Visão Geral dos Modelos Populares de CNN
Deslize para mostrar o menu
Redes neurais convolucionais (CNNs) evoluíram significativamente, com diversas arquiteturas aprimorando precisão, eficiência e escalabilidade. Este capítulo explora cinco modelos principais de CNN que moldaram o deep learning: LeNet, AlexNet, VGGNet, ResNet e InceptionNet.
LeNet: A Fundação das CNNs
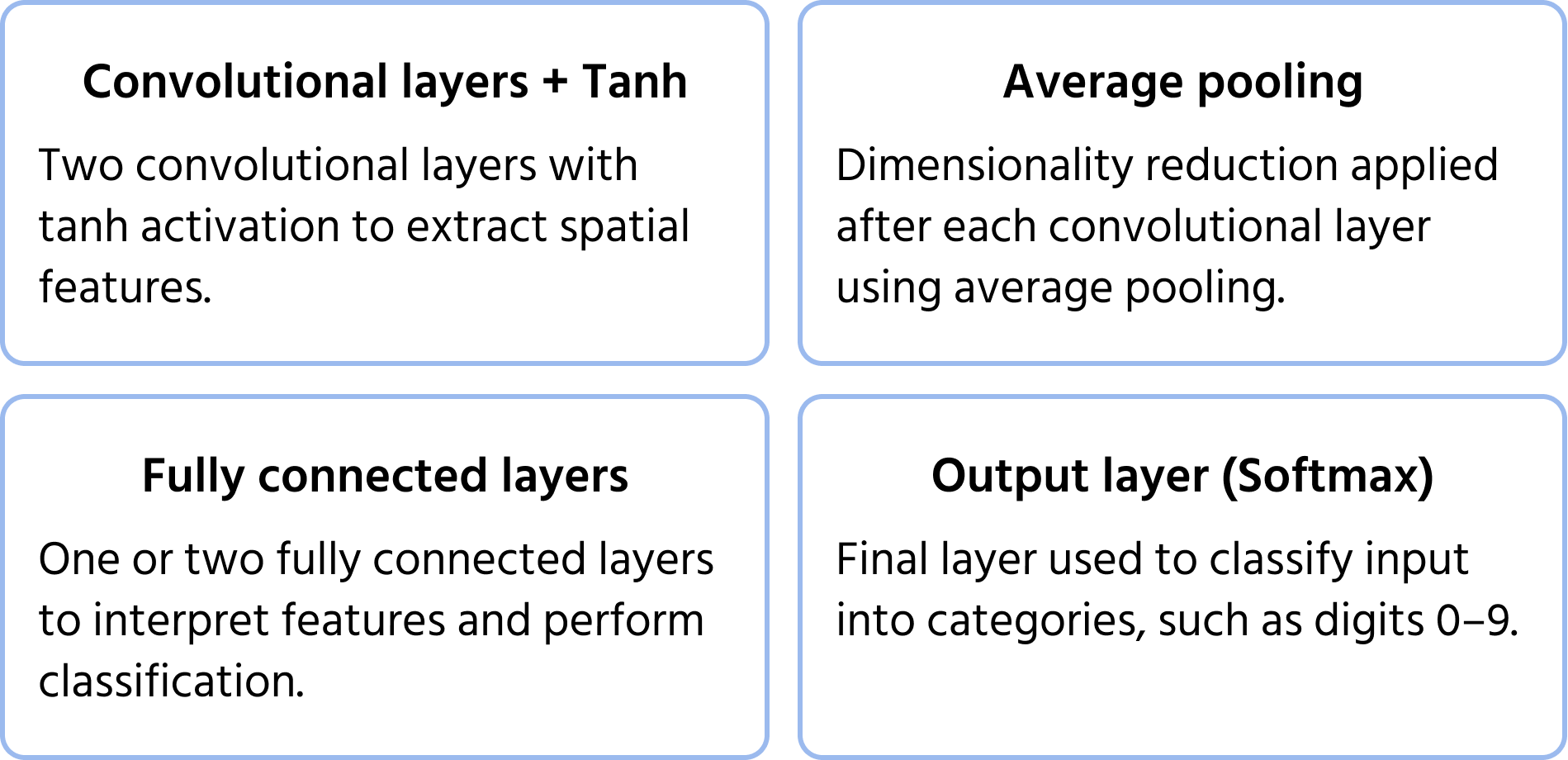
Uma das primeiras arquiteturas de redes neurais convolucionais, proposta por Yann LeCun em 1998 para reconhecimento de dígitos manuscritos. Estabeleceu as bases para as CNNs modernas ao introduzir componentes essenciais como convoluções, pooling e camadas totalmente conectadas. Saiba mais sobre o modelo na documentação.
