Introdução às Redes Neurais Convolucionais
Deslize para mostrar o menu
O que é uma CNN e por que ela é diferente das redes neurais tradicionais?
Uma rede neural convolucional (CNN) é um tipo de inteligência artificial que ajuda os computadores a "enxergar" e compreender imagens. Diferente das redes neurais comuns, que processam imagens como uma lista de números, as CNNs analisam as imagens em seções, reconhecendo padrões como bordas, formas e texturas. Isso as torna muito mais eficientes no processamento de fotos e vídeos.
Como as CNNs são inspiradas no olho humano
As CNNs funcionam de maneira semelhante à forma como o cérebro humano processa imagens. Quando olhamos para algo, nossos olhos enviam informações ao cérebro, que primeiro reconhece formas simples como bordas e cores. Em seguida, camadas mais profundas do cérebro juntam essas partes para compreender objetos, rostos ou cenas inteiras. As CNNs seguem essa mesma ideia, começando por características simples e evoluindo para reconhecer objetos complexos.
Assim como nossos olhos focam em certas áreas, as CNNs também processam imagens em pequenas seções, o que as ajuda a reconhecer padrões independentemente de onde apareçam. No entanto, ao contrário dos humanos, as CNNs precisam de milhares de imagens rotuladas para aprender, enquanto as pessoas conseguem reconhecer objetos mesmo tendo visto poucas vezes.
Visão geral dos principais componentes: Convolução, Pooling, Ativação e Camadas Totalmente Conectadas
Uma CNN é composta por múltiplas camadas, cada uma desempenhando um papel distinto no processamento de imagens:
- Aplicação de filtros (kernels) para detectar padrões como bordas, texturas e formas;
- Utilização de stride e padding para controlar as dimensões do mapa de características;
- Geração de múltiplos mapas de características para extração profunda de atributos.
- Introdução de não-linearidade, permitindo que as CNNs aprendam representações complexas;
- Funções comuns incluem ReLU (Unidade Linear Retificada), Leaky ReLU e Sigmoid.
- Redução das dimensões espaciais dos mapas de características enquanto preserva informações importantes;
- Tipos incluem max pooling (captura características dominantes) e average pooling (suaviza representações);
- Auxilia em invariância à translação e eficiência computacional.
- Achatamento dos mapas de características em um vetor 1D para classificação;
- Conexão com a camada de saída final utilizando Softmax (para classificação multiclasse) ou Sigmoid (para classificação binária).
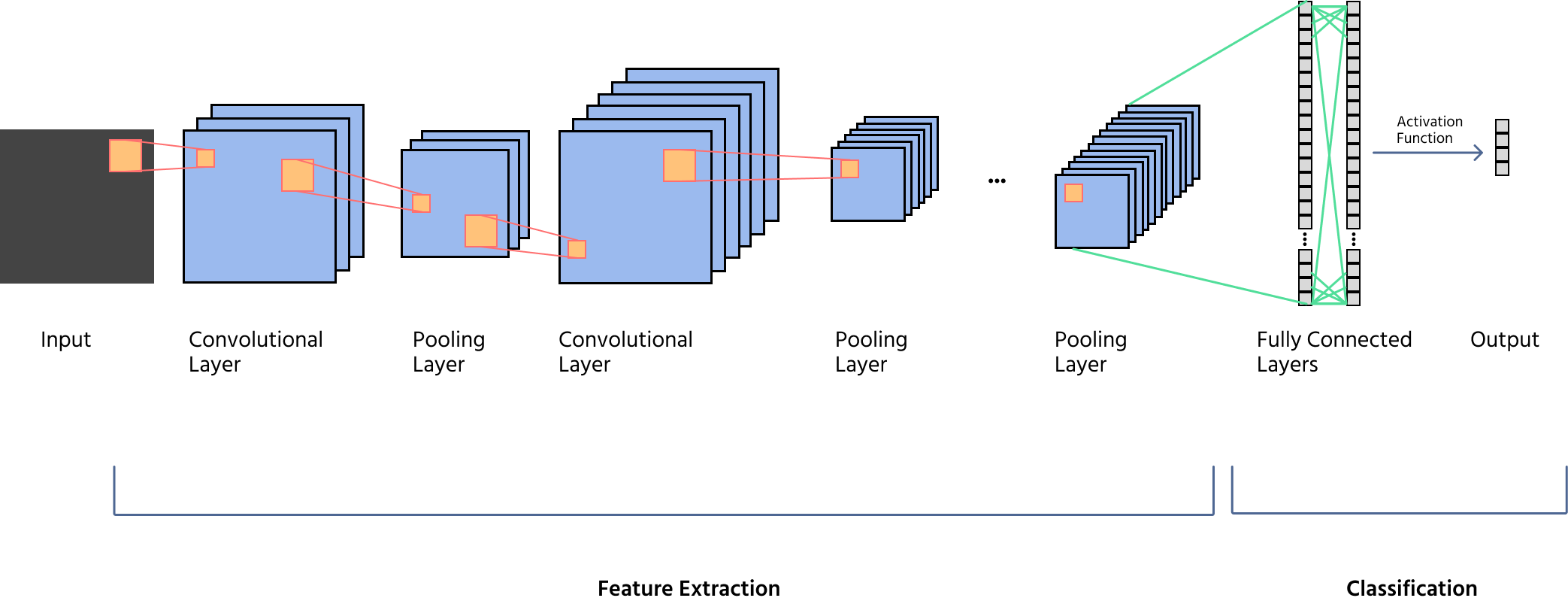
As CNNs são poderosas porque podem aprender automaticamente características a partir de imagens, sem a necessidade de que humanos programem cada detalhe. Por isso, são utilizadas em carros autônomos, reconhecimento facial, imagens médicas e muitas outras aplicações do mundo real.
1. Qual é a principal vantagem das CNNs em relação às redes neurais tradicionais ao processar imagens?
2. Associe o elemento da CNN à sua função.
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
