Implementatie van Neurale Netwerken
Overzicht van een Basis Neuraal Netwerk
Je hebt nu een punt bereikt waarop je beschikt over de essentiële kennis van TensorFlow om zelf neurale netwerken te maken. Hoewel de meeste neurale netwerken in de praktijk complex zijn en doorgaans worden gebouwd met hoog-niveau bibliotheken zoals Keras, zullen we een basisnetwerk opzetten met fundamentele TensorFlow-tools. Deze aanpak biedt praktische ervaring met laag-niveau tensor-manipulatie en helpt ons de onderliggende processen te begrijpen.
In eerdere cursussen zoals Introductie tot Neurale Netwerken herinner je je misschien nog hoeveel tijd en moeite het kostte om zelfs een eenvoudig neuraal netwerk te bouwen, waarbij elke neuron afzonderlijk werd behandeld.

TensorFlow vereenvoudigt dit proces aanzienlijk. Door gebruik te maken van tensors kun je complexe berekeningen inkapselen, waardoor de noodzaak voor ingewikkelde code afneemt. Onze belangrijkste taak is het opzetten van een sequentiële pijplijn van tensorbewerkingen.
Hier volgt een korte opfrissing van de stappen om een trainingsproces voor een neuraal netwerk te starten:
Gegevensvoorbereiding en modelcreatie
De beginfase van het trainen van een neuraal netwerk omvat het voorbereiden van de gegevens, waaronder zowel de inputs als outputs waarvan het netwerk zal leren. Daarnaast worden de hyperparameters van het model vastgesteld - dit zijn de parameters die gedurende het hele trainingsproces constant blijven. De gewichten worden geïnitialiseerd, meestal getrokken uit een normale verdeling, en de biases, die vaak op nul worden gezet.