Principais Características da Arquitetura
AlexNet: Avanço em Deep Learning
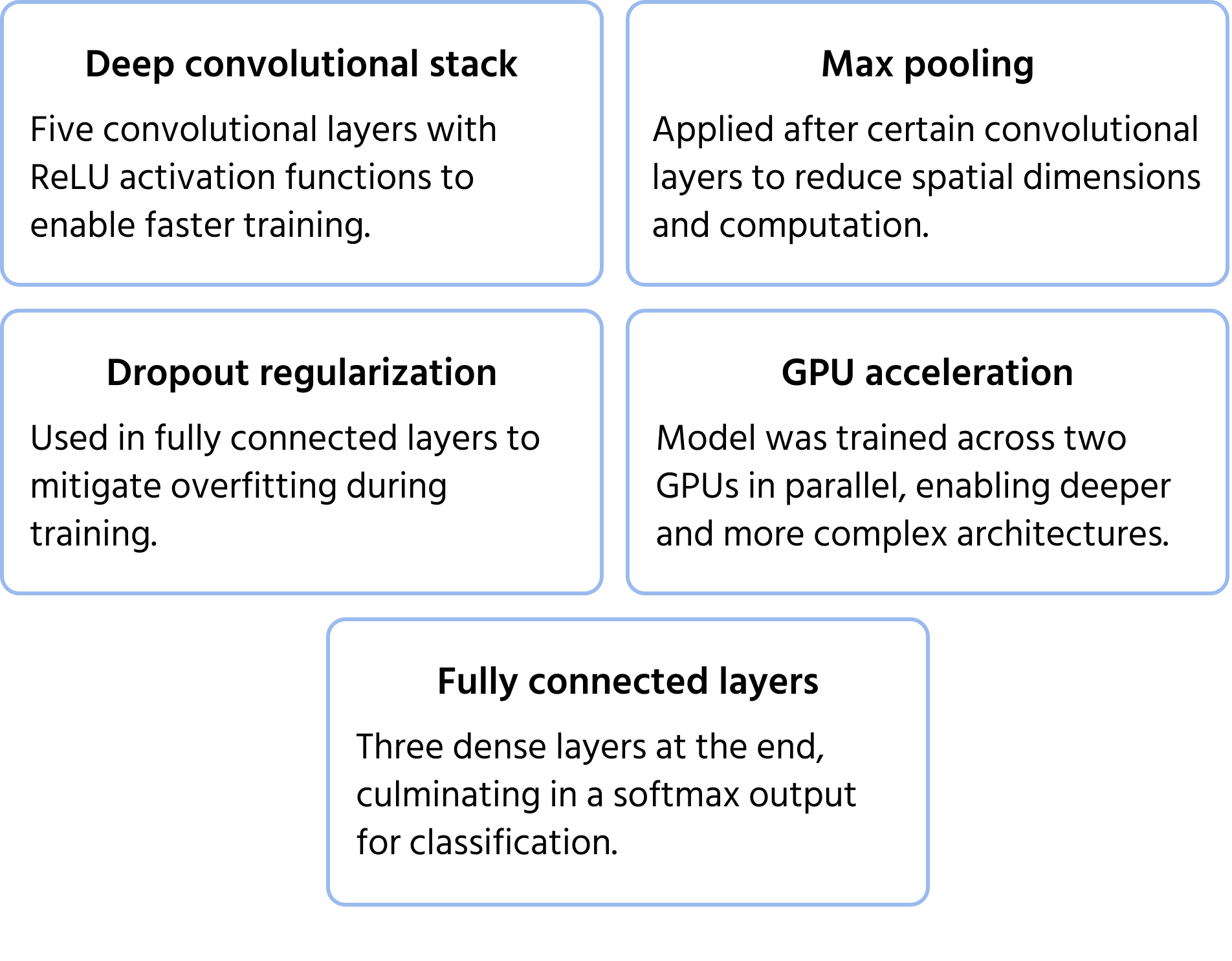
Uma arquitetura de CNN marcante que venceu a competição ImageNet de 2012, AlexNet demonstrou que redes neurais convolucionais profundas poderiam superar significativamente os métodos tradicionais de aprendizado de máquina para classificação de imagens em larga escala. Introduziu inovações que se tornaram padrão no deep learning moderno. Saiba mais sobre o modelo na documentação.
