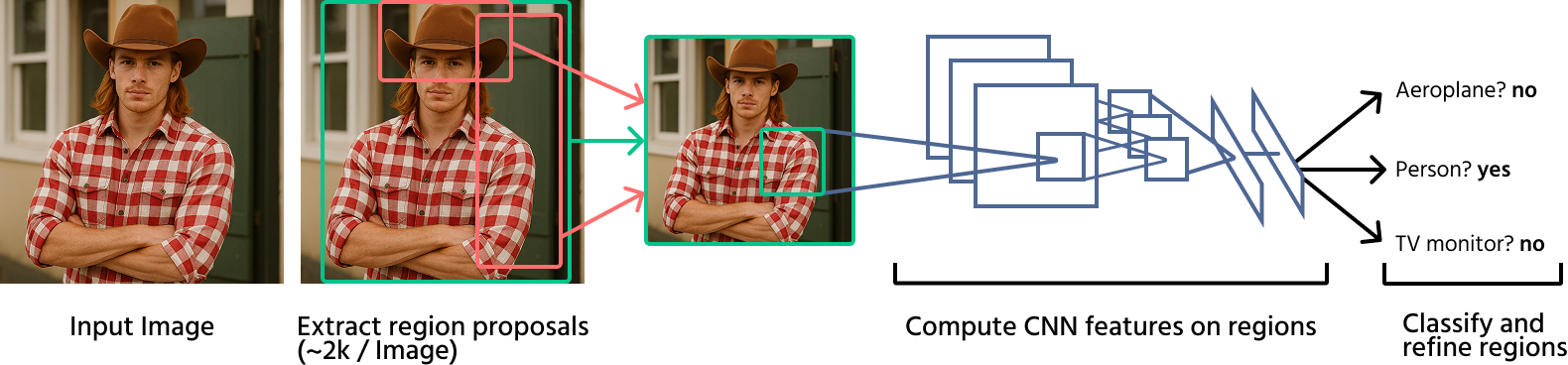
Tidlige dyp læringsbaserte tilnærminger
Dyp læring revolusjonerte objektdeteksjon ved å introdusere konvolusjonsnevrale nettverk (CNN-er) i deteksjonsprosesser. Noen av de banebrytende modellene inkluderer:
-
R-CNN (Regions with CNNs): denne metoden anvender et CNN på hvert regionforslag generert av selektivt søk. Selv om den er betydelig mer nøyaktig enn tradisjonelle metoder, er den beregningsmessig treg på grunn av gjentatte CNN-evalueringer;
-
Fast R-CNN: en forbedring over R-CNN, denne modellen prosesserer hele bildet med et CNN først og bruker deretter RoI pooling for å trekke ut egenskaper for klassifisering, noe som øker deteksjonshastigheten;
-
Faster R-CNN: introduserer region proposal networks (RPN-er) for å erstatte selektivt søk, noe som gjør objektdeteksjon raskere og mer nøyaktig ved å integrere generering av regionforslag i selve nevrale nettverket.
Objektdeteksjon bygger på klassifisering og lokalisering, og gjør det mulig for modeller å gjenkjenne flere objekter i et bilde. Tradisjonelle metoder som glidende vinduer har blitt erstattet av mer effektive regionbaserte teknikker som R-CNN og dens etterfølgere. Faster R-CNN, med bruk av region proposal networks, representerer et betydelig steg mot sanntids, høy-presisjons objektdeteksjon. Videre vil mer avanserte teknikker som YOLO og SSD ytterligere forbedre deteksjonshastighet og effektivitet.
1. Hva er hovedfordelen med Faster R-CNN sammenlignet med Fast R-CNN?
2. Hvorfor er sliding window-metoden ineffektiv for objektdeteksjon?
3. Hvilken av følgende er en dyp læringsbasert metode for objektdeteksjon?
Takk for tilbakemeldingene dine!