Voorwaartse propagatie
Bij voorwaartse propagatie volgt elke laag van het netwerk doorgaans deze stappen:
- Vermenigvuldig de input van de laag met de gewichten.
- Tel een bias op bij het resultaat.
- Pas een activatiefunctie toe op deze som.
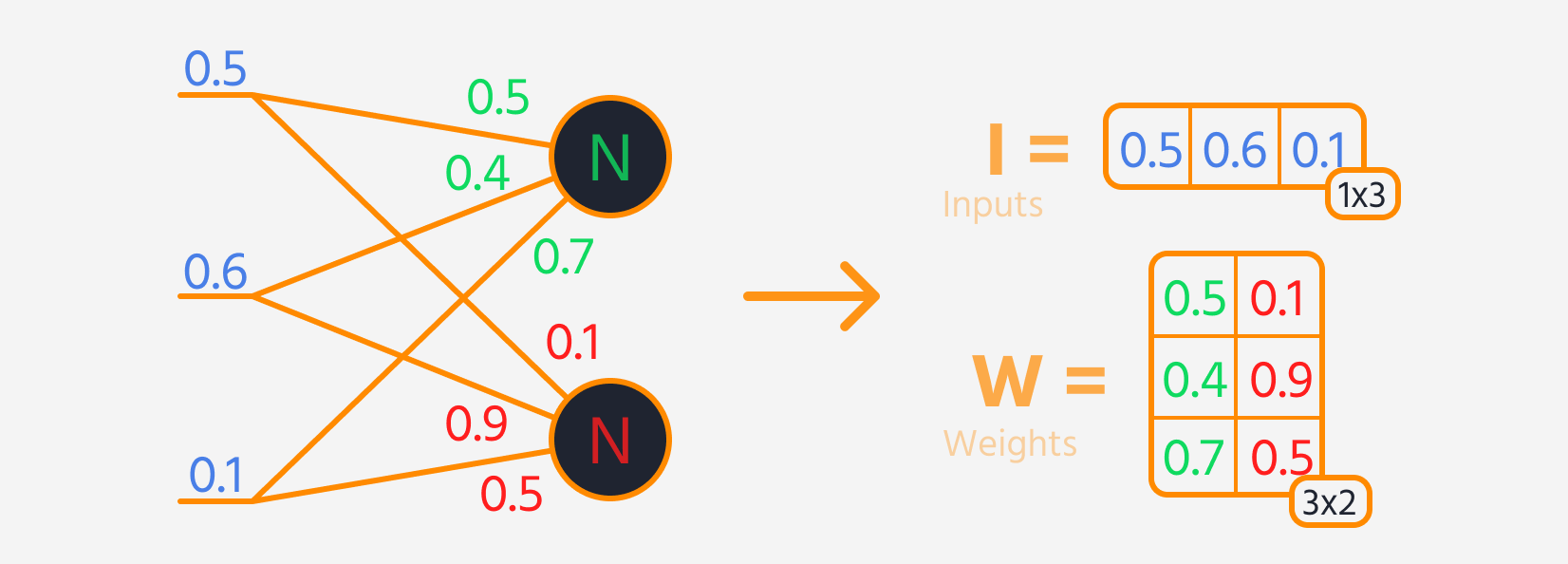
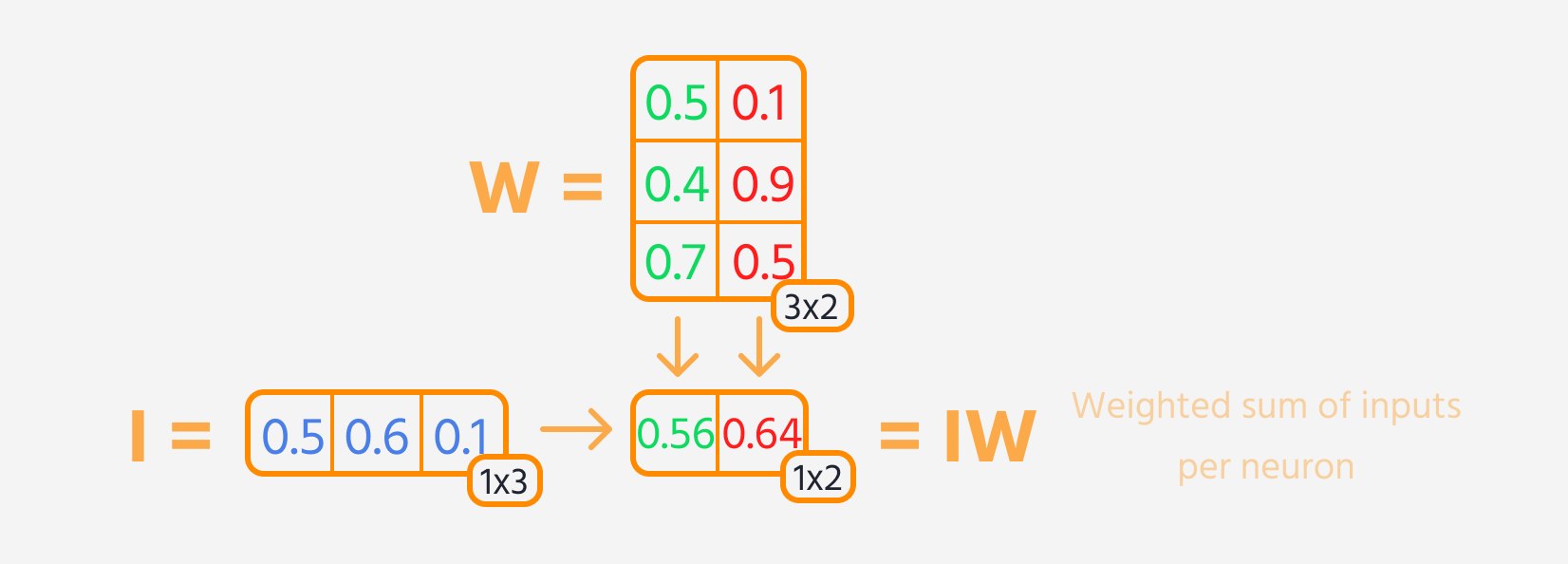
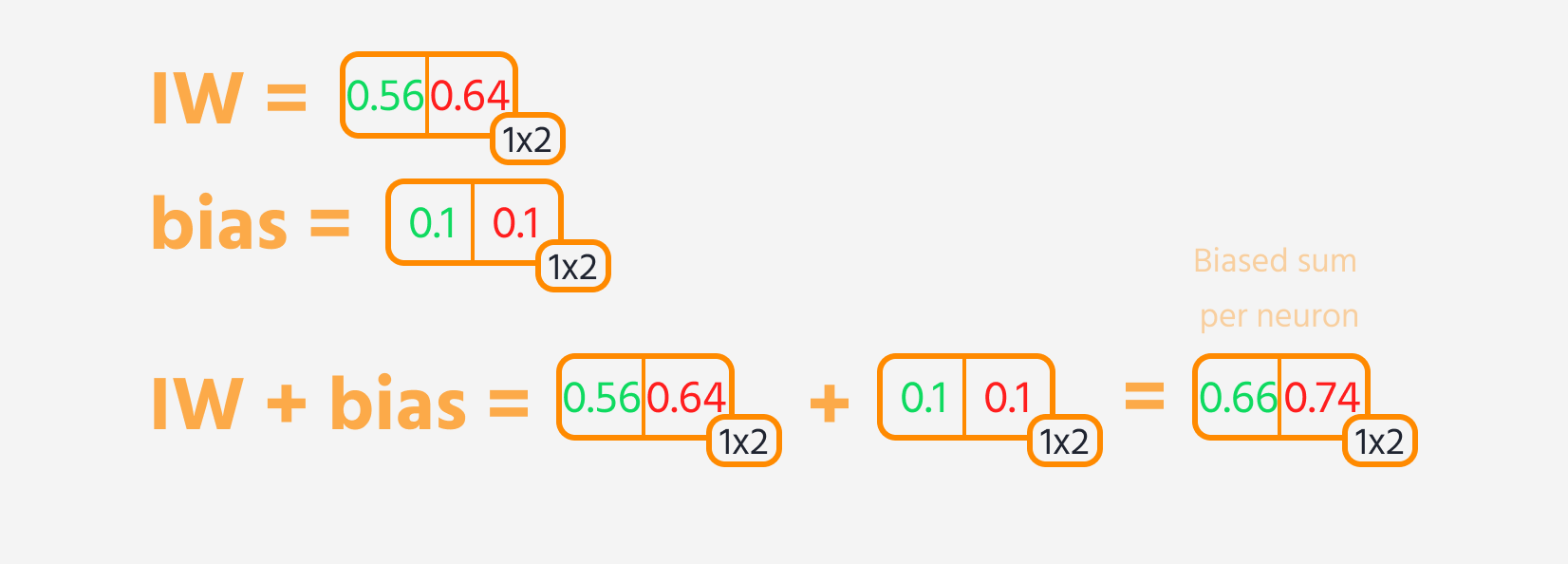


Vervolgens kan de verliesfunctie worden berekend.
Achterwaartse propagatie
De volgende stap is achterwaartse propagatie, waarbij de gewichten en biases worden aangepast op basis van hun invloed op de verliesfunctie. Deze invloed wordt weergegeven door de gradiënt, die automatisch wordt berekend door TensorFlow's Gradient Tape. De gewichten en biases worden bijgewerkt door de gradiënt, geschaald met het leerpercentage, af te trekken.
