Visão Geral da Geração de Imagens
Deslize para mostrar o menu
Imagens geradas por IA estão transformando a forma como as pessoas criam arte, design e conteúdo digital. Com o auxílio da inteligência artificial, computadores agora podem produzir imagens realistas, aprimorar trabalhos criativos e até mesmo apoiar empresas. Neste capítulo, serão explorados os processos de criação de imagens por IA, os diferentes tipos de modelos de geração de imagens e suas aplicações no mundo real.
Como a IA Cria Imagens
A geração de imagens por IA funciona aprendendo a partir de uma grande coleção de fotos. A IA analisa padrões nas imagens e, em seguida, cria novas imagens semelhantes. Essa tecnologia evoluiu bastante ao longo dos anos, produzindo imagens cada vez mais realistas e criativas. Atualmente, é utilizada em videogames, filmes, publicidade e até mesmo na moda.
Métodos Iniciais: PixelRNN e PixelCNN
Antes dos modelos avançados de IA atuais, pesquisadores desenvolveram métodos iniciais de geração de imagens, como PixelRNN e PixelCNN. Esses modelos criavam imagens prevendo um pixel de cada vez.
- PixelRNN: utiliza um sistema chamado rede neural recorrente (RNN) para prever as cores dos pixels um após o outro. Embora funcionasse bem, era muito lento;
- PixelCNN: aprimorou o PixelRNN ao utilizar um tipo diferente de rede, chamada camadas convolucionais, tornando a criação de imagens mais rápida.
Apesar de terem sido um bom começo, esses modelos não eram eficientes na produção de imagens de alta qualidade. Isso levou ao desenvolvimento de técnicas mais avançadas.
Modelos Autoregressivos
Modelos autoregressivos também criam imagens um pixel de cada vez, utilizando pixels anteriores para prever o próximo. Esses modelos foram úteis, mas lentos, o que fez com que se tornassem menos populares ao longo do tempo. No entanto, eles ajudaram a inspirar modelos mais novos e rápidos.
Como a IA Compreende Texto para Criação de Imagens
