Overzicht van Beeldgeneratie
Veeg om het menu te tonen
Door AI gegenereerde afbeeldingen veranderen de manier waarop mensen kunst, design en digitale content creëren. Met behulp van kunstmatige intelligentie kunnen computers nu realistische afbeeldingen maken, creatief werk verbeteren en zelfs bedrijven ondersteunen. In dit hoofdstuk verkennen we hoe AI afbeeldingen maakt, verschillende typen beeldgeneratiemodellen en hoe deze in de praktijk worden toegepast.
Hoe AI Afbeeldingen Maakt
AI-beeldgeneratie werkt door te leren van een enorme verzameling afbeeldingen. De AI bestudeert patronen in de afbeeldingen en creëert vervolgens nieuwe die hierop lijken. Deze technologie is de afgelopen jaren sterk verbeterd, waardoor afbeeldingen realistischer en creatiever zijn geworden. Het wordt nu gebruikt in videogames, films, reclame en zelfs mode.
Vroege Methoden: PixelRNN en PixelCNN
Voordat de huidige geavanceerde AI-modellen bestonden, ontwikkelden onderzoekers vroege methoden voor beeldgeneratie zoals PixelRNN en PixelCNN. Deze modellen maakten afbeeldingen door één pixel tegelijk te voorspellen.
- PixelRNN: gebruikt een systeem genaamd een recurrent neural network (RNN) om pixelkleuren één voor één te voorspellen. Hoewel het goed werkte, was het erg traag;
- PixelCNN: verbeterde PixelRNN door gebruik te maken van een ander type netwerk, genaamd convolutionele lagen, waardoor het maken van afbeeldingen sneller ging.
Hoewel deze modellen een goed begin waren, waren ze niet in staat om afbeeldingen van hoge kwaliteit te maken. Dit leidde tot de ontwikkeling van betere technieken.
Autoregressieve modellen
Autoregressieve modellen creëren ook afbeeldingen één pixel tegelijk, waarbij eerdere pixels worden gebruikt om te voorspellen wat er daarna komt. Deze modellen waren nuttig maar traag, waardoor ze na verloop van tijd minder populair werden. Ze hebben echter wel bijgedragen aan de ontwikkeling van nieuwere, snellere modellen.
Hoe AI tekst begrijpt voor beeldcreatie
Sommige AI-modellen kunnen geschreven woorden omzetten in afbeeldingen. Deze modellen gebruiken Large Language Models (LLMs) om beschrijvingen te begrijpen en bijpassende beelden te genereren. Bijvoorbeeld, als je "een kat die op het strand zit bij zonsondergang" typt, zal de AI een afbeelding maken op basis van die beschrijving.
AI-modellen zoals OpenAI's DALL-E en Google's Imagen gebruiken geavanceerd taalbegrip om de overeenkomst tussen tekstbeschrijvingen en de gegenereerde afbeeldingen te verbeteren. Dit is mogelijk dankzij Natural Language Processing (NLP), waarmee AI woorden omzet in getallen die het beeldvormingsproces sturen.
