Overzicht van Activatiefuncties
Veeg om het menu te tonen
Waarom activatiefuncties cruciaal zijn in CNN's
Activatiefuncties introduceren non-lineariteit in CNN's, waardoor ze complexe patronen kunnen leren die een eenvoudig lineair model niet kan bereiken. Zonder activatiefuncties zouden CNN's moeite hebben om ingewikkelde relaties in data te detecteren, wat hun effectiviteit bij beeldherkenning en classificatie beperkt. De juiste activatiefunctie beïnvloedt de trainingssnelheid, stabiliteit en algehele prestaties.
Veelvoorkomende activatiefuncties
- ReLU (rectified linear unit): de meest gebruikte activatiefunctie in CNN's. Deze geeft alleen positieve waarden door en zet alle negatieve invoer op nul, wat computationeel efficiënt is en het verdwijnen van gradiënten voorkomt. Sommige neuronen kunnen echter inactief worden door het "dode ReLU"-probleem;

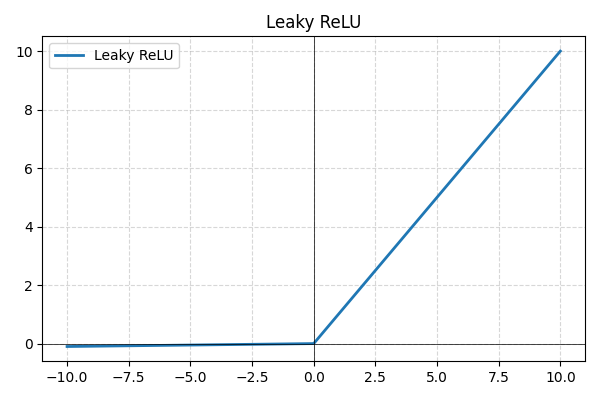
- Leaky ReLU: een variant van ReLU die kleine negatieve waarden toestaat in plaats van deze op nul te zetten, waardoor inactieve neuronen worden voorkomen en de gradiëntenstroom wordt verbeterd;
- Sigmoid: comprimeert invoerwaarden tot een bereik tussen 0 en 1, waardoor het geschikt is voor binaire classificatie. Heeft echter last van verdwijnende gradiënten in diepe netwerken;

- Tanh: vergelijkbaar met Sigmoid, maar geeft waarden tussen -1 en 1, waardoor activaties rond nul worden gecentreerd;

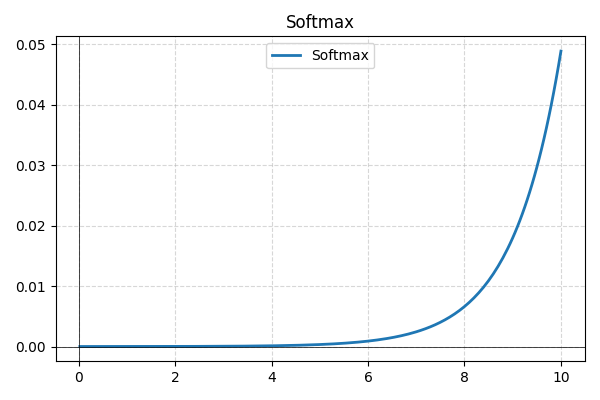
- Softmax: doorgaans gebruikt in de laatste laag voor multi-class classificatie; Softmax zet ruwe netwerkuitvoer om in waarschijnlijkheden, waarbij deze optellen tot één voor betere interpretatie.
De juiste activatiefunctie kiezen
ReLU is de standaardkeuze voor verborgen lagen vanwege de efficiëntie en sterke prestaties, terwijl Leaky ReLU een betere optie is wanneer neuron-inactiviteit een probleem wordt. Sigmoid en Tanh worden over het algemeen vermeden in diepe CNN's, maar kunnen nog steeds nuttig zijn in specifieke toepassingen. Softmax blijft essentieel voor multi-class classificatietaken en zorgt voor duidelijke, op waarschijnlijkheid gebaseerde voorspellingen.
Het selecteren van de juiste activatiefunctie is cruciaal voor het optimaliseren van de prestaties van CNN's, het balanceren van efficiëntie en het voorkomen van problemen zoals vervaagde of exploderende gradiënten. Elke functie draagt op unieke wijze bij aan hoe een netwerk visuele data verwerkt en leert.
1. Waarom heeft ReLU de voorkeur boven Sigmoid in diepe CNN's?
2. Welke activatiefunctie wordt vaak gebruikt in de laatste laag van een multi-class classificatie CNN?
3. Wat is het belangrijkste voordeel van Leaky ReLU ten opzichte van standaard ReLU?
Bedankt voor je feedback!
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
