Modelos de Difusão e Abordagens Generativas Probabilísticas
Deslize para mostrar o menu
Compreendendo a Geração Baseada em Difusão
Modelos de difusão são um tipo poderoso de modelo de IA que geram dados – especialmente imagens – aprendendo a reverter um processo de adição de ruído aleatório. Imagine observar uma imagem limpa tornando-se gradualmente borrada, como estática em uma TV. Um modelo de difusão aprende a fazer o oposto: ele recebe imagens ruidosas e reconstrói a imagem original removendo o ruído passo a passo.
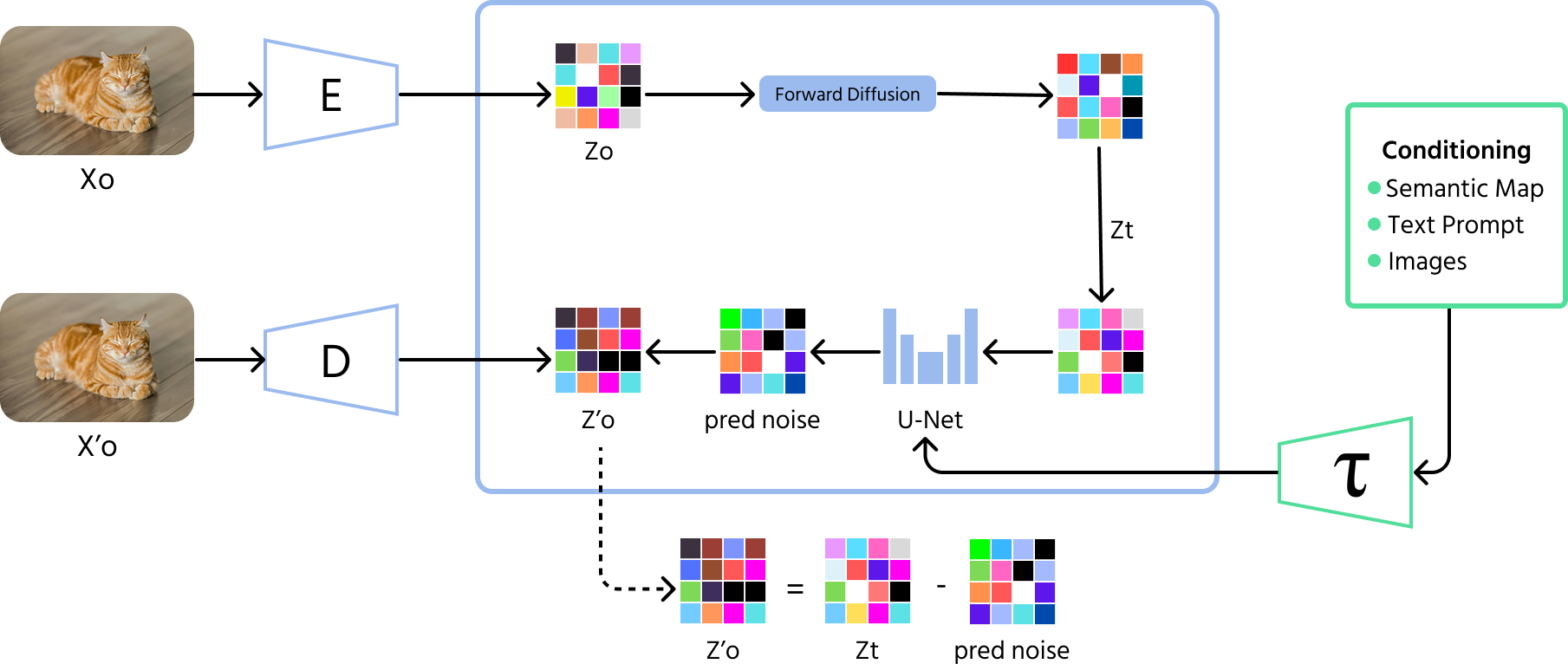
O processo envolve duas fases principais:
- Processo direto (difusão): adiciona gradualmente ruído aleatório a uma imagem ao longo de muitos passos, corrompendo-a até se tornar puro ruído;
- Processo reverso (remoção de ruído): uma rede neural aprende a remover o ruído passo a passo, reconstruindo a imagem original a partir da versão ruidosa.
Modelos de difusão são conhecidos por sua capacidade de produzir imagens realistas e de alta qualidade. Seu treinamento costuma ser mais estável em comparação com modelos como GANs, o que os torna muito atraentes na IA generativa moderna.