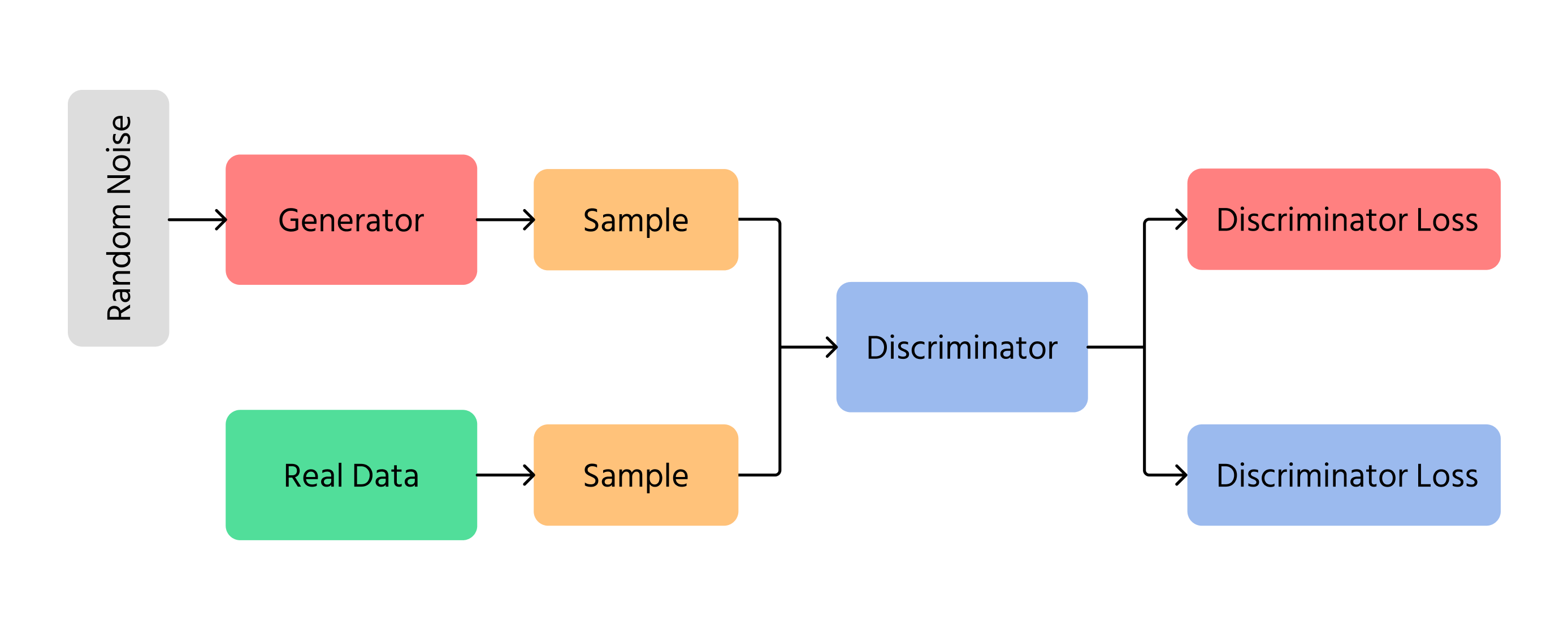
Generative Adversarial Networks (GANs)
Een van de belangrijkste doorbraken in AI-beeldgeneratie was Generative Adversarial Networks (GANs). GANs werken met twee verschillende neurale netwerken:
- Generator: maakt nieuwe afbeeldingen vanaf nul;
- Discriminator: controleert of de afbeeldingen echt of nep zijn.
De generator probeert afbeeldingen zo realistisch te maken dat de discriminator niet kan zien dat ze nep zijn. Na verloop van tijd worden de afbeeldingen beter en lijken ze meer op echte foto's. GANs worden gebruikt in deepfake-technologie, het maken van kunstwerken en het verbeteren van beeldkwaliteit.
Variational Autoencoders (VAEs)
VAEs vormen een alternatieve methode waarmee AI afbeeldingen kan genereren. In plaats van competitie zoals bij GANs, coderen en decoderen VAEs afbeeldingen met behulp van waarschijnlijkheid. Ze werken door de onderliggende patronen in een afbeelding te leren en deze vervolgens te reconstrueren met kleine variaties. Het probabilistische element in VAEs zorgt ervoor dat elke gegenereerde afbeelding iets anders is, wat variatie en creativiteit toevoegt.