Principais Características da Arquitetura
VGGNet: Redes Profundas com Filtros Uniformes
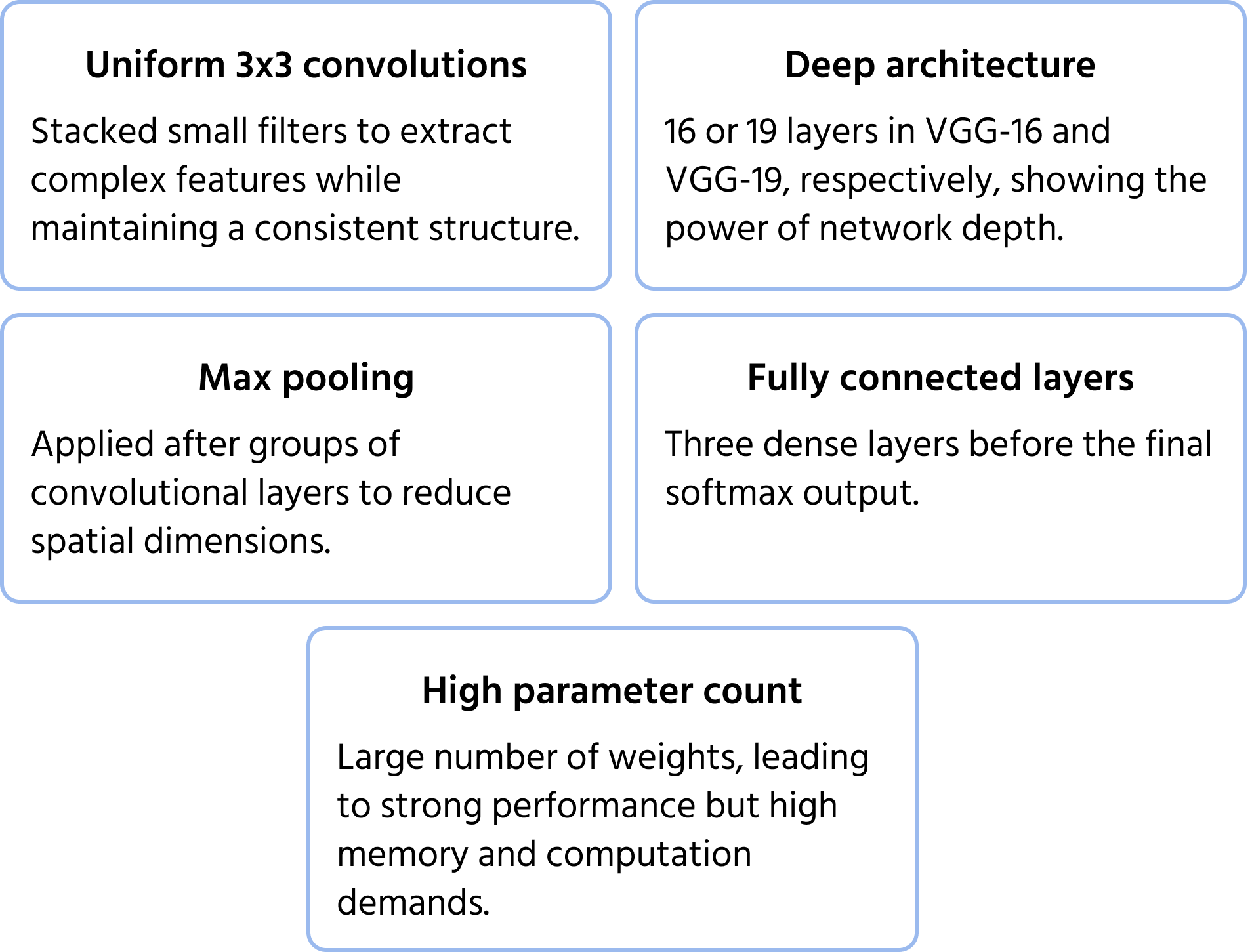
Desenvolvida pelo Visual Geometry Group da Universidade de Oxford, a VGGNet destacou a profundidade e simplicidade ao utilizar filtros convolucionais uniformes de 3×3. Demonstrou que o empilhamento de pequenos filtros em redes profundas pode melhorar significativamente o desempenho, originando variantes amplamente utilizadas como VGG-16 e VGG-19. Saiba mais sobre o modelo na documentação.