Alguns modelos de IA podem transformar palavras escritas em imagens. Esses modelos utilizam Modelos de Linguagem de Grande Escala (LLMs) para entender descrições e gerar imagens correspondentes. Por exemplo, se você digitar “um gato sentado em uma praia ao pôr do sol”, a IA criará uma imagem baseada nessa descrição.
Modelos de IA como o DALL-E da OpenAI e o Imagen do Google utilizam compreensão avançada de linguagem para melhorar a correspondência entre descrições textuais e as imagens geradas. Isso é possível por meio do Processamento de Linguagem Natural (NLP), que ajuda a IA a converter palavras em números que orientam a criação de imagens.
Redes Generativas Adversariais (GANs)
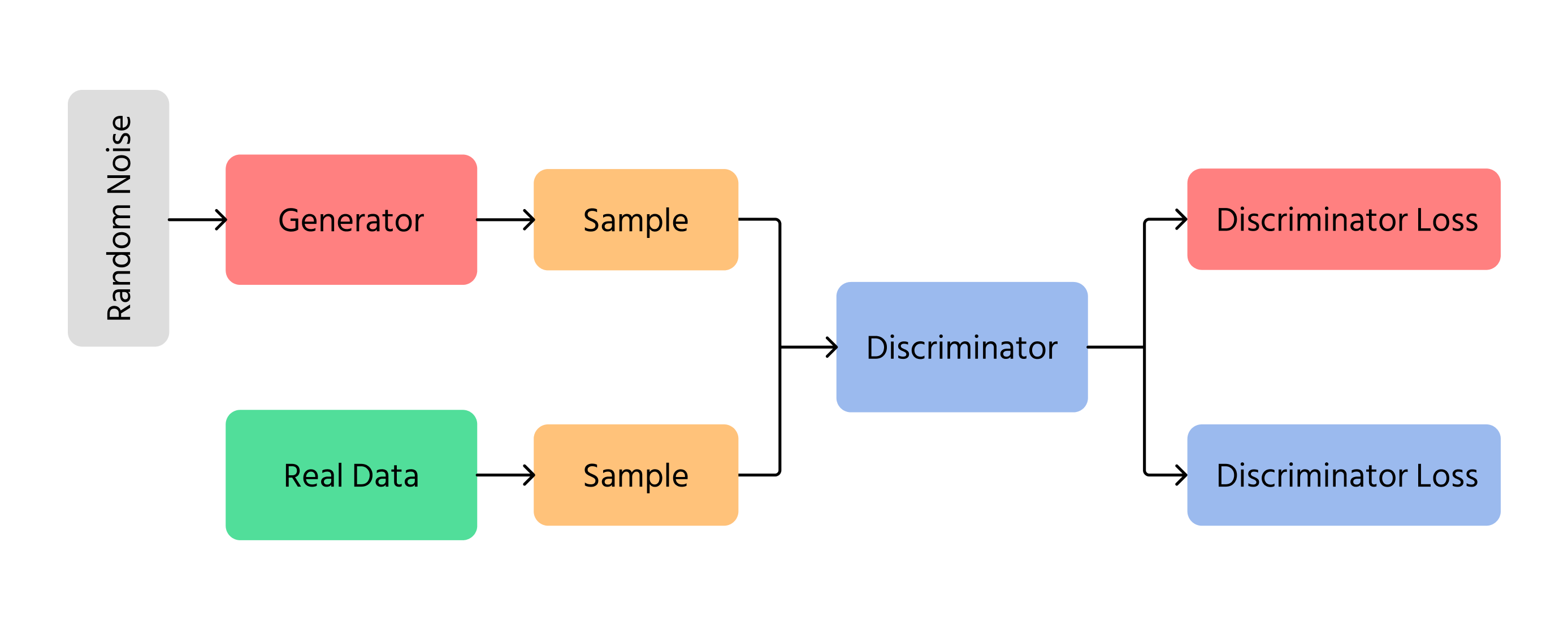
Um dos avanços mais importantes na geração de imagens por IA foi o surgimento das Redes Generativas Adversariais (GANs). As GANs funcionam utilizando duas redes neurais diferentes:
- Gerador: cria novas imagens do zero;
- Discriminador: verifica se as imagens parecem reais ou falsas.
O gerador tenta criar imagens tão realistas que o discriminador não consegue identificar que são falsas. Com o tempo, as imagens melhoram e se assemelham cada vez mais a fotografias reais. As GANs são utilizadas em tecnologia deepfake, criação de obras de arte e aprimoramento da qualidade de imagens.
Autoencoders Variacionais (VAEs)
VAEs são outra abordagem que a IA pode usar para gerar imagens. Em vez de utilizar competição como os GANs, os VAEs codificam e decodificam imagens utilizando probabilidade. Eles funcionam aprendendo os padrões subjacentes de uma imagem e, em seguida, reconstruindo-a com pequenas variações. O elemento probabilístico nos VAEs garante que cada imagem gerada seja ligeiramente diferente, adicionando variedade e criatividade.
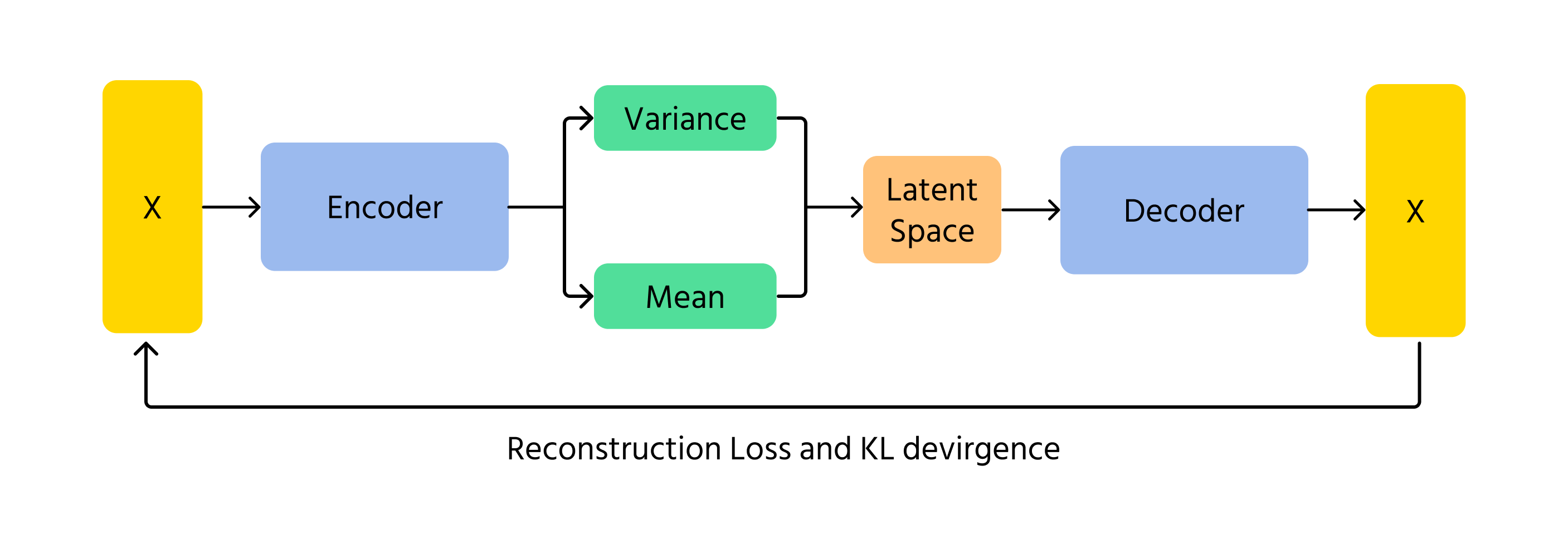
Um conceito fundamental em VAEs é a divergência de Kullback-Leibler (KL), que mede a diferença entre a distribuição aprendida e uma distribuição normal padrão. Ao minimizar a divergência KL, os VAEs garantem que as imagens geradas permaneçam realistas, permitindo ao mesmo tempo variações criativas.
