single
Implementação de Rede Neural
Deslize para mostrar o menu
Visão Geral de uma Rede Neural Básica
Você chegou a um estágio em que possui o conhecimento essencial de TensorFlow para criar redes neurais por conta própria. Embora a maioria das redes neurais do mundo real seja complexa e normalmente construída usando bibliotecas de alto nível como o Keras, construiremos uma rede básica utilizando ferramentas fundamentais do TensorFlow. Essa abordagem proporciona experiência prática com manipulação de tensores em baixo nível, ajudando a compreender os processos subjacentes.
Em cursos anteriores como Introdução às Redes Neurais, você deve se lembrar do tempo e esforço necessários para construir até mesmo uma rede neural simples, tratando cada neurônio individualmente.

O TensorFlow simplifica significativamente esse processo. Ao utilizar tensores, é possível encapsular cálculos complexos, reduzindo a necessidade de codificação detalhada. A principal tarefa é configurar um pipeline sequencial de operações com tensores.
Aqui está um breve lembrete dos passos para iniciar o processo de treinamento de uma rede neural:
Preparação dos Dados e Criação do Modelo
A fase inicial do treinamento de uma rede neural envolve a preparação dos dados, abrangendo tanto os entradas quanto as saídas das quais a rede irá aprender. Além disso, os hiperparâmetros do modelo são definidos - estes são os parâmetros que permanecem constantes durante todo o processo de treinamento. Os pesos são inicializados, normalmente extraídos de uma distribuição normal, e os biases geralmente são definidos como zero.
