Funções de Ativação
Deslize para mostrar o menu
Por que as Funções de Ativação são Cruciais em CNNs
Funções de ativação introduzem não linearidade nas CNNs, permitindo que aprendam padrões complexos além do que um modelo linear simples pode alcançar. Sem funções de ativação, as CNNs teriam dificuldade em detectar relações intrincadas nos dados, limitando sua eficácia em reconhecimento e classificação de imagens. A escolha adequada da função de ativação influencia a velocidade de treinamento, estabilidade e desempenho geral.
Funções de Ativação Comuns
- ReLU (unidade linear retificada): a função de ativação mais utilizada em CNNs. Permite apenas valores positivos, definindo todas as entradas negativas como zero, o que a torna computacionalmente eficiente e previne o desaparecimento do gradiente. No entanto, alguns neurônios podem se tornar inativos devido ao problema do "ReLU morto";

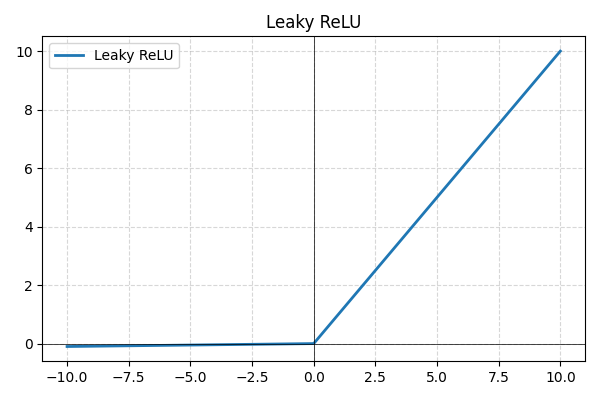
- Leaky ReLU: uma variação da ReLU que permite pequenos valores negativos em vez de defini-los como zero, evitando neurônios inativos e melhorando o fluxo do gradiente;
- Sigmoid: comprime valores de entrada em um intervalo entre 0 e 1, sendo útil para classificação binária. No entanto, apresenta o problema de gradientes que desaparecem em redes profundas;

- Tanh: semelhante à Sigmoid, mas produz valores entre -1 e 1, centralizando as ativações em torno de zero;

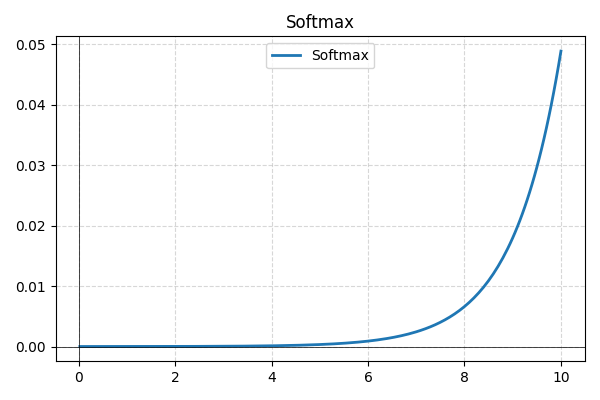
- Softmax: normalmente utilizada na camada final para classificação multiclasse, a Softmax converte as saídas brutas da rede em probabilidades, garantindo que somem um, proporcionando melhor interpretabilidade.
Escolhendo a Função de Ativação Adequada
ReLU é a escolha padrão para camadas ocultas devido à sua eficiência e alto desempenho, enquanto Leaky ReLU é uma opção melhor quando ocorre inatividade de neurônios. Sigmoid e Tanh geralmente são evitadas em CNNs profundas, mas ainda podem ser úteis em aplicações específicas. Softmax permanece essencial para tarefas de classificação multiclasse, garantindo previsões claras baseadas em probabilidade.
Selecionar a função de ativação correta é fundamental para otimizar o desempenho da CNN, equilibrando eficiência e prevenindo problemas como gradientes desaparecendo ou explodindo. Cada função contribui de forma única para o modo como a rede processa e aprende a partir de dados visuais.
1. Por que o ReLU é preferido ao invés do Sigmoid em CNNs profundas?
2. Qual função de ativação é comumente utilizada na camada final de uma CNN para classificação multiclasse?
3. Qual é a principal vantagem do Leaky ReLU em relação ao ReLU padrão?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
Funções de Ativação
Por que as Funções de Ativação são Cruciais em CNNs
Funções de ativação introduzem não linearidade nas CNNs, permitindo que aprendam padrões complexos além do que um modelo linear simples pode alcançar. Sem funções de ativação, as CNNs teriam dificuldade em detectar relações intrincadas nos dados, limitando sua eficácia em reconhecimento e classificação de imagens. A escolha adequada da função de ativação influencia a velocidade de treinamento, estabilidade e desempenho geral.
Funções de Ativação Comuns
- ReLU (unidade linear retificada): a função de ativação mais utilizada em CNNs. Permite apenas valores positivos, definindo todas as entradas negativas como zero, o que a torna computacionalmente eficiente e previne o desaparecimento do gradiente. No entanto, alguns neurônios podem se tornar inativos devido ao problema do "ReLU morto";
- Leaky ReLU: uma variação da ReLU que permite pequenos valores negativos em vez de defini-los como zero, evitando neurônios inativos e melhorando o fluxo do gradiente;
- Sigmoid: comprime valores de entrada em um intervalo entre 0 e 1, sendo útil para classificação binária. No entanto, apresenta o problema de gradientes que desaparecem em redes profundas;
- Tanh: semelhante à Sigmoid, mas produz valores entre -1 e 1, centralizando as ativações em torno de zero;
- Softmax: normalmente utilizada na camada final para classificação multiclasse, a Softmax converte as saídas brutas da rede em probabilidades, garantindo que somem um, proporcionando melhor interpretabilidade.
Escolhendo a Função de Ativação Adequada
ReLU é a escolha padrão para camadas ocultas devido à sua eficiência e alto desempenho, enquanto Leaky ReLU é uma opção melhor quando ocorre inatividade de neurônios. Sigmoid e Tanh geralmente são evitadas em CNNs profundas, mas ainda podem ser úteis em aplicações específicas. Softmax permanece essencial para tarefas de classificação multiclasse, garantindo previsões claras baseadas em probabilidade.
Selecionar a função de ativação correta é fundamental para otimizar o desempenho da CNN, equilibrando eficiência e prevenindo problemas como gradientes desaparecendo ou explodindo. Cada função contribui de forma única para o modo como a rede processa e aprende a partir de dados visuais.
Obrigado pelo seu feedback!