Como funcionam os VAEs
- Codificação: os dados de entrada x são enviados para o codificador, que gera os parâmetros da distribuição do espaço latente q(z∣x) (média μ e variância σ²);
- Amostragem do espaço latente: as variáveis latentes z são amostradas da distribuição q(z∣x) utilizando técnicas como o truque de reparametrização;
- Decodificação e reconstrução: o z amostrado é passado pelo decodificador para produzir os dados reconstruídos x̂, que devem ser semelhantes à entrada original x.
VAEs são úteis para tarefas como reconstrução de rostos, geração de novas versões de imagens existentes e até mesmo para criar transições suaves entre diferentes imagens.
Modelos de Difusão
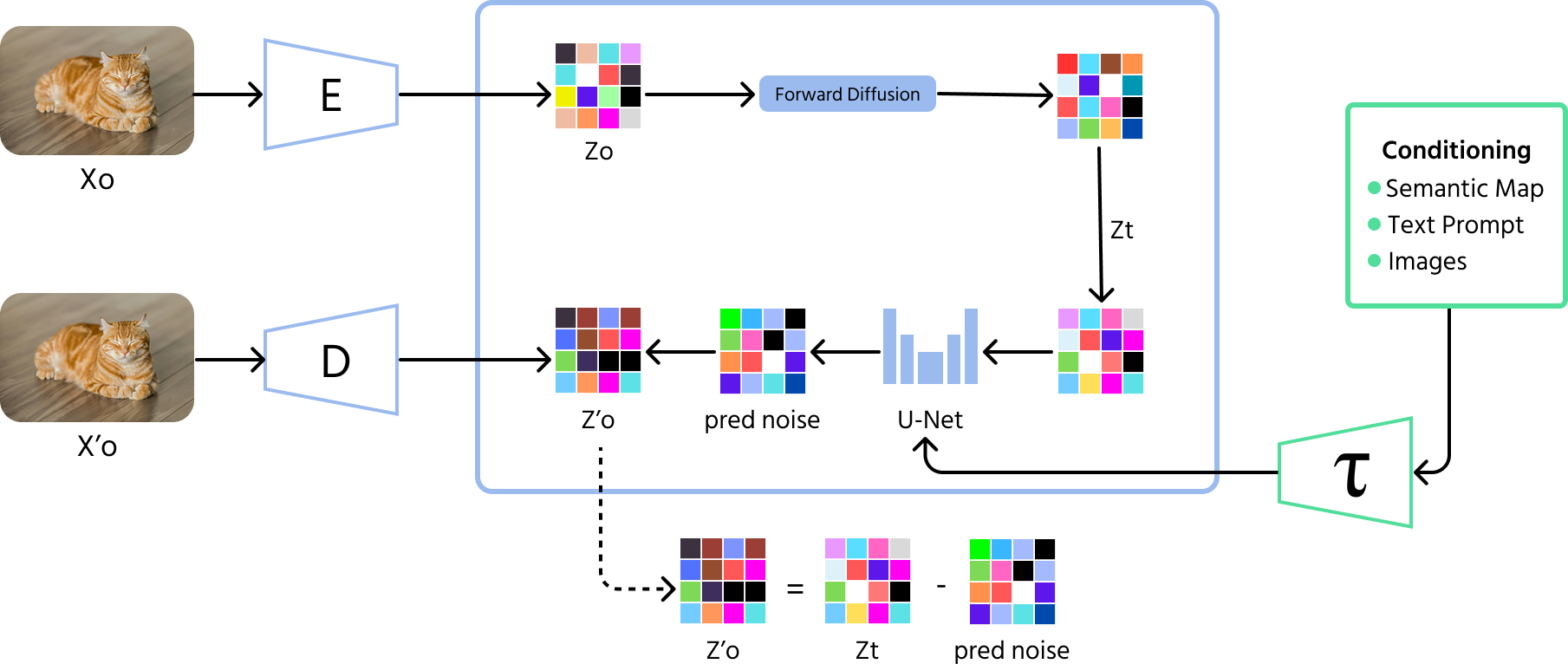
Modelos de difusão representam o mais recente avanço em imagens geradas por IA. Esses modelos começam com ruído aleatório e melhoram gradualmente a imagem passo a passo, como se estivessem removendo estática de uma foto borrada. Diferente dos GANs, que às vezes criam variações limitadas, os modelos de difusão podem produzir uma gama mais ampla de imagens de alta qualidade.
