Gráfico KDE
Um gráfico de Estimativa de Densidade de Kernel (KDE) é um tipo de gráfico que visualiza a função densidade de probabilidade estimada de uma variável contínua. Diferente de um histograma, que exibe dados usando barras discretas agrupadas em intervalos, um gráfico KDE representa a distribuição como uma curva suave e contínua baseada em todos os pontos de dados.
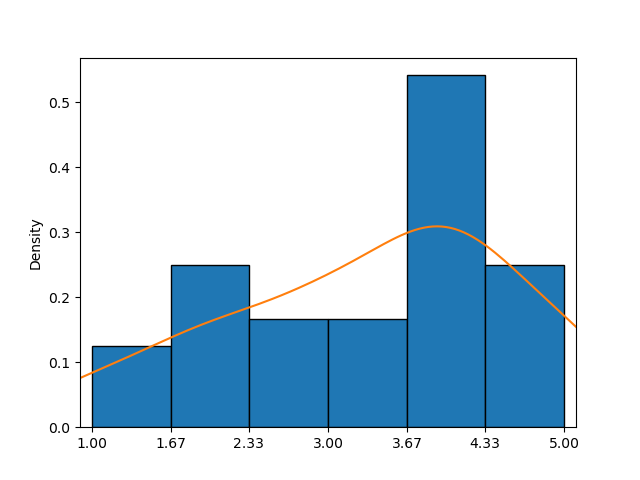
Este exemplo mostra um histograma combinado com um gráfico KDE (curva laranja), proporcionando uma aproximação mais clara da função densidade de probabilidade do que apenas o histograma.
No seaborn, a função kdeplot() facilita a criação de gráficos KDE. Seus principais parâmetros—data, x e y—funcionam da mesma forma que em countplot().
Primeira Opção
Apenas um dos parâmetros pode ser definido passando uma sequência de valores, permitindo personalização individual entre os elementos.
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting only the data parameter sns.kdeplot(data=weather_df['Seattle'], fill=True) plt.show()
O parâmetro data é definido passando um objeto Series, e o parâmetro fill é utilizado para preencher a área sob a curva, que por padrão não é preenchida.
Segunda Opção
Também é possível definir um objeto 2D como um DataFrame para o parâmetro data e um nome de coluna ou uma chave se o data for um dicionário para x (orientação vertical) ou y (orientação horizontal):
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting both the data and x parameters sns.kdeplot(data=weather_df, x='Seattle', fill=True) plt.show()
Os mesmos resultados foram obtidos ao passar todo o DataFrame como parâmetro data e especificar o nome da coluna para o parâmetro x.
O gráfico KDE criado exibe uma curva em formato de sino, característica que se assemelha a uma distribuição normal com média em torno de 52°F.
Caso deseje explorar mais sobre a função KDE plot, consulte a documentação do kdeplot().
Obrigado pelo seu feedback!
single
Gráfico KDE
Deslize para mostrar o menu
Um gráfico de Estimativa de Densidade de Kernel (KDE) é um tipo de gráfico que visualiza a função densidade de probabilidade estimada de uma variável contínua. Diferente de um histograma, que exibe dados usando barras discretas agrupadas em intervalos, um gráfico KDE representa a distribuição como uma curva suave e contínua baseada em todos os pontos de dados.
Este exemplo mostra um histograma combinado com um gráfico KDE (curva laranja), proporcionando uma aproximação mais clara da função densidade de probabilidade do que apenas o histograma.
No seaborn, a função kdeplot() facilita a criação de gráficos KDE. Seus principais parâmetros—data, x e y—funcionam da mesma forma que em countplot().
Primeira Opção
Apenas um dos parâmetros pode ser definido passando uma sequência de valores, permitindo personalização individual entre os elementos.
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting only the data parameter sns.kdeplot(data=weather_df['Seattle'], fill=True) plt.show()
O parâmetro data é definido passando um objeto Series, e o parâmetro fill é utilizado para preencher a área sob a curva, que por padrão não é preenchida.
Segunda Opção
Também é possível definir um objeto 2D como um DataFrame para o parâmetro data e um nome de coluna ou uma chave se o data for um dicionário para x (orientação vertical) ou y (orientação horizontal):
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting both the data and x parameters sns.kdeplot(data=weather_df, x='Seattle', fill=True) plt.show()
Os mesmos resultados foram obtidos ao passar todo o DataFrame como parâmetro data e especificar o nome da coluna para o parâmetro x.
O gráfico KDE criado exibe uma curva em formato de sino, característica que se assemelha a uma distribuição normal com média em torno de 52°F.
Caso deseje explorar mais sobre a função KDE plot, consulte a documentação do kdeplot().
Deslize para começar a programar
- Utilize a função correta para criar um gráfico KDE.
- Utilize
countries_dfcomo os dados para o gráfico (primeiro argumento). - Defina
'GDP per capita'como a coluna a ser utilizada e a orientação como horizontal por meio do segundo argumento. - Preencha a área sob a curva utilizando o terceiro (último) argumento.
Solução
Obrigado pelo seu feedback!
single
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