Principais Características da Arquitetura
ResNet: Solução para o Problema de Profundidade
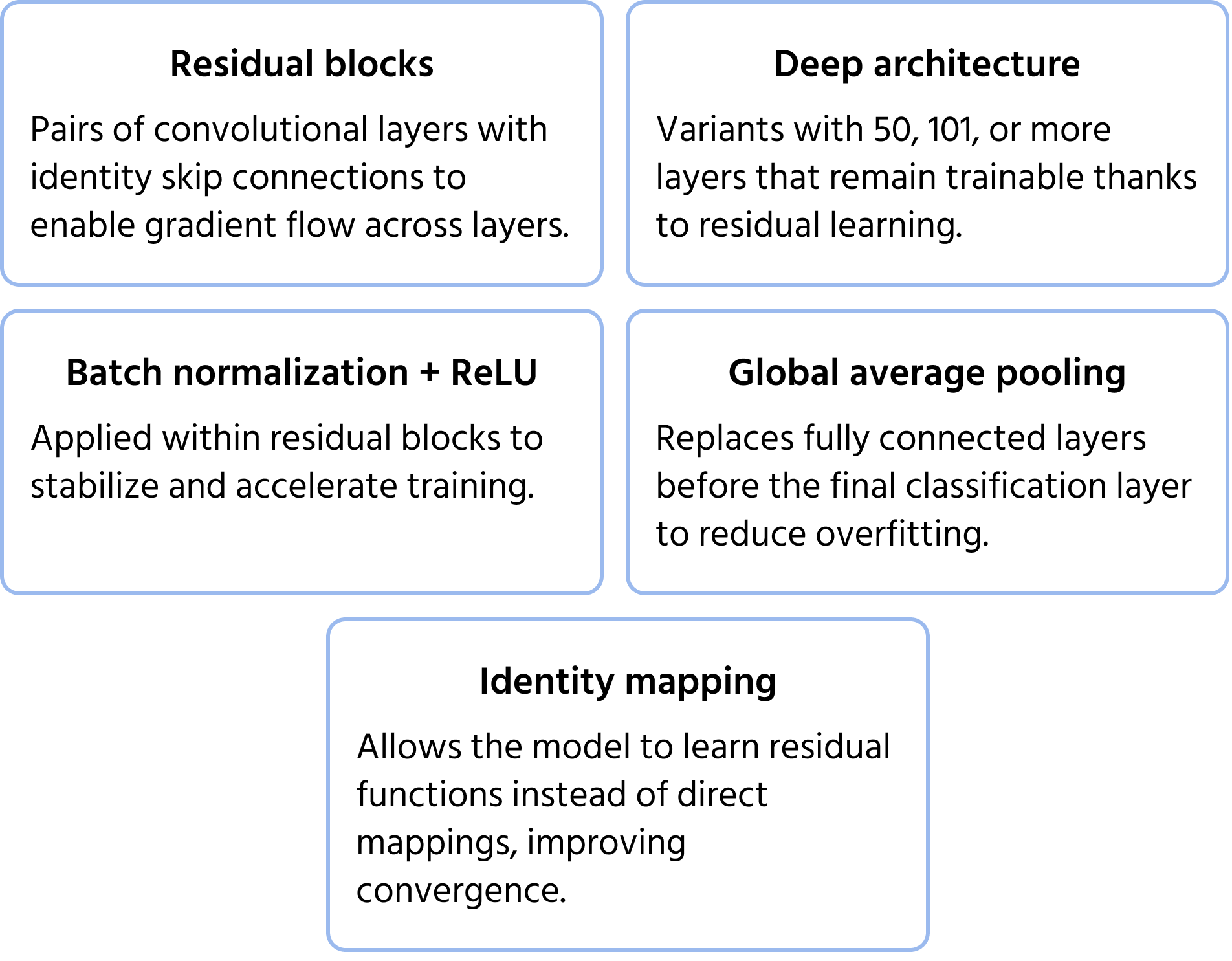
ResNet (Redes Residuais), introduzida pela Microsoft em 2015, abordou o problema do gradiente que desaparece, que ocorre durante o treinamento de redes muito profundas. Redes profundas tradicionais apresentam dificuldades de eficiência de treinamento e degradação de desempenho, mas a ResNet superou esse desafio com conexões de atalho (aprendizado residual). Esses atalhos permitem que a informação ignore certas camadas, garantindo que os gradientes continuem a se propagar de forma eficaz. Arquiteturas ResNet, como ResNet-50 e ResNet-101, possibilitaram o treinamento de redes com centenas de camadas, melhorando significativamente a precisão na classificação de imagens. Saiba mais sobre o modelo na documentação.