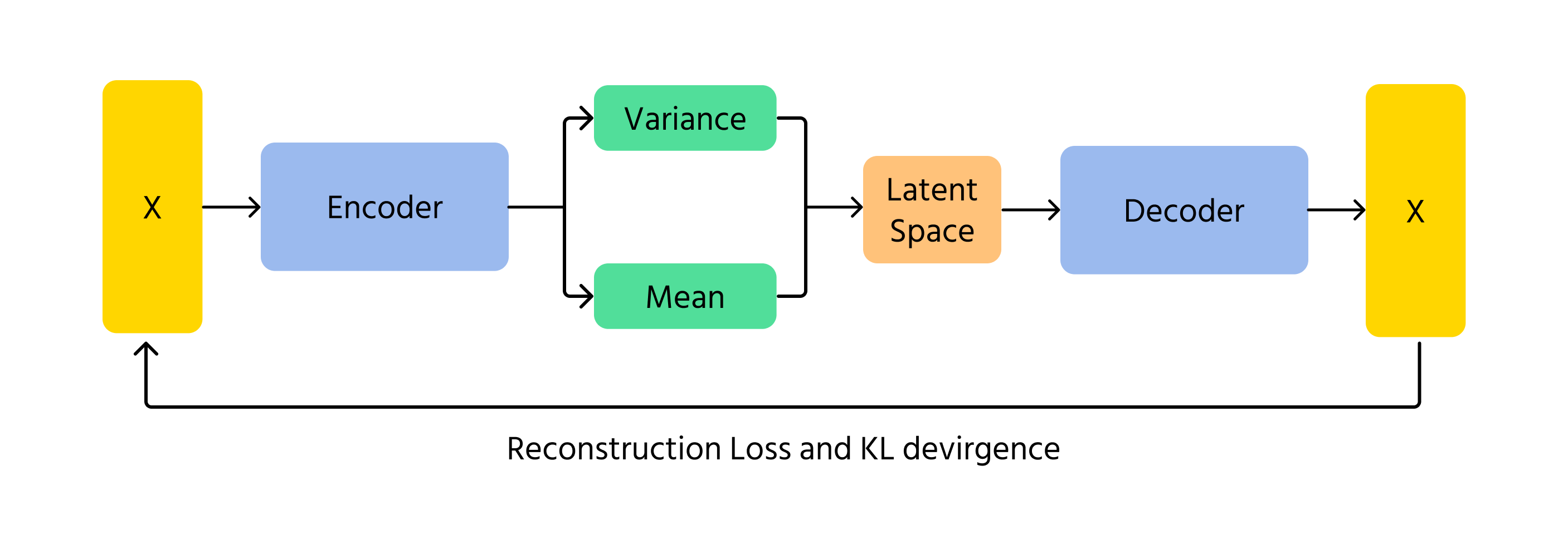
Een belangrijk concept in VAEs is de Kullback-Leibler (KL) divergentie, die het verschil meet tussen de geleerde distributie en een standaard normale distributie. Door de KL divergentie te minimaliseren, zorgen VAEs ervoor dat gegenereerde afbeeldingen realistisch blijven, terwijl creatieve variaties mogelijk blijven.
Werking van VAEs
- Encodering: de invoergegevens x worden aan de encoder aangeboden, die de parameters van de latente ruimtedistributie q(z∣x) (gemiddelde μ en variantie σ²) oplevert;
- Latente ruimte sampling: latente variabelen z worden gesampled uit de distributie q(z∣x) met technieken zoals de reparameterisatietrick;
- Decodering & reconstructie: de gesamplede z wordt door de decoder gehaald om de gereconstrueerde data x̂ te produceren, die vergelijkbaar moet zijn met de oorspronkelijke invoer x.
VAEs zijn nuttig voor taken zoals het reconstrueren van gezichten, het genereren van nieuwe versies van bestaande afbeeldingen en het maken van vloeiende overgangen tussen verschillende afbeeldingen.
Diffusiemodellen
Diffusiemodellen zijn de nieuwste doorbraak in AI-gegenereerde afbeeldingen. Deze modellen beginnen met willekeurige ruis en verbeteren het beeld stap voor stap, vergelijkbaar met het wissen van statische ruis van een wazige foto. In tegenstelling tot GANs, die soms beperkte variaties creëren, kunnen diffusiemodellen een breder scala aan hoogwaardige afbeeldingen produceren.