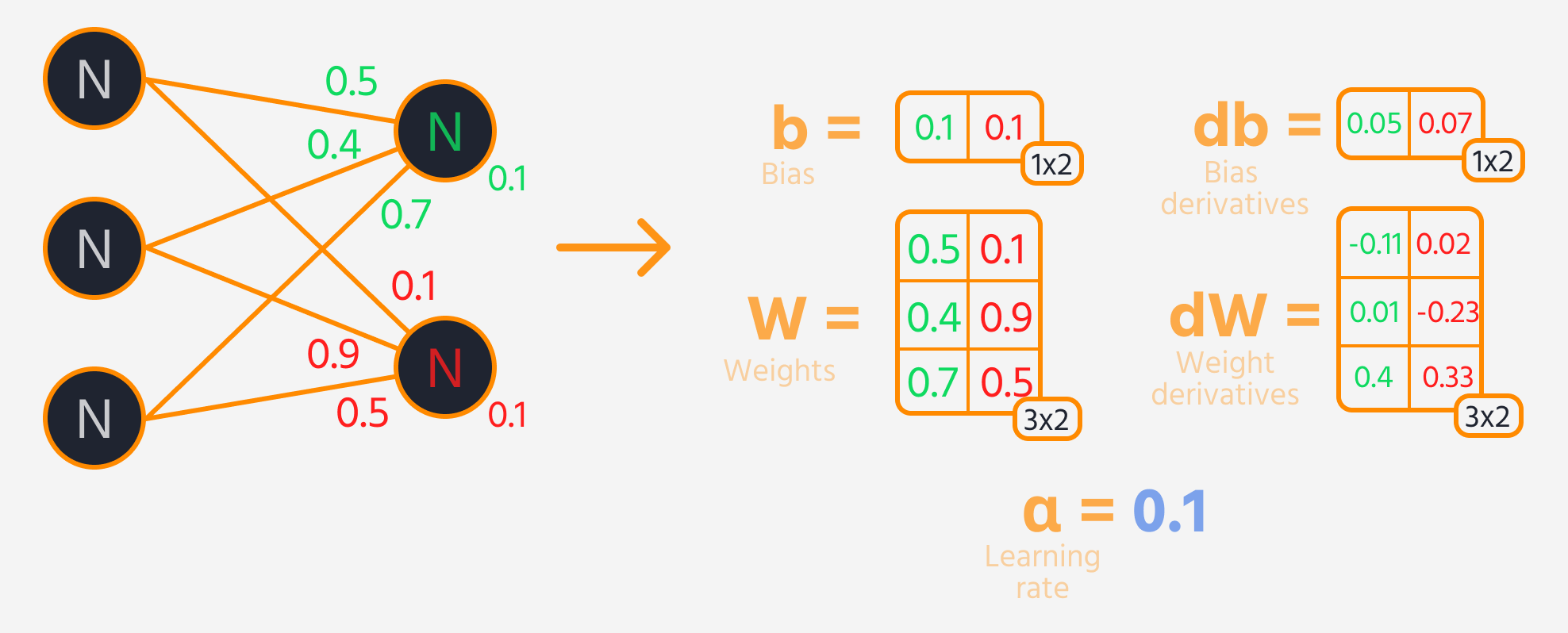
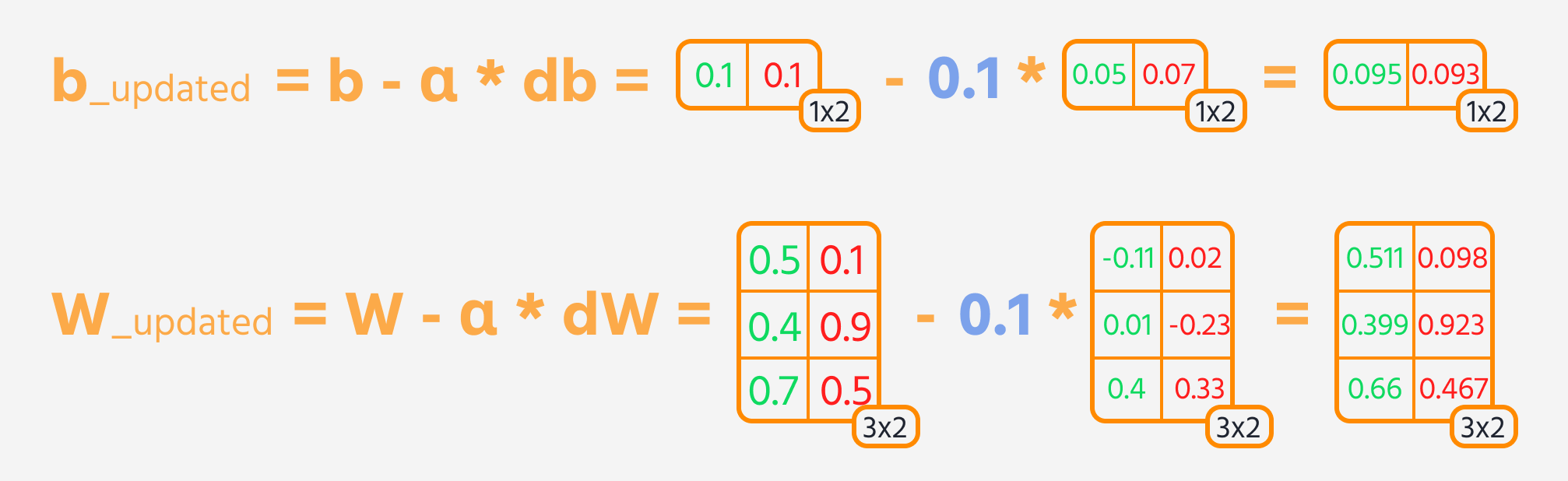
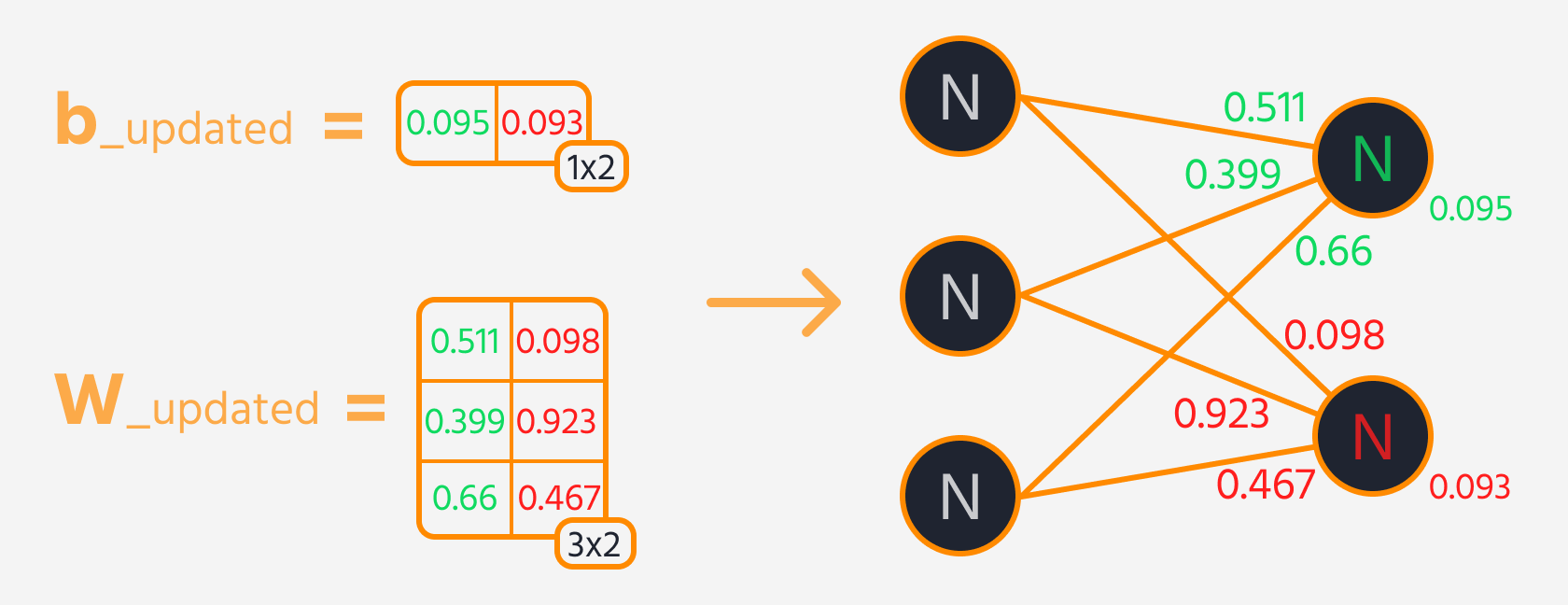
Trainingslus
Om het neuraal netwerk effectief te trainen, worden de trainingsstappen meerdere keren herhaald terwijl de prestaties van het model worden bijgehouden. Idealiter zou de verlieswaarde over de epochs moeten afnemen.