Propagação Direta
Na propagação direta, cada camada da rede normalmente segue estes passos:
- Multiplicar a entrada da camada pelos seus pesos.
- Adicionar um viés ao resultado.
- Aplicar uma função de ativação a essa soma.
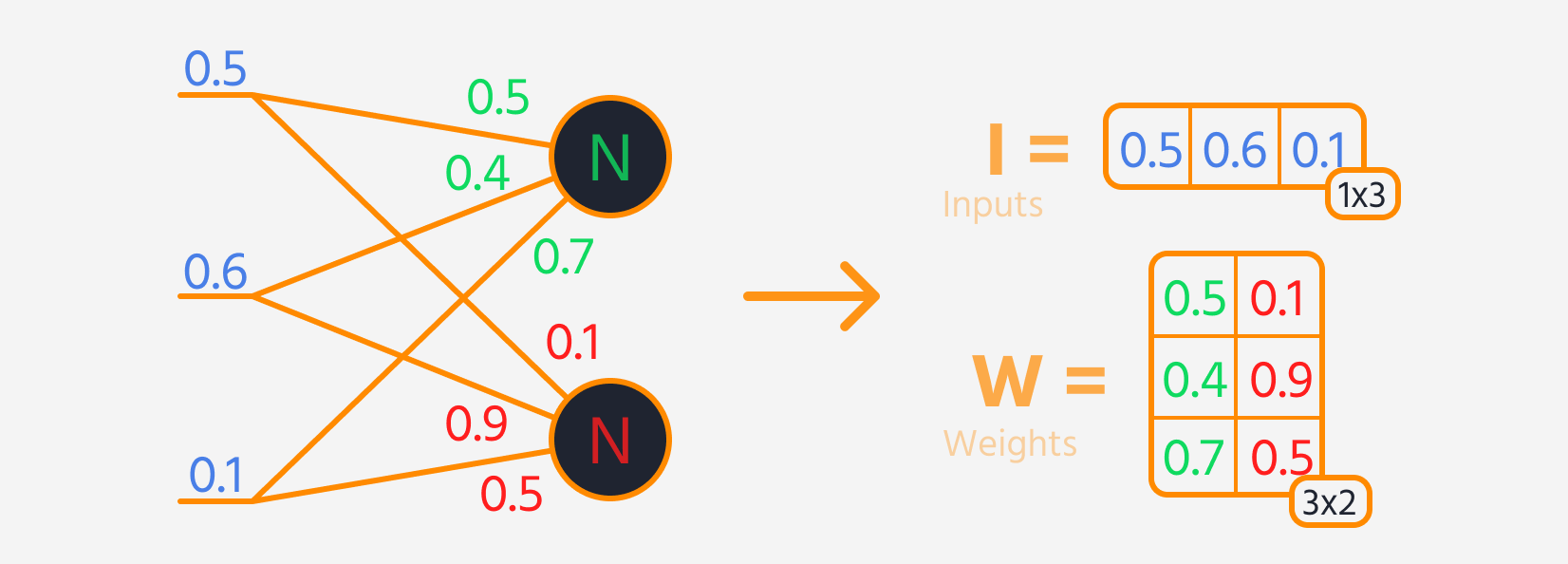
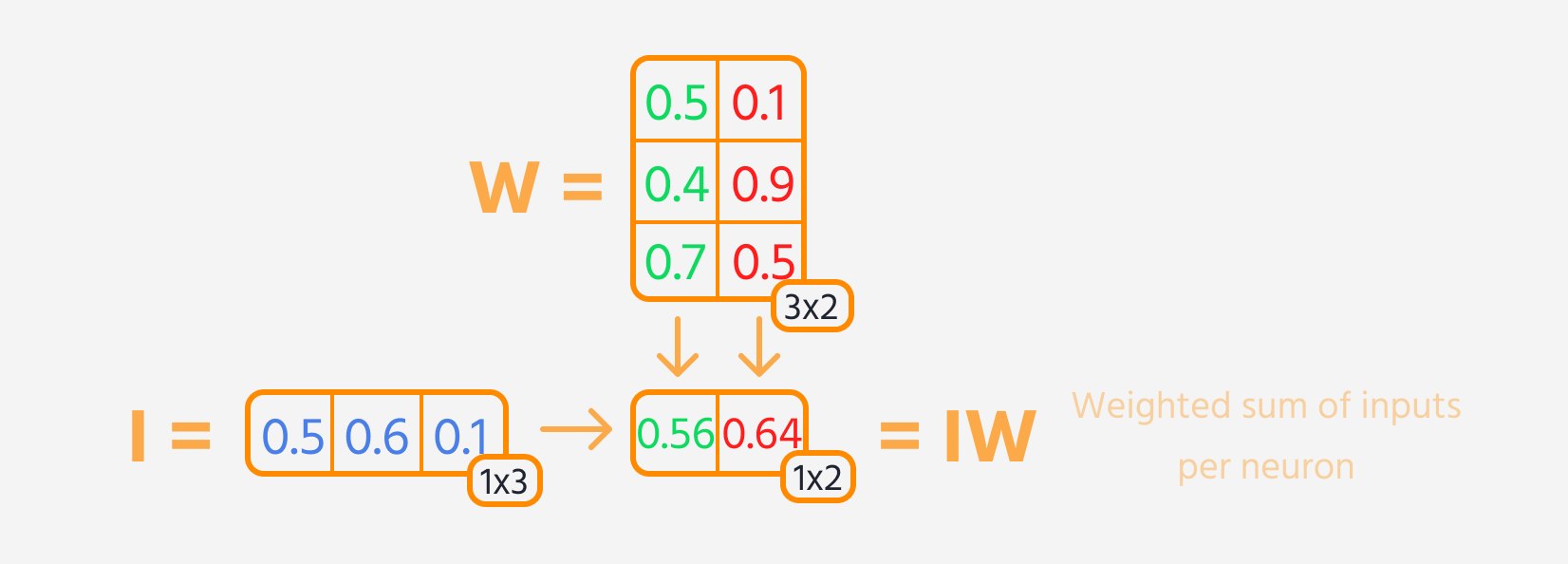
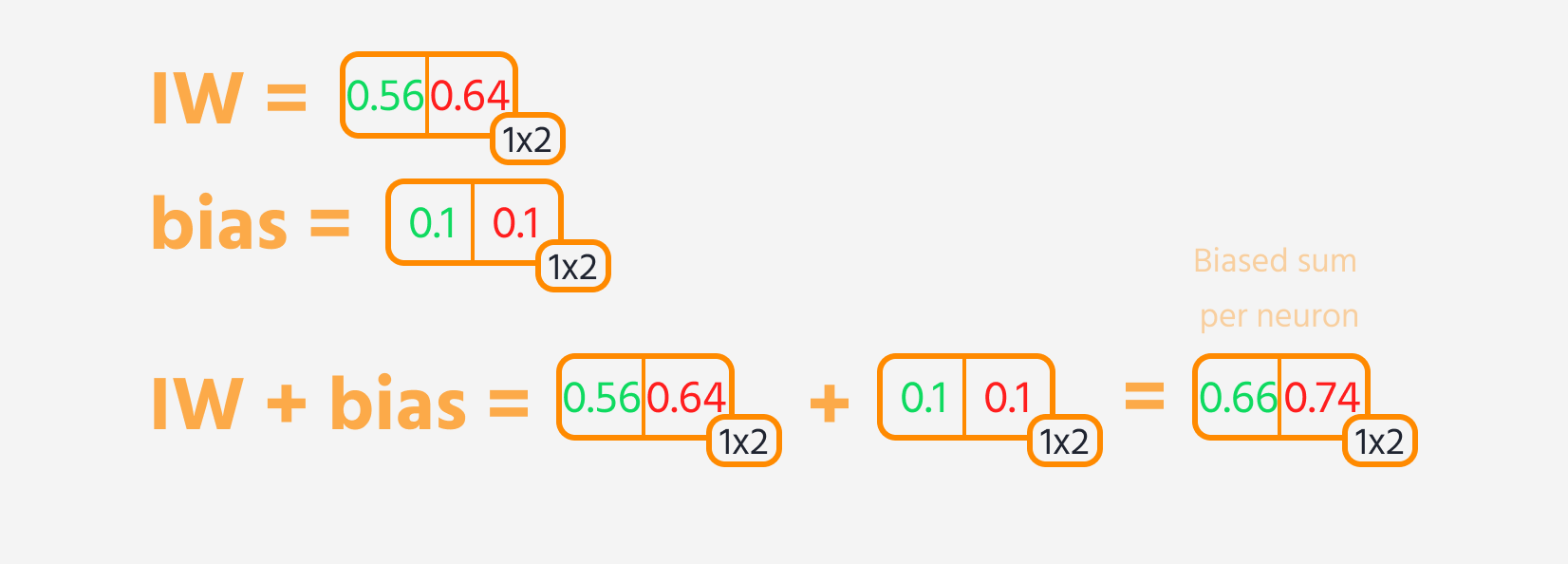


Em seguida, o loss pode ser calculado.
Propagação Reversa
O próximo passo é a propagação reversa, onde ajustamos os pesos e vieses com base em sua influência sobre o loss. Essa influência é representada pelo gradiente, que o Gradient Tape do TensorFlow calcula automaticamente. Atualizamos os pesos e vieses subtraindo o gradiente, escalado pela taxa de aprendizado.
