Gráfico Conjunto
Joint plot é um gráfico bastante único, pois combina múltiplos gráficos. É um gráfico que mostra a relação entre duas variáveis juntamente com suas distribuições individuais.
Um joint plot combina três elementos:
- um histograma na parte superior (distribuição da variável x);
- um histograma à direita (distribuição da variável y);
- um gráfico de dispersão no centro (relação entre as duas variáveis).
Veja um exemplo:
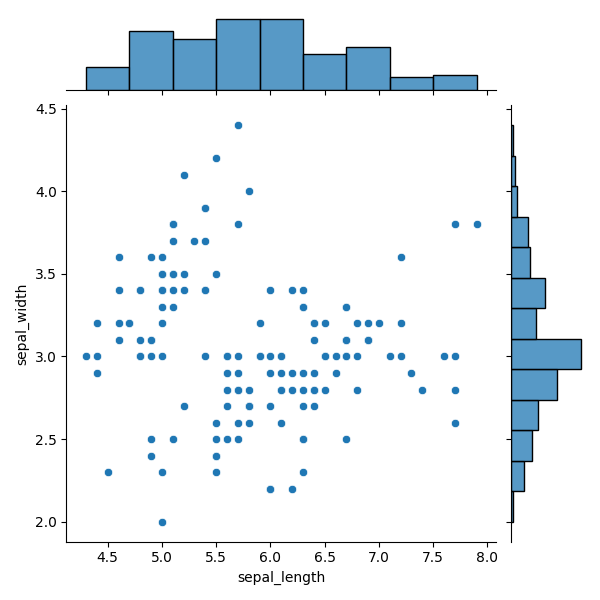
Dados para o Joint Plot
seaborn.jointplot() utiliza três parâmetros principais:
data— o DataFrame,x— variável para o histograma superior,y— variável para o histograma à direita.
x e y podem ser nomes de colunas ou objetos semelhantes a arrays.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
O exemplo é recriado passando um DataFrame para data e especificando nomes de colunas para x e y.
Gráfico no Centro
O parâmetro kind controla o tipo de gráfico central.
Padrão: 'scatter'.
Outras opções incluem: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Tipos de Gráfico
Além de scatter, é possível escolher:
- reg — adiciona ajuste de regressão linear;
- resid — plota resíduos da regressão;
- hist — histograma bivariado;
- kde — KDE para duas variáveis;
- hex — gráfico hexbin mostrando densidade com hexágonos coloridos.
Como de costume, é possível explorar mais opções e parâmetros na documentação do jointplot().
Também vale a pena explorar os seguintes tópicos:
documentação do residplot();
Exemplo de histograma bivariado;
Exemplo de gráfico hexbin.
Obrigado pelo seu feedback!
single
Gráfico Conjunto
Deslize para mostrar o menu
Joint plot é um gráfico bastante único, pois combina múltiplos gráficos. É um gráfico que mostra a relação entre duas variáveis juntamente com suas distribuições individuais.
Um joint plot combina três elementos:
- um histograma na parte superior (distribuição da variável x);
- um histograma à direita (distribuição da variável y);
- um gráfico de dispersão no centro (relação entre as duas variáveis).
Veja um exemplo:
Dados para o Joint Plot
seaborn.jointplot() utiliza três parâmetros principais:
data— o DataFrame,x— variável para o histograma superior,y— variável para o histograma à direita.
x e y podem ser nomes de colunas ou objetos semelhantes a arrays.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
O exemplo é recriado passando um DataFrame para data e especificando nomes de colunas para x e y.
Gráfico no Centro
O parâmetro kind controla o tipo de gráfico central.
Padrão: 'scatter'.
Outras opções incluem: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Tipos de Gráfico
Além de scatter, é possível escolher:
- reg — adiciona ajuste de regressão linear;
- resid — plota resíduos da regressão;
- hist — histograma bivariado;
- kde — KDE para duas variáveis;
- hex — gráfico hexbin mostrando densidade com hexágonos coloridos.
Como de costume, é possível explorar mais opções e parâmetros na documentação do jointplot().
Também vale a pena explorar os seguintes tópicos:
documentação do residplot();
Exemplo de histograma bivariado;
Exemplo de gráfico hexbin.
Deslize para começar a programar
- Utilize a função correta para criar um joint plot.
- Utilize
weather_dfcomo o conjunto de dados para o gráfico (primeiro argumento). - Defina a coluna
'Boston'como variável do eixo x (segundo argumento). - Defina a coluna
'Seattle'como variável do eixo y (terceiro argumento). - Configure o gráfico central para exibir uma linha de regressão (argumento mais à direita).
Solução
Obrigado pelo seu feedback!
single
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