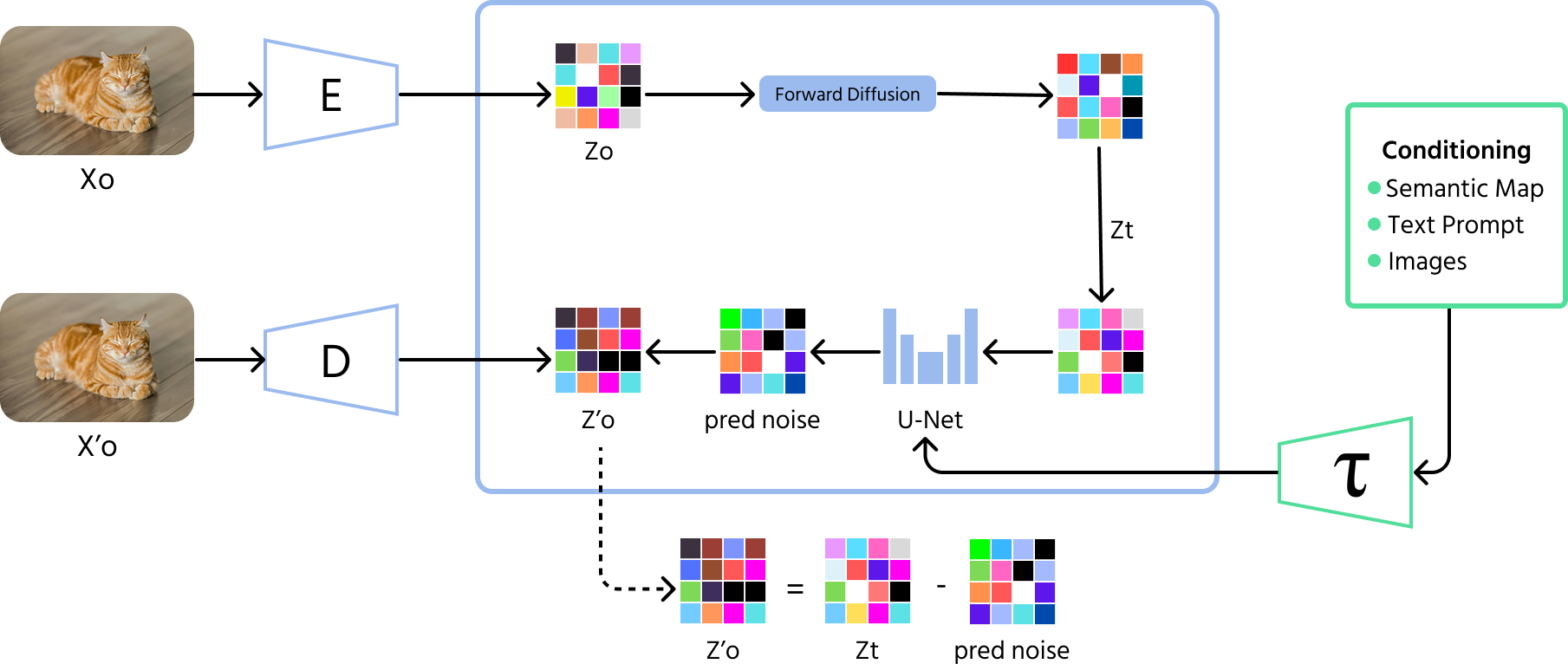
Hoe diffusie modellen werken
- Voorwaarts proces (ruis toevoegen): het model begint met het toevoegen van willekeurige ruis aan een afbeelding gedurende vele stappen totdat deze volledig onherkenbaar wordt;
- Omgekeerd proces (ruis verwijderen): het model leert vervolgens hoe dit proces om te keren, waarbij de ruis stap voor stap geleidelijk wordt verwijderd om een betekenisvolle afbeelding terug te krijgen;
- Training: diffusie modellen worden getraind om bij elke stap ruis te voorspellen en te verwijderen, waardoor ze heldere en hoogwaardige afbeeldingen uit willekeurige ruis kunnen genereren.
Een bekend voorbeeld is MidJourney, DALL-E en Stable Diffusion, dat bekend staat om het maken van realistische en artistieke afbeeldingen. Diffusie modellen worden veel gebruikt voor AI-gegenereerde kunst, hoge-resolutie beeldsynthese en creatieve ontwerp toepassingen.
Voorbeelden van afbeeldingen gegenereerd door diffusie modellen

Realistisch beeld van een basketballer met een baard in een geel-violet uniform die een dunk maakt en demonen verslaat in een basketbalwedstrijd, alle actie vindt plaats in de hel.