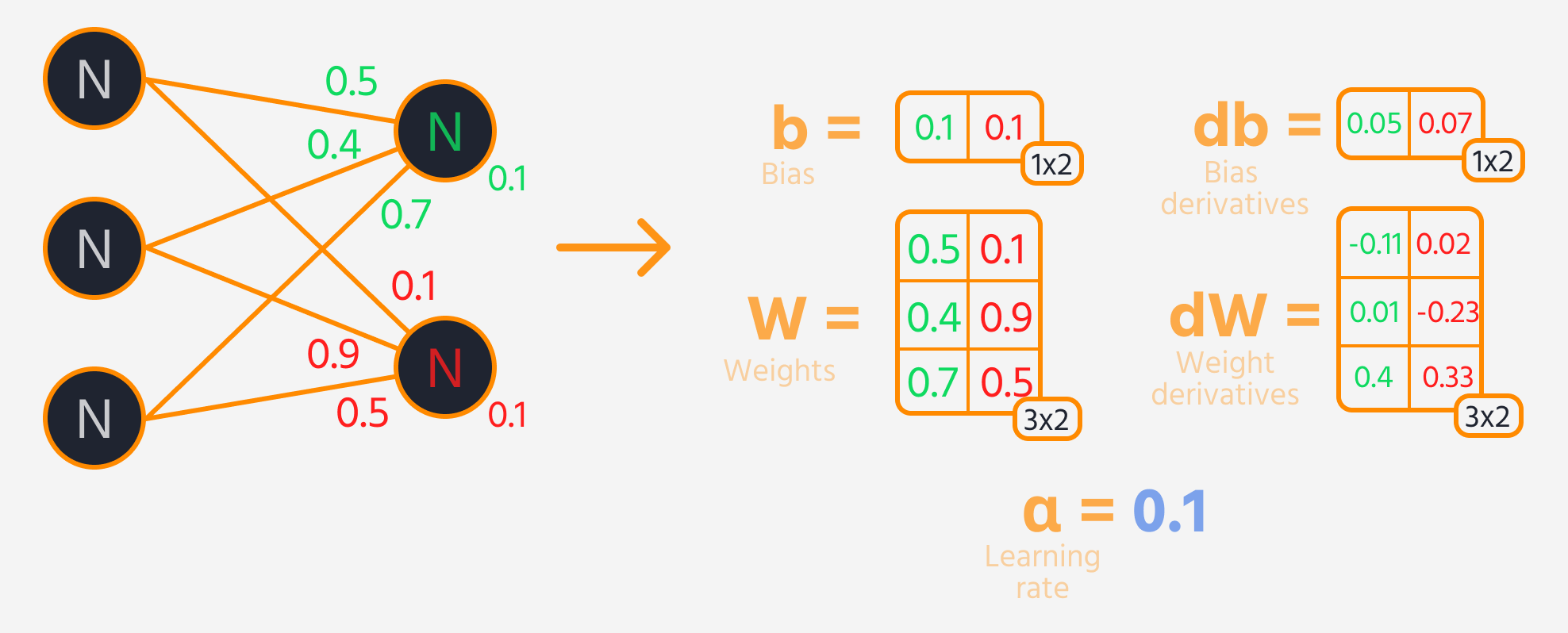
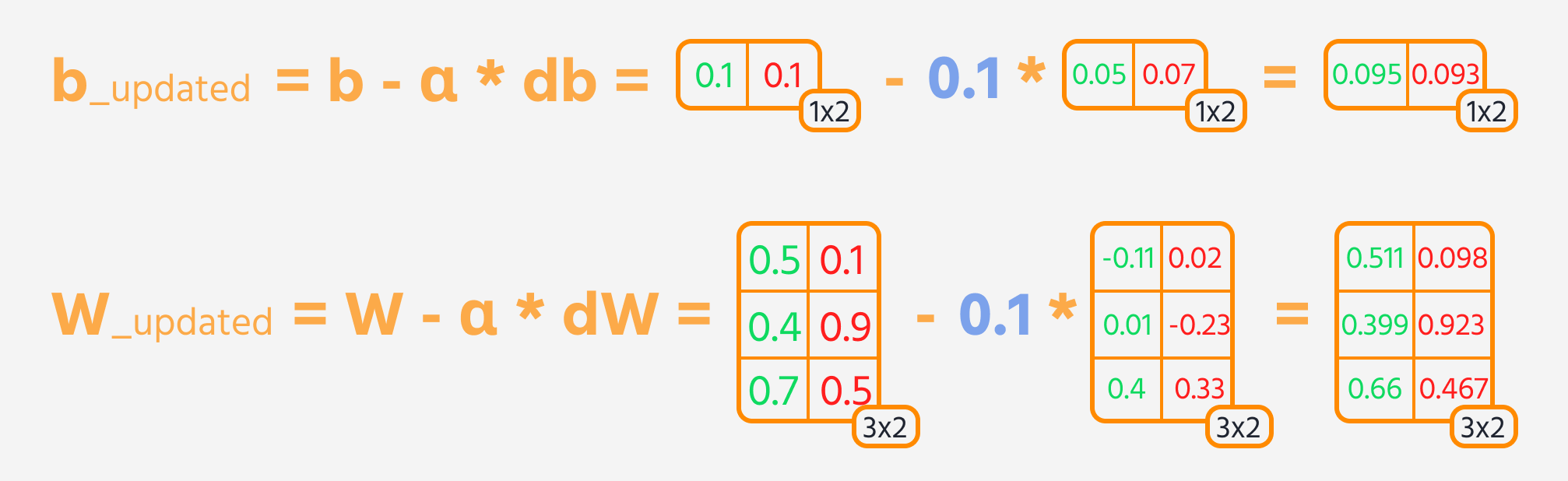
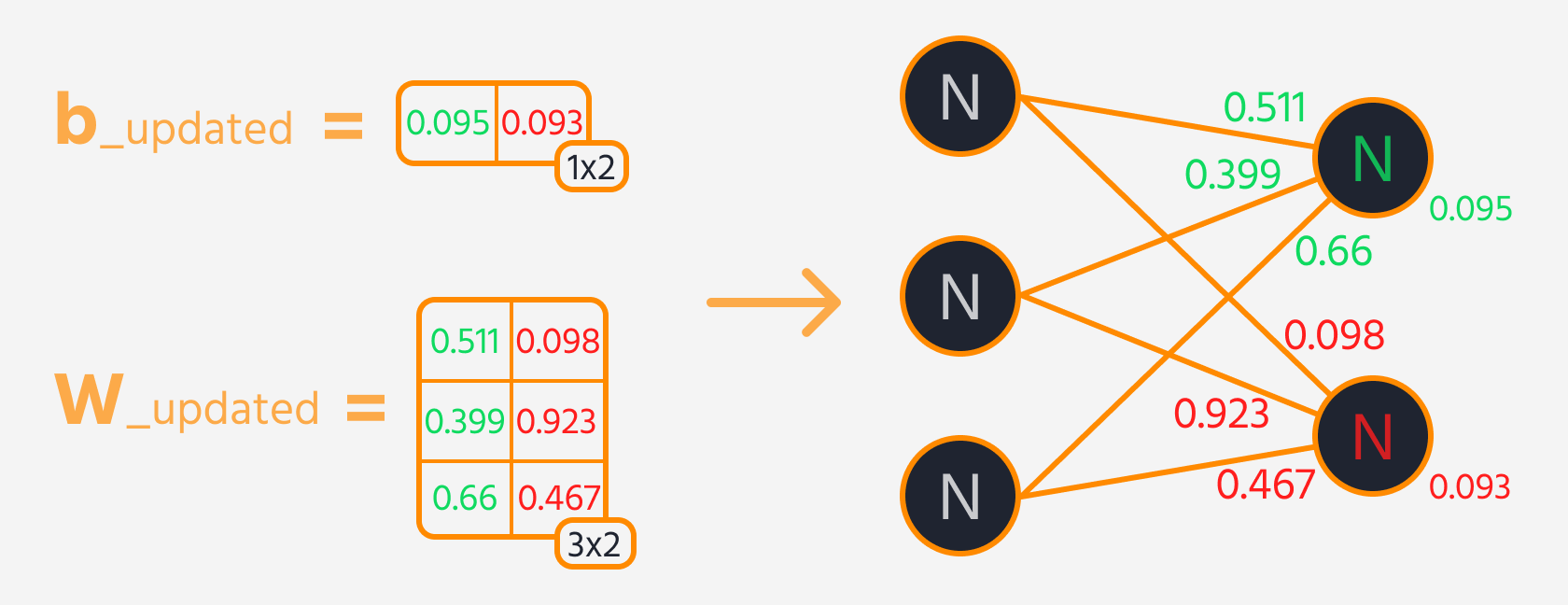
Loop de Treinamento
Para treinar a rede neural de forma eficaz, os passos de treinamento são repetidos várias vezes enquanto se acompanha o desempenho do modelo. Idealmente, a perda deve diminuir ao longo das épocas.