Spør AI
Spør AI

Spør om hva du vil, eller prøv ett av de foreslåtte spørsmålene for å starte chatten vår
Objektdeteksjon
Objektdeteksjon er et viktig fremskritt utover bildeklassifisering og lokalisering. Mens klassifisering avgjør hvilket objekt som er til stede i et bilde, og lokalisering identifiserer hvor et enkelt objekt befinner seg, utvider objektdeteksjon dette ved å gjenkjenne flere objekter og deres plasseringer i et bilde.
Hva gjør objektdeteksjon annerledes?
I motsetning til klassifisering, som tildeler én etikett til et helt bilde, innebærer objektdeteksjon både klassifisering og lokalisering for flere objekter. En deteksjonsmodell må forutsi avgrensningsbokser rundt hvert objekt og klassifisere dem korrekt. Dette gjør objektdeteksjon til en mer kompleks og ressurskrevende oppgave enn enkel klassifisering.
Sliding Window-metoden og dens begrensninger
En tradisjonell metode for objektdeteksjon er sliding window-metoden, der et vindu med fast størrelse beveger seg over et bilde for å klassifisere hver seksjon. Selv om metoden er konseptuelt enkel, har den flere begrensninger:
- Krevende beregningsmessig: krever skanning av bildet på flere skalaer og posisjoner, noe som gir høy behandlingstid;
- Stive vindusstørrelser: objekter varierer i størrelse og sideforhold, noe som gjør vinduer med fast størrelse ineffektive;
- Redundante beregninger: overlappende vinduer behandler gjentatte ganger lignende bilderegioner, noe som sløser med ressurser.
På grunn av disse ineffektivitetene har dyp læringsbaserte objektdeteksjonsmetoder i stor grad erstattet sliding window-metoden.
Regionbaserte metoder: Selective Search og Region Proposal Networks (RPN)
For å forbedre effektiviteten foreslår regionbaserte metoder Regions of Interest (RoIs) i stedet for å skanne hele bildet. To hovedteknikker er:
-
Selective search: en tradisjonell metode som grupperer lignende piksler til regionforslag, og reduserer antall prediksjoner av avgrensningsbokser. Selv om den er mer effektiv enn sliding window, er den fortsatt treg;
-
Region proposal networks (RPNs): brukt i Faster R-CNN, benytter RPNs et nevralt nettverk for å generere potensielle objektsregioner direkte, noe som gir betydelig bedre hastighet og nøyaktighet enn selective search.
Tidlige dyp læringsbaserte tilnærminger
Dyp læring revolusjonerte objektdeteksjon ved å introdusere konvolusjonsnevrale nettverk (CNN-er) i deteksjonsprosesser. Noen av de banebrytende modellene inkluderer:
-
R-CNN (Regions with CNNs): denne metoden anvender et CNN på hvert regionforslag generert av selektivt søk. Selv om den er betydelig mer nøyaktig enn tradisjonelle metoder, er den beregningsmessig treg på grunn av gjentatte CNN-evalueringer;
-
Fast R-CNN: en forbedring over R-CNN, denne modellen prosesserer hele bildet med et CNN først og bruker deretter RoI pooling for å trekke ut egenskaper for klassifisering, noe som øker deteksjonshastigheten;
-
Faster R-CNN: introduserer region proposal networks (RPN-er) for å erstatte selektivt søk, noe som gjør objektdeteksjon raskere og mer nøyaktig ved å integrere generering av regionforslag i selve nevrale nettverket.
Objektdeteksjon bygger på klassifisering og lokalisering, og gjør det mulig for modeller å gjenkjenne flere objekter i et bilde. Tradisjonelle metoder som glidende vinduer har blitt erstattet av mer effektive regionbaserte teknikker som R-CNN og dens etterfølgere. Faster R-CNN, med bruk av region proposal networks, representerer et betydelig steg mot sanntids, høy-presisjons objektdeteksjon. Videre vil mer avanserte teknikker som YOLO og SSD ytterligere forbedre deteksjonshastighet og effektivitet.
Takk for tilbakemeldingene dine!