Principais Características da Arquitetura
InceptionNet: Extração de Características em Múltiplas Escalas
InceptionNet (também conhecida como GoogLeNet) baseia-se no módulo inception para criar uma arquitetura profunda e eficiente. Em vez de empilhar camadas sequencialmente, a InceptionNet utiliza caminhos paralelos para extrair características em diferentes níveis. Saiba mais sobre o modelo na documentação.
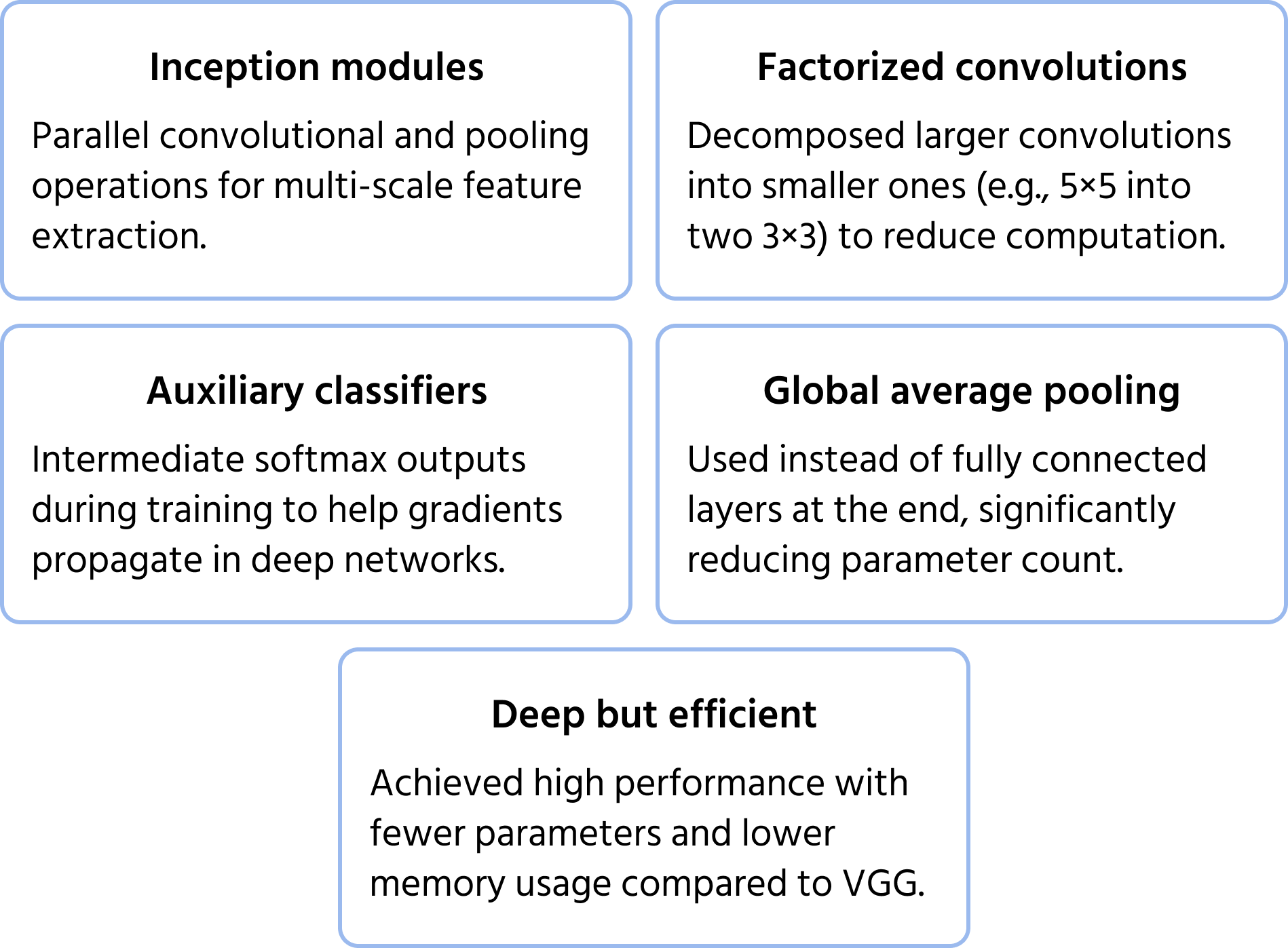
Principais otimizações incluem:
- Convoluções fatoradas para reduzir o custo computacional;
- Classificadores auxiliares em camadas intermediárias para melhorar a estabilidade do treinamento;
- Pooling global por média em vez de camadas totalmente conectadas, reduzindo o número de parâmetros e mantendo o desempenho.