Een surrealistische, prachtige artistieke foto van een witte 1990 Volkswagen Golf GTI in een eindeloos veld van witte bloemen in harmonie met de natuur, midden in eindeloze heuvels vol bloemen, botanisch, natuurlijk licht, artistiek, mistig, fotorealistisch, surrealistisch, ultradetail, kodakfilm, natuurlijk licht, groothoeklens, f 1.20

Schilderij van een beige Poedel die op een groene bank ligt met een groen-wit gestreept kussen in de stijl van Fairfield Porter, abstract expressionisme, met gedurfde penseelstreken op een beige achtergrond

Extreme close-up van de huid van een mediterrane of Latijns-Amerikaanse vrouw, met nadruk op een gecombineerde huidtype met zichtbare vettigheid op het voorhoofd en de neus, terwijl de wangen droger en licht schilferig lijken. De poriën zijn duidelijker zichtbaar in de T-zone en er is een natuurlijke glans door de olieproductie. De huid heeft een mix van warme en gouden ondertonen, met een ongelijke textuur door verschillende hydratatieniveaus. Zacht, natuurlijk licht benadrukt het realistische contrast tussen de droge en vette zones. De achtergrond is vervaagd, waardoor de aandacht op haar teint blijft.
Uitdagingen en ethische kwesties
Hoewel AI-gegenereerde afbeeldingen indrukwekkend zijn, brengen ze uitdagingen met zich mee:
- Gebrek aan controle: AI genereert niet altijd precies wat de gebruiker wil;
- Rekenkracht: het maken van hoogwaardige AI-afbeeldingen vereist dure en krachtige computers;
- Vertekening in AI-modellen: omdat AI leert van bestaande afbeeldingen, kan het soms vooroordelen uit de data herhalen.
Er zijn ook ethische kwesties:
- Wie is eigenaar van AI-kunst?: als een AI een kunstwerk maakt, is de gebruiker dan eigenaar of behoort het toe aan het AI-bedrijf?
- Valse beelden en deepfakes: GAN's kunnen worden gebruikt om valse beelden te maken die echt lijken, wat kan leiden tot desinformatie en privacyproblemen.
Huidig gebruik van AI-beeldgeneratie
AI-gegenereerde afbeeldingen hebben nu al een grote impact in verschillende sectoren:
- Entertainment: videogames, films en animatie gebruiken AI om achtergronden, personages en effecten te creëren;
- Mode: ontwerpers gebruiken AI om nieuwe kledingstijlen te ontwikkelen en webwinkels bieden virtuele paskamers aan klanten;
- Grafisch ontwerp: AI helpt kunstenaars en ontwerpers snel logo's, posters en marketingmateriaal te maken.
De toekomst van AI-beeldgeneratie
Naarmate AI-beeldgeneratie zich verder ontwikkelt, zal het blijven veranderen hoe mensen beelden creëren en gebruiken. Of het nu in kunst, bedrijfsleven of entertainment is, AI opent nieuwe mogelijkheden en maakt creatief werk eenvoudiger en spannender.
1. Wat is het belangrijkste doel van AI-beeldgeneratie?
2. Hoe werken Generative Adversarial Networks (GANs)?
3. Welk AI-model begint met willekeurige ruis en verbetert de afbeelding stap voor stap?
Bedankt voor je feedback!
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
Overzicht van Beeldgeneratie
Door AI gegenereerde afbeeldingen veranderen de manier waarop mensen kunst, design en digitale content creëren. Met behulp van kunstmatige intelligentie kunnen computers nu realistische afbeeldingen maken, creatief werk verbeteren en zelfs bedrijven ondersteunen. In dit hoofdstuk verkennen we hoe AI afbeeldingen maakt, verschillende typen beeldgeneratiemodellen en hoe deze in de praktijk worden toegepast.
Hoe AI Afbeeldingen Maakt
AI-beeldgeneratie werkt door te leren van een enorme verzameling afbeeldingen. De AI bestudeert patronen in de afbeeldingen en creëert vervolgens nieuwe die hierop lijken. Deze technologie is de afgelopen jaren sterk verbeterd, waardoor afbeeldingen realistischer en creatiever zijn geworden. Het wordt nu gebruikt in videogames, films, reclame en zelfs mode.
Vroege Methoden: PixelRNN en PixelCNN
Voordat de huidige geavanceerde AI-modellen bestonden, ontwikkelden onderzoekers vroege methoden voor beeldgeneratie zoals PixelRNN en PixelCNN. Deze modellen maakten afbeeldingen door één pixel tegelijk te voorspellen.
- PixelRNN: gebruikt een systeem genaamd een recurrent neural network (RNN) om pixelkleuren één voor één te voorspellen. Hoewel het goed werkte, was het erg traag;
- PixelCNN: verbeterde PixelRNN door gebruik te maken van een ander type netwerk, genaamd convolutionele lagen, waardoor het maken van afbeeldingen sneller ging.