Bedankt voor je feedback!
single
Implementatie van Neurale Netwerken
Veeg om het menu te tonen
Overzicht van een Basis Neuraal Netwerk
Je hebt nu een punt bereikt waarop je beschikt over de essentiële kennis van TensorFlow om zelf neurale netwerken te maken. Hoewel de meeste neurale netwerken in de praktijk complex zijn en doorgaans worden gebouwd met hoog-niveau bibliotheken zoals Keras, zullen we een basisnetwerk opzetten met fundamentele TensorFlow-tools. Deze aanpak biedt praktische ervaring met laag-niveau tensor-manipulatie en helpt ons de onderliggende processen te begrijpen.
In eerdere cursussen zoals Introductie tot Neurale Netwerken herinner je je misschien nog hoeveel tijd en moeite het kostte om zelfs een eenvoudig neuraal netwerk te bouwen, waarbij elke neuron afzonderlijk werd behandeld.
TensorFlow vereenvoudigt dit proces aanzienlijk. Door gebruik te maken van tensors kun je complexe berekeningen inkapselen, waardoor de noodzaak voor ingewikkelde code afneemt. Onze belangrijkste taak is het opzetten van een sequentiële pijplijn van tensorbewerkingen.
Hier volgt een korte opfrissing van de stappen om een trainingsproces voor een neuraal netwerk te starten:
Gegevensvoorbereiding en modelcreatie
De beginfase van het trainen van een neuraal netwerk omvat het voorbereiden van de gegevens, waaronder zowel de inputs als outputs waarvan het netwerk zal leren. Daarnaast worden de hyperparameters van het model vastgesteld - dit zijn de parameters die gedurende het hele trainingsproces constant blijven. De gewichten worden geïnitialiseerd, meestal getrokken uit een normale verdeling, en de biases, die vaak op nul worden gezet.
Voorwaartse propagatie
Bij voorwaartse propagatie volgt elke laag van het netwerk doorgaans deze stappen:
- Vermenigvuldig de input van de laag met de gewichten.
- Tel een bias op bij het resultaat.
- Pas een activatiefunctie toe op deze som.
Vervolgens kan de verliesfunctie worden berekend.
Achterwaartse propagatie
De volgende stap is achterwaartse propagatie, waarbij de gewichten en biases worden aangepast op basis van hun invloed op de verliesfunctie. Deze invloed wordt weergegeven door de gradiënt, die automatisch wordt berekend door TensorFlow's Gradient Tape. De gewichten en biases worden bijgewerkt door de gradiënt, geschaald met het leerpercentage, af te trekken.
Trainingslus
Om het neuraal netwerk effectief te trainen, worden de trainingsstappen meerdere keren herhaald terwijl de prestaties van het model worden bijgehouden. Idealiter zou de verlieswaarde over de epochs moeten afnemen.
Veeg om te beginnen met coderen
Maak een neuraal netwerk dat is ontworpen om de uitkomsten van de XOR-bewerking te voorspellen. Het netwerk moet bestaan uit 2 inputneuronen, een verborgen laag met 2 neuronen en 1 outputneuron.
- Begin met het instellen van de initiële gewichten en biases. De gewichten moeten worden geïnitialiseerd met behulp van een normale verdeling en alle biases moeten worden geïnitialiseerd op nul. Gebruik de hyperparameters
input_size,hidden_sizeenoutput_sizeom de juiste vormen voor deze tensors te definiëren. - Gebruik een function decorator om de functie
train_step()om te zetten in een TensorFlow graph. - Voer voorwaartse propagatie uit door zowel de verborgen als de outputlaag van het netwerk. Gebruik de sigmoid activatiefunctie.