Essa estrutura permite que a InceptionNet seja mais profunda que CNNs anteriores como a VGG, sem aumentar drasticamente os requisitos computacionais.
Principais Características da Arquitetura
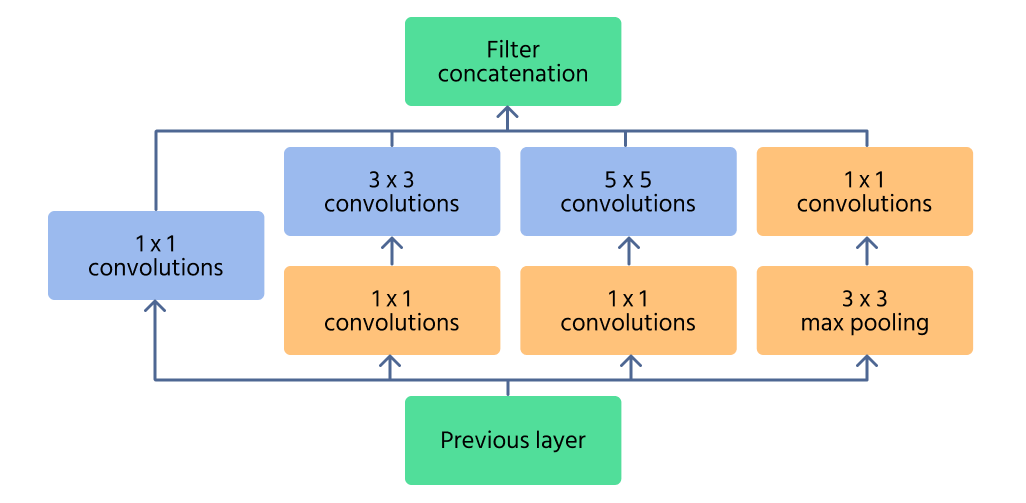
Módulo Inception
O módulo Inception é o componente central do InceptionNet, projetado para capturar eficientemente características em múltiplas escalas. Em vez de aplicar uma única operação de convolução, o módulo processa a entrada com múltiplos tamanhos de filtro (1×1, 3×3, 5×5) em paralelo. Isso permite que a rede reconheça tanto detalhes finos quanto padrões amplos em uma imagem.
Para reduzir o custo computacional, 1×1 convolutions são utilizadas antes da aplicação de filtros maiores. Estas reduzem o número de canais de entrada, tornando a rede mais eficiente. Além disso, camadas de max pooling dentro do módulo ajudam a reter características essenciais enquanto controlam a dimensionalidade.
Exemplo
Considere um exemplo para entender como a redução de dimensões diminui a carga computacional. Suponha que seja necessário convoluir 28 × 28 × 192 input feature maps com 5 × 5 × 32 filters. Essa operação exigiria aproximadamente 120,42 milhões de cálculos.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Vamos realizar os cálculos novamente, mas desta vez, inserir uma 1×1 convolutional layer antes de aplicar a 5×5 convolution aos mesmos mapas de características de entrada.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Cada uma dessas arquiteturas de CNN desempenhou um papel fundamental no avanço da visão computacional, influenciando aplicações em saúde, sistemas autônomos, segurança e processamento de imagens em tempo real. Dos princípios fundamentais do LeNet à extração de características em múltiplas escalas do InceptionNet, esses modelos têm continuamente expandido os limites do aprendizado profundo, abrindo caminho para arquiteturas ainda mais avançadas no futuro.
1. Qual foi a principal inovação introduzida pelo ResNet que permitiu o treinamento de redes extremamente profundas?
2. Como o InceptionNet melhora a eficiência computacional em comparação com CNNs tradicionais?
3. Qual arquitetura de CNN introduziu primeiro o conceito de utilizar pequenos filtros de convolução 3×3 em toda a rede?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