Modelos Probabilísticos de Difusão para Remoção de Ruído (DDPMs)
Modelos probabilísticos de difusão para remoção de ruído (DDPMs) são um tipo popular de modelo de difusão que aplicam princípios probabilísticos e aprendizado profundo para remover ruído de imagens de forma gradual, etapa por etapa.
Processo Direto
No processo direto, inicia-se com uma imagem real x0 e adiciona-se ruído Gaussiano gradualmente ao longo de T passos de tempo:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)Onde:
- xt: versão ruidosa da entrada no passo de tempo;
- βt: agendamento de variância pequena que controla quanto ruído é adicionado;
- N: distribuição Gaussiana.
Também é possível expressar o ruído total adicionado até o passo como:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)Onde:
- αˉt=∏s=1t(1−βs)
Processo Reverso
O objetivo do modelo é aprender o processo reverso. Uma rede neural parametrizada por θ prevê a média e a variância da distribuição sem ruído:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))onde:
- xt: imagem ruidosa no instante de tempo t;
- xt−1: imagem prevista com menos ruído no passo t−1;
- μθ: média prevista pela rede neural;
- Σθ: variância prevista pela rede neural.
Função de Perda
O treinamento envolve minimizar a diferença entre o ruído real e o ruído previsto pelo modelo utilizando o seguinte objetivo:
Lsimple=Ex0,ϵ,t[∣∣ϵ−ϵ0(αˉtx0+1−αˉtϵ,t)∣∣2]onde:
- xt: imagem de entrada original;
- ϵ: ruído gaussiano aleatório;
- t: passo de tempo durante a difusão;
- ϵθ: previsão do ruído pela rede neural;
- αˉt: Produto dos parâmetros do cronograma de ruído até o passo t.
Isso auxilia o modelo a melhorar a remoção de ruído, aprimorando sua capacidade de gerar dados realistas.
Modelagem Generativa Baseada em Score
Modelos baseados em score são outra classe de modelos de difusão. Em vez de aprender diretamente o processo reverso do ruído, eles aprendem a função score:
∇xlogp(x)onde:
- ∇xlogp(x): o gradiente da densidade de log-probabilidade em relação à entrada x. Isso aponta para a direção de aumento da probabilidade sob a distribuição dos dados;
- p(x): a distribuição de probabilidade dos dados.
Essa função indica ao modelo em qual direção a imagem deve ser ajustada para se tornar mais semelhante aos dados reais. Esses modelos utilizam então um método de amostragem como a dinâmica de Langevin para mover gradualmente dados ruidosos em direção a regiões de alta probabilidade dos dados.
Modelos baseados em score frequentemente operam em tempo contínuo usando equações diferenciais estocásticas (SDEs). Essa abordagem contínua oferece flexibilidade e pode produzir gerações de alta qualidade em diversos tipos de dados.
Aplicações em Geração de Imagens em Alta Resolução
Modelos de difusão revolucionaram tarefas generativas, especialmente na geração visual em alta resolução. Aplicações notáveis incluem:
- Stable Diffusion: um modelo de difusão latente que gera imagens a partir de prompts de texto. Combina um modelo de remoção de ruído baseado em U-Net com um autoencoder variacional (VAE) para operar no espaço latente;
- DALL·E 2: combina embeddings CLIP e decodificação baseada em difusão para gerar imagens altamente realistas e semânticas a partir de texto;
- MidJourney: uma plataforma de geração de imagens baseada em difusão conhecida por produzir visuais de alta qualidade e estilo artístico a partir de prompts abstratos ou criativos.
Esses modelos são utilizados em geração de arte, síntese fotorrealista, inpainting, super-resolução e mais.
Resumo
Modelos de difusão definem uma nova era de modelagem generativa ao tratar a geração de dados como um processo estocástico reverso no tempo. Por meio de DDPMs e modelos baseados em score, alcançam treinamento robusto, alta qualidade de amostras e resultados impressionantes em diversas modalidades. Seu embasamento em princípios probabilísticos e termodinâmicos os torna matematicamente elegantes e praticamente poderosos.
1. Qual é a ideia principal por trás dos modelos generativos baseados em difusão?
2. O que o processo direto do DDPM utiliza para adicionar ruído em cada etapa?
3. Qual das alternativas a seguir melhor descreve o papel da função score ∇xlogp(x) na modelagem generativa baseada em score?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