Deslize para começar a programar
Criação de uma rede neural projetada para prever os resultados da operação XOR. A rede deve consistir em 2 neurônios de entrada, uma camada oculta com 2 neurônios e 1 neurônio de saída.
- Iniciar pela configuração dos pesos e vieses iniciais. Os pesos devem ser inicializados utilizando uma distribuição normal, e todos os vieses devem ser inicializados em zero. Utilize os hiperparâmetros
input_size,hidden_sizeeoutput_sizepara definir os formatos adequados desses tensores. - Utilizar um decorador de função para transformar a função
train_step()em um grafo do TensorFlow. - Realizar a propagação direta pelas camadas oculta e de saída da rede. Utilizar a função de ativação sigmoide.
- Determinar os gradientes para compreender como cada peso e viés impacta a perda. Certifique-se de que os gradientes sejam calculados na ordem correta, correspondente aos nomes das variáveis de saída.
- Modificar os pesos e vieses com base em seus respectivos gradientes. Incorporar o
learning_ratenesse processo de ajuste para controlar a intensidade de cada atualização.
Solução
Preparação dos Dados
X_data: estes são os dados de entrada para a função XOR. É um array NumPy de formato (4, 2), representando as quatro combinações possíveis das entradas do XOR (0,0), (0,1), (1,0) e (1,1);Y_data: este é o alvo de saída para cada combinação de entrada emX_data. Também é um array NumPy, mas de formato (4, 1), representando a saída do XOR para cada par de entrada.
Parâmetros da Rede
input_size: o tamanho da camada de entrada, definido como 2, correspondente aos dois nós de entrada (para as duas entradas da função XOR);hidden_size: o tamanho da camada oculta, também definido como 2. Essa escolha é um tanto arbitrária, mas suficiente para aprender a função XOR;output_size: o tamanho da camada de saída, definido como 1, correspondente ao único nó de saída (o resultado da operação XOR);learning_rate: taxa de aprendizado para o algoritmo de otimização, controlando o quanto os pesos são ajustados durante o treinamento.
Pesos e Biases
W1eb1: os pesos (W1) e biases (b1) para as conexões da camada de entrada para a camada oculta.W1é uma variável do TensorFlow inicializada com valores aleatórios e tem formato(input_size, hidden_size), ou seja,(2, 2).b1é uma variável do TensorFlow inicializada com zeros e tem formato(hidden_size), ou seja,(2);W2eb2: os pesos (W2) e biases (b2) para as conexões da camada oculta para a camada de saída.W2é inicializado com valores aleatórios e tem formato(hidden_size, output_size), ou seja,(2, 1).b2é inicializado com zeros e tem formato(output_size), ou seja,(1).
Função de Treinamento
train_step(): esta é a função principal de treinamento. Utilizatf.GradientTape()para diferenciação automática. No passo direto, calcula as ativações da camada oculta (a1) e as previsões de saída (Y_pred). A perda é calculada como o Erro Quadrático Médio entreY_predeY. A função então calcula os gradientes e atualiza os pesos e biases;tf.sigmoid(): uma função de ativação sigmoide é utilizada, transformando a entrada em um valor entre0e1. Isso é usado tanto para a camada oculta quanto para a camada de saída.
Loop de Treinamento
- A rede é treinada por
2500épocas. Em cada época, a funçãotrain_step()é chamada e os pesos são atualizados. A perda é impressa a cada500épocas para monitorar o progresso do treinamento.
Conclusão
Como a função XOR é uma tarefa relativamente simples, não é necessário utilizar técnicas avançadas como ajuste de hiperparâmetros, divisão de conjuntos de dados ou construção de pipelines de dados complexos neste estágio. Este exercício é apenas um passo em direção à construção de redes neurais mais sofisticadas para aplicações do mundo real.
Dominar esses conceitos básicos é fundamental antes de avançar para técnicas mais avançadas de construção de redes neurais nos próximos cursos, onde utilizaremos a biblioteca Keras e exploraremos métodos para aprimorar a qualidade do modelo com os recursos avançados do TensorFlow.
Obrigado pelo seu feedback!
single
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
