Implementatie van Word2Vec
Veeg om het menu te tonen
Nu we begrijpen hoe Word2Vec werkt, gaan we het implementeren met Python. De Gensim-bibliotheek, een krachtig open-source hulpmiddel voor natuurlijke taalverwerking, biedt een eenvoudige implementatie via de Word2Vec-klasse in gensim.models.
Gegevens voorbereiden
Word2Vec vereist dat de tekstgegevens getokeniseerd zijn, oftewel opgesplitst in een lijst van lijsten waarbij elke binnenste lijst woorden uit een specifieke zin bevat. In dit voorbeeld gebruiken we de roman Emma van de Engelse auteur Jane Austen als corpus. We laden een CSV-bestand met voorbewerkte zinnen en splitsen vervolgens elke zin in woorden:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() past de .split()-methode toe op elke zin in de kolom 'Sentence', wat resulteert in een lijst van woorden voor elke zin. Aangezien de zinnen al vooraf zijn verwerkt, met woorden gescheiden door spaties, is de .split()-methode voldoende voor deze tokenisatie.
Het trainen van het Word2Vec-model
Nu richten we ons op het trainen van het Word2Vec-model met behulp van de getokeniseerde data. De Word2Vec-klasse biedt verschillende parameters voor aanpassing. In de praktijk wordt meestal met de volgende parameters gewerkt:
vector_size(standaard 100): de dimensionaliteit of grootte van de woordvectoren;window(standaard 5): de grootte van het contextvenster;min_count(standaard 5): woorden die minder vaak voorkomen dan deze waarde worden genegeerd;sg(standaard 0): het te gebruiken modelarchitectuur (1 voor Skip-gram, 0 voor CBoW).cbow_mean(standaard 1): specificeert of de CBoW inputcontext wordt opgeteld (0) of gemiddeld (1)
Wat betreft de modelarchitecturen: CBoW is geschikt voor grotere datasets en situaties waarin rekenefficiëntie belangrijk is. Skip-gram is daarentegen te verkiezen voor taken die een gedetailleerd begrip van woordcontext vereisen, met name effectief bij kleinere datasets of bij het werken met zeldzame woorden.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Hier stellen we de embedding-grootte in op 200, de contextvenstergrootte op 5, en nemen we alle woorden op door min_count=1 te gebruiken. Door sg=0 in te stellen, kiezen we voor het CBoW-model.
Het kiezen van de juiste embedding-grootte en contextvenster vereist afwegingen. Grotere embeddings vangen meer betekenis, maar verhogen de rekenkosten en het risico op overfitting. Kleinere contextvensters zijn beter in het vastleggen van syntaxis, terwijl grotere beter zijn in het vastleggen van semantiek.
Vergelijkbare Woorden Vinden
Zodra woorden als vectoren worden weergegeven, kunnen we ze vergelijken om de gelijkenis te meten. Hoewel het gebruik van afstand een optie is, draagt de richting van een vector vaak meer semantische betekenis dan de grootte, vooral bij woordembeddings.
Het direct gebruiken van een hoek als gelijkenismaat is echter niet zo handig. In plaats daarvan kunnen we de cosinus van de hoek tussen twee vectoren gebruiken, ook wel bekend als cosinusgelijkenis. Deze varieert van -1 tot 1, waarbij hogere waarden op een sterkere gelijkenis duiden. Deze aanpak richt zich op hoe goed de vectoren zijn uitgelijnd, ongeacht hun lengte, waardoor het ideaal is voor het vergelijken van woordbetekenissen. Hier volgt een illustratie:
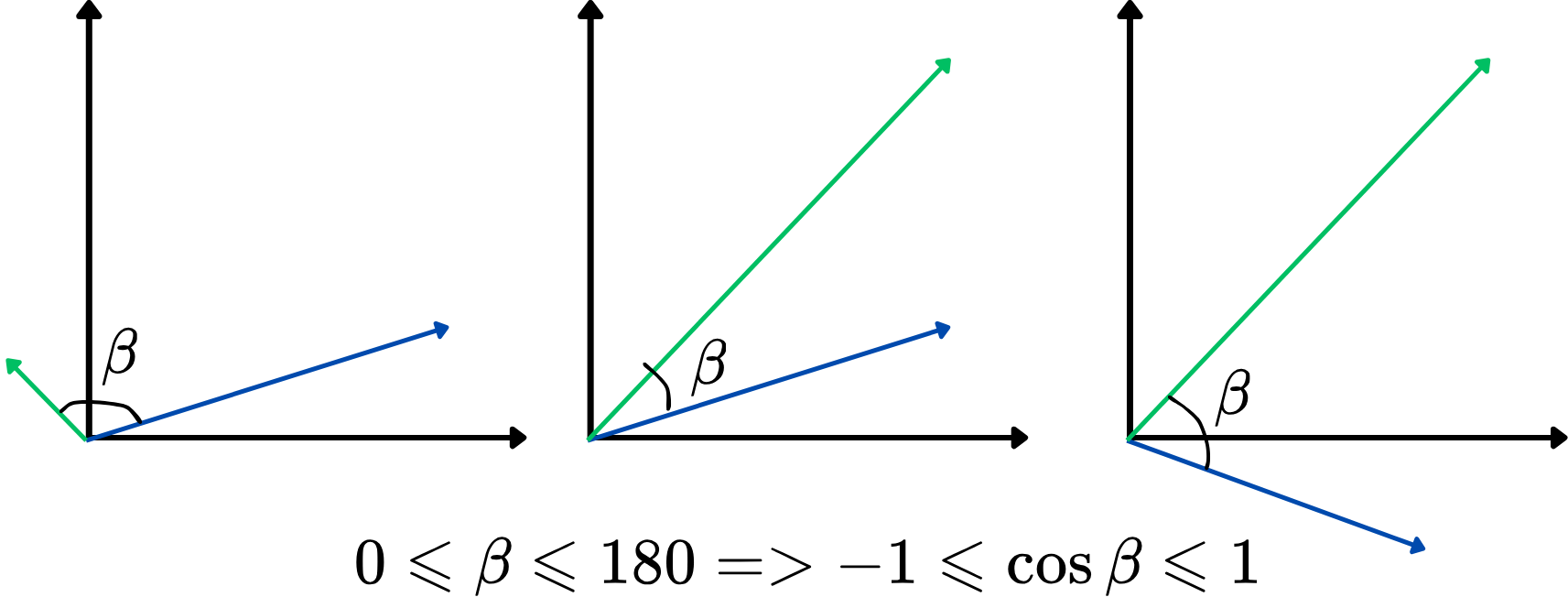
Hoe hoger de cosinusovereenkomst, hoe meer de twee vectoren op elkaar lijken, en omgekeerd. Bijvoorbeeld, als twee woordvectoren een cosinusovereenkomst hebben die dicht bij 1 ligt (de hoek dicht bij 0 graden), duidt dit erop dat ze nauw verwant of vergelijkbaar zijn in context binnen de vectorruimte.
Laten we nu de top-5 meest vergelijkbare woorden met het woord "man" vinden met behulp van cosinusovereenkomst:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv geeft toegang tot de woordvectoren van het getrainde model, terwijl de methode .most_similar() de woorden vindt waarvan de embeddings het dichtst bij de embedding van het opgegeven woord liggen, op basis van cosinusgelijkenis. De parameter topn bepaalt het aantal top-N vergelijkbare woorden dat wordt geretourneerd.
Bedankt voor je feedback!
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
