Voorspellingen van Begrenzingsvakken
Veeg om het menu te tonen
Begrenzingsvakken zijn essentieel voor objectdetectie en bieden een manier om objectlocaties aan te geven. Objectdetectiemodellen gebruiken deze vakken om de positie en afmetingen van gedetecteerde objecten binnen een afbeelding te definiëren. Het nauwkeurig voorspellen van begrenzingsvakken is fundamenteel voor betrouwbare objectdetectie.
Hoe CNN's coördinaten van begrenzingsvakken voorspellen
Convolutionele Neurale Netwerken (CNN's) verwerken afbeeldingen via lagen van convoluties en pooling om kenmerken te extraheren. Voor objectdetectie genereren CNN's feature maps die verschillende delen van een afbeelding weergeven. Voorspellingen van begrenzingsvakken worden doorgaans bereikt door:
- Kenmerkrepresentaties extraheren uit de afbeelding;
- Een regressiefunctie toepassen om coördinaten van begrenzingsvakken te voorspellen;
- De gedetecteerde objecten classificeren binnen elk vak.
Voorspellingen van begrenzingsvakken worden weergegeven als numerieke waarden die overeenkomen met:
- (x, y): de coördinaten van het midden van het vak;
- (w, h): de breedte en hoogte van het vak.
Voorbeeld: Begrenzingsvakken voorspellen met een voorgetraind model
In plaats van een CNN vanaf nul te trainen, kan een voorgetraind model zoals Faster R-CNN uit TensorFlow's model zoo worden gebruikt om begrenzingsvakken op een afbeelding te voorspellen. Hieronder volgt een voorbeeld van het laden van een voorgetraind model, het laden van een afbeelding, het maken van voorspellingen en het visualiseren van de begrenzingsvakken met klassenlabels.
Importeer bibliotheken
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Model en afbeelding laden
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Afbeelding preprocessen
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Voorspelling maken en kenmerken van begrenzingsvakken extraheren
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Begrenzingsvakken tekenen
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualiseren
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultaat:

Regressiegebaseerde Voorspellingen van Omhullende Vakken
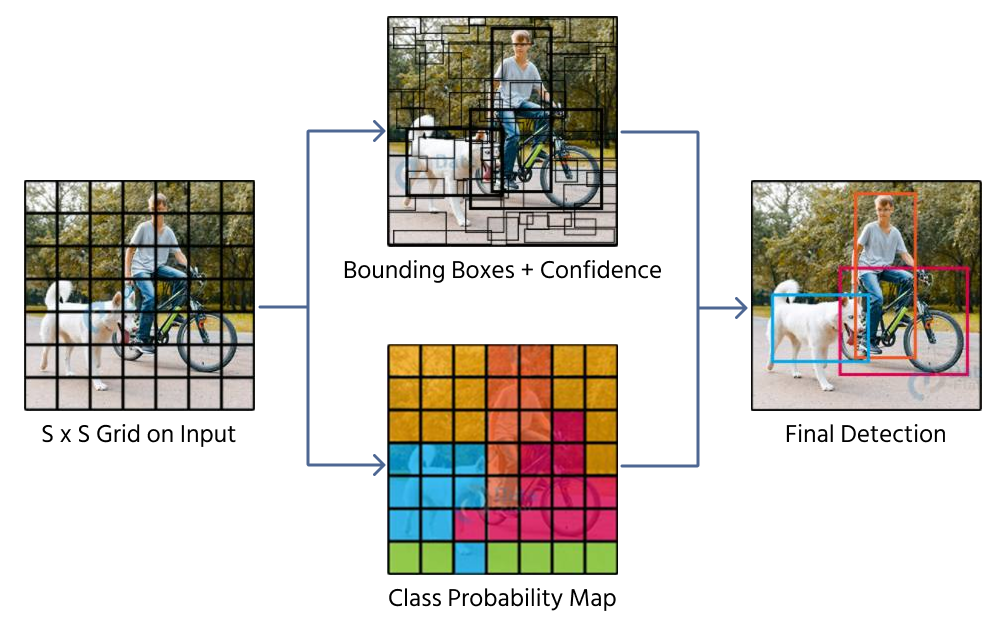
Een benadering voor het voorspellen van omhullende vakken is directe regressie, waarbij een CNN vier numerieke waarden oplevert die de positie en grootte van het vak aangeven. Modellen zoals YOLO (You Only Look Once) passen deze techniek toe door een afbeelding op te delen in een raster en omhullende vakvoorspellingen toe te wijzen aan rastercellen.
Directe regressie kent echter beperkingen:
- Moeilijkheden met objecten van verschillende groottes en beeldverhoudingen;
- Onvoldoende verwerking van overlappende objecten;
- Omhullende vakken kunnen onvoorspelbaar verschuiven, wat leidt tot inconsistenties.
Anchor-gebaseerde versus Anchor-vrije benaderingen
Anchor-gebaseerde methoden
Anchor boxes zijn vooraf gedefinieerde begrenzingskaders met vaste groottes en beeldverhoudingen. Modellen zoals Faster R-CNN en SSD (Single Shot MultiBox Detector) gebruiken anchor boxes om de nauwkeurigheid van voorspellingen te verbeteren. Het model voorspelt aanpassingen aan anchor boxes in plaats van begrenzingskaders volledig vanaf nul te voorspellen. Deze methode werkt goed voor het detecteren van objecten op verschillende schalen, maar verhoogt de computationele complexiteit.
Anchor-vrije methoden
Anchor-vrije methoden, zoals CenterNet en FCOS (Fully Convolutional One-Stage Object Detection), elimineren vooraf gedefinieerde anchor boxes en voorspellen in plaats daarvan direct de objectcentra. Deze methoden bieden:
- Eenvoudigere modelarchitecturen;
- Snellere inferentiesnelheden;
- Verbeterde generalisatie naar onbekende objectgroottes.

A (Anchor-gebaseerd): voorspelt afwijkingen (groene lijnen) vanaf vooraf gedefinieerde ankers (blauw) om overeen te komen met de grondwaarheid (rood). B (Anchor-vrij): schat direct afwijkingen van een punt naar zijn grenzen.
Voorspelling van begrenzingsvakken is een essentieel onderdeel van objectdetectie, waarbij verschillende benaderingen een balans zoeken tussen nauwkeurigheid en efficiëntie. Terwijl anchor-gebaseerde methoden de precisie verhogen door gebruik te maken van vooraf gedefinieerde vormen, vereenvoudigen anchor-vrije methoden de detectie door direct objectlocaties te voorspellen. Inzicht in deze technieken helpt bij het ontwerpen van betere objectdetectiesystemen voor diverse toepassingen in de praktijk.
1. Welke informatie bevat een bounding box-voorspelling doorgaans?
2. Wat is het belangrijkste voordeel van anchor-gebaseerde methoden bij objectdetectie?
3. Met welke uitdaging wordt directe regressie geconfronteerd bij bounding box-voorspelling?
Bedankt voor je feedback!
Vraag AI
Vraag AI

Vraag wat u wilt of probeer een van de voorgestelde vragen om onze chat te starten.