- Bepaal de gradiënten om te begrijpen hoe elk gewicht en elke bias de loss beïnvloedt. Zorg ervoor dat de gradiënten in de juiste volgorde worden berekend, overeenkomstig de namen van de outputvariabelen.
- Pas de gewichten en biases aan op basis van hun respectievelijke gradiënten. Neem de
learning_ratemee in dit aanpassingsproces om de grootte van elke update te bepalen.
Oplossing
Gegevensvoorbereiding
X_data: dit zijn de invoergegevens voor de XOR-functie. Het is een NumPy-array van vorm (4, 2), die de vier mogelijke combinaties van de XOR-invoer (0,0), (0,1), (1,0) en (1,1) weergeeft;Y_data: dit is de doeluitvoer voor elke invoercombinatie inX_data. Het is ook een NumPy-array, maar van vorm (4, 1), die de XOR-uitvoer voor elk invoerpaar weergeeft.
Netwerkparameters
input_size: de grootte van de invoerlaag, ingesteld op 2, overeenkomend met de twee invoerknooppunten (voor de twee ingangen van de XOR-functie);hidden_size: de grootte van de verborgen laag, ook ingesteld op 2. Deze keuze is enigszins willekeurig, maar is voldoende om de XOR-functie te leren;output_size: de grootte van de uitvoerlaag, ingesteld op 1, overeenkomend met het enkele uitvoerknooppunt (het resultaat van de XOR-bewerking);learning_rate: dit is het leerpercentage voor het optimalisatie-algoritme, dat bepaalt hoeveel de gewichten worden aangepast tijdens het trainen.
Gewichten en Biases
W1enb1: de gewichten (W1) en biases (b1) voor de verbindingen van de invoerlaag naar de verborgen laag.W1is een TensorFlow-variabele die is geïnitialiseerd met willekeurige waarden en heeft een vorm van(input_size, hidden_size), d.w.z.(2, 2).b1is een TensorFlow-variabele die is geïnitialiseerd met nullen en heeft een vorm van(hidden_size), d.w.z.(2);W2enb2: de gewichten (W2) en biases (b2) voor de verbindingen van de verborgen laag naar de uitvoerlaag.W2is geïnitialiseerd met willekeurige waarden en heeft een vorm van(hidden_size, output_size), d.w.z.(2, 1).b2is geïnitialiseerd met nullen en heeft een vorm van(output_size), d.w.z.(1).
Trainingsfunctie
train_step(): dit is de kerntrainingsfunctie. Deze gebruikttf.GradientTape()voor automatische differentiatie. In de forward pass worden de activaties van de verborgen laag (a1) en de uitvoervoorspellingen (Y_pred) berekend. Het verlies wordt berekend als de Mean Squared Error tussenY_predenY. De functie berekent vervolgens de gradiënten en werkt de gewichten en biases bij;tf.sigmoid(): een sigmoid activatiefunctie wordt gebruikt, die de invoer transformeert naar een waarde tussen0en1. Dit wordt gebruikt voor zowel de verborgen laag als de uitvoerlaag.
Trainingslus
- Het netwerk wordt getraind voor
2500epochs. In elke epoch wordt de functietrain_step()aangeroepen en worden de gewichten bijgewerkt. De verlieswaarde wordt elke500epochs afgedrukt om de voortgang van de training te monitoren.
Conclusie
Omdat de XOR-functie een relatief eenvoudige taak is, zijn geavanceerde technieken zoals hyperparameterafstemming, het splitsen van datasets of het bouwen van complexe datapijplijnen op dit moment niet nodig. Deze oefening is slechts een stap richting het bouwen van meer geavanceerde neurale netwerken voor toepassingen in de praktijk.
Het beheersen van deze basisprincipes is essentieel voordat je doorgaat naar geavanceerde technieken voor het bouwen van neurale netwerken in de komende cursussen, waarin we de Keras-bibliotheek zullen gebruiken en methoden zullen verkennen om de modelkwaliteit te verbeteren met de uitgebreide mogelijkheden van TensorFlow.
Bedankt voor je feedback!
single
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