Hoewel deze modellen een goed begin waren, waren ze niet in staat om afbeeldingen van hoge kwaliteit te maken. Dit leidde tot de ontwikkeling van betere technieken.
Autoregressieve modellen
Autoregressieve modellen creëren ook afbeeldingen één pixel tegelijk, waarbij eerdere pixels worden gebruikt om te voorspellen wat er daarna komt. Deze modellen waren nuttig maar traag, waardoor ze na verloop van tijd minder populair werden. Ze hebben echter wel bijgedragen aan de ontwikkeling van nieuwere, snellere modellen.
Hoe AI tekst begrijpt voor beeldcreatie
Sommige AI-modellen kunnen geschreven woorden omzetten in afbeeldingen. Deze modellen gebruiken Large Language Models (LLMs) om beschrijvingen te begrijpen en bijpassende beelden te genereren. Bijvoorbeeld, als je "een kat die op het strand zit bij zonsondergang" typt, zal de AI een afbeelding maken op basis van die beschrijving.
AI-modellen zoals OpenAI's DALL-E en Google's Imagen gebruiken geavanceerd taalbegrip om de overeenkomst tussen tekstbeschrijvingen en de gegenereerde afbeeldingen te verbeteren. Dit is mogelijk dankzij Natural Language Processing (NLP), waarmee AI woorden omzet in getallen die het beeldvormingsproces sturen.
Generative Adversarial Networks (GANs)
Een van de belangrijkste doorbraken in AI-beeldgeneratie was Generative Adversarial Networks (GANs). GANs werken met twee verschillende neurale netwerken:
- Generator: maakt nieuwe afbeeldingen vanaf nul;
- Discriminator: controleert of de afbeeldingen echt of nep zijn.
De generator probeert afbeeldingen zo realistisch te maken dat de discriminator niet kan zien dat ze nep zijn. Na verloop van tijd worden de afbeeldingen beter en lijken ze meer op echte foto's. GANs worden gebruikt in deepfake-technologie, het maken van kunstwerken en het verbeteren van beeldkwaliteit.
Variational Autoencoders (VAEs)
VAEs vormen een alternatieve methode waarmee AI afbeeldingen kan genereren. In plaats van competitie zoals bij GANs, coderen en decoderen VAEs afbeeldingen met behulp van waarschijnlijkheid. Ze werken door de onderliggende patronen in een afbeelding te leren en deze vervolgens te reconstrueren met kleine variaties. Het probabilistische element in VAEs zorgt ervoor dat elke gegenereerde afbeelding iets anders is, wat variatie en creativiteit toevoegt.
Een belangrijk concept in VAEs is de Kullback-Leibler (KL) divergentie, die het verschil meet tussen de geleerde distributie en een standaard normale distributie. Door de KL divergentie te minimaliseren, zorgen VAEs ervoor dat gegenereerde afbeeldingen realistisch blijven, terwijl creatieve variaties mogelijk blijven.
Werking van VAEs
- Encodering: de invoergegevens x worden aan de encoder aangeboden, die de parameters van de latente ruimtedistributie q(z∣x) (gemiddelde μ en variantie σ²) oplevert;
- Latente ruimte sampling: latente variabelen z worden gesampled uit de distributie q(z∣x) met technieken zoals de reparameterisatietrick;
- Decodering & reconstructie: de gesamplede z wordt door de decoder gehaald om de gereconstrueerde data x̂ te produceren, die vergelijkbaar moet zijn met de oorspronkelijke invoer x.
VAEs zijn nuttig voor taken zoals het reconstrueren van gezichten, het genereren van nieuwe versies van bestaande afbeeldingen en het maken van vloeiende overgangen tussen verschillende afbeeldingen.
Diffusiemodellen
Diffusiemodellen zijn de nieuwste doorbraak in AI-gegenereerde afbeeldingen. Deze modellen beginnen met willekeurige ruis en verbeteren het beeld stap voor stap, vergelijkbaar met het wissen van statische ruis van een wazige foto. In tegenstelling tot GANs, die soms beperkte variaties creëren, kunnen diffusiemodellen een breder scala aan hoogwaardige afbeeldingen produceren.
Hoe diffusie modellen werken
- Voorwaarts proces (ruis toevoegen): het model begint met het toevoegen van willekeurige ruis aan een afbeelding gedurende vele stappen totdat deze volledig onherkenbaar wordt;
- Omgekeerd proces (ruis verwijderen): het model leert vervolgens hoe dit proces om te keren, waarbij de ruis stap voor stap geleidelijk wordt verwijderd om een betekenisvolle afbeelding terug te krijgen;
- Training: diffusie modellen worden getraind om bij elke stap ruis te voorspellen en te verwijderen, waardoor ze heldere en hoogwaardige afbeeldingen uit willekeurige ruis kunnen genereren.
Een bekend voorbeeld is MidJourney, DALL-E en Stable Diffusion, dat bekend staat om het maken van realistische en artistieke afbeeldingen. Diffusie modellen worden veel gebruikt voor AI-gegenereerde kunst, hoge-resolutie beeldsynthese en creatieve ontwerp toepassingen.
Voorbeelden van afbeeldingen gegenereerd door diffusie modellen
Realistisch beeld van een basketballer met een baard in een geel-violet uniform die een dunk maakt en demonen verslaat in een basketbalwedstrijd, alle actie vindt plaats in de hel.
Een surrealistische, prachtige artistieke foto van een witte 1990 Volkswagen Golf GTI in een eindeloos veld van witte bloemen in harmonie met de natuur, midden in eindeloze heuvels vol bloemen, botanisch, natuurlijk licht, artistiek, mistig, fotorealistisch, surrealistisch, ultradetail, kodakfilm, natuurlijk licht, groothoeklens, f 1.20
Schilderij van een beige Poedel die op een groene bank ligt met een groen-wit gestreept kussen in de stijl van Fairfield Porter, abstract expressionisme, met gedurfde penseelstreken op een beige achtergrond
Extreme close-up van de huid van een mediterrane of Latijns-Amerikaanse vrouw, met nadruk op een gecombineerde huidtype met zichtbare vettigheid op het voorhoofd en de neus, terwijl de wangen droger en licht schilferig lijken. De poriën zijn duidelijker zichtbaar in de T-zone en er is een natuurlijke glans door de olieproductie. De huid heeft een mix van warme en gouden ondertonen, met een ongelijke textuur door verschillende hydratatieniveaus. Zacht, natuurlijk licht benadrukt het realistische contrast tussen de droge en vette zones. De achtergrond is vervaagd, waardoor de aandacht op haar teint blijft.
Uitdagingen en ethische kwesties
Hoewel AI-gegenereerde afbeeldingen indrukwekkend zijn, brengen ze uitdagingen met zich mee:
- Gebrek aan controle: AI genereert niet altijd precies wat de gebruiker wil;
- Rekenkracht: het maken van hoogwaardige AI-afbeeldingen vereist dure en krachtige computers;
- Vertekening in AI-modellen: omdat AI leert van bestaande afbeeldingen, kan het soms vooroordelen uit de data herhalen.
Er zijn ook ethische kwesties:
- Wie is eigenaar van AI-kunst?: als een AI een kunstwerk maakt, is de gebruiker dan eigenaar of behoort het toe aan het AI-bedrijf?
- Valse beelden en deepfakes: GAN's kunnen worden gebruikt om valse beelden te maken die echt lijken, wat kan leiden tot desinformatie en privacyproblemen.
Huidig gebruik van AI-beeldgeneratie
AI-gegenereerde afbeeldingen hebben nu al een grote impact in verschillende sectoren:
- Entertainment: videogames, films en animatie gebruiken AI om achtergronden, personages en effecten te creëren;
- Mode: ontwerpers gebruiken AI om nieuwe kledingstijlen te ontwikkelen en webwinkels bieden virtuele paskamers aan klanten;
- Grafisch ontwerp: AI helpt kunstenaars en ontwerpers snel logo's, posters en marketingmateriaal te maken.
De toekomst van AI-beeldgeneratie
Naarmate AI-beeldgeneratie zich verder ontwikkelt, zal het blijven veranderen hoe mensen beelden creëren en gebruiken. Of het nu in kunst, bedrijfsleven of entertainment is, AI opent nieuwe mogelijkheden en maakt creatief werk eenvoudiger en spannender.
Bedankt voor je feedback!