Como Funcionam os Modelos de Difusão
- Processo direto (adição de ruído): o modelo começa adicionando ruído aleatório a uma imagem ao longo de várias etapas até que ela se torne completamente irreconhecível;
- Processo reverso (remoção de ruído): em seguida, o modelo aprende como reverter esse processo, removendo gradualmente o ruído etapa por etapa para recuperar uma imagem significativa;
- Treinamento: os modelos de difusão são treinados para prever e remover o ruído em cada etapa, permitindo gerar imagens nítidas e de alta qualidade a partir de ruído aleatório.
Um exemplo popular é o MidJourney, DALL-E e Stable Diffusion, conhecido por criar imagens realistas e artísticas. Os modelos de difusão são amplamente utilizados para arte gerada por IA, síntese de imagens em alta resolução e aplicações de design criativo.
Exemplos de Imagens Geradas por Modelos de Difusão

Imagem realista de um jogador de basquete com barba, vestindo um uniforme amarelo-violeta, fazendo uma enterrada e derrotando demônios em um jogo de basquete, toda a ação ocorre no inferno.

Uma foto artística surrealista e bela de um Volkswagen Golf GTI branco de 1990 em um campo infinito de flores brancas em harmonia com a natureza, no meio de colinas intermináveis cheias de flores, botânico, luz natural, artístico, neblina, fotorealista surrealista com ultra detalhes, filme kodak, luz natural, lente grande angular, f 1.20

Pintura de cachorro Poodle bege deitado em sofá verde com almofada listrada verde e branca no estilo de Fairfield Porter, expressionismo abstrato, com pinceladas ousadas em fundo bege

Close-up extremo da pele de uma mulher mediterrânea ou latina, destacando um tipo de pele mista com oleosidade visível na testa e no nariz, enquanto as bochechas parecem mais secas e levemente descamadas. Os poros são mais perceptíveis na zona T, e há um brilho natural refletindo a produção de óleo. A pele apresenta uma mistura de tons quentes e dourados, com textura irregular devido a diferentes níveis de hidratação. Iluminação suave e natural enfatiza o contraste realista entre as áreas secas e oleosas. O fundo está desfocado, mantendo a atenção na sua tez.
Desafios e Questões Éticas
Embora as imagens geradas por IA sejam impressionantes, elas apresentam desafios:
- Falta de controle: a IA pode não gerar exatamente o que o usuário deseja;
- Poder computacional: criar imagens de IA de alta qualidade exige computadores potentes e caros;
- Viés em modelos de IA: como a IA aprende a partir de imagens existentes, pode repetir vieses presentes nos dados.
Também existem questões éticas:
- Quem é o dono da arte feita por IA?: se uma IA cria uma obra de arte, a pessoa que usou a IA é a proprietária ou pertence à empresa de IA?
- Imagens falsas e deepfakes: GANs podem ser usados para criar imagens falsas que parecem reais, o que pode gerar desinformação e problemas de privacidade.
Como a Geração de Imagens por IA é Utilizada Hoje
Imagens geradas por IA já causam grande impacto em diferentes setores:
- Entretenimento: videogames, filmes e animações utilizam IA para criar cenários, personagens e efeitos;
- Moda: estilistas usam IA para criar novos estilos de roupas, e lojas online oferecem provadores virtuais para clientes;
- Design gráfico: a IA auxilia artistas e designers a criar rapidamente logotipos, cartazes e materiais de marketing.
O Futuro da Geração de Imagens por IA
À medida que a geração de imagens por IA continua evoluindo, ela seguirá transformando a maneira como as pessoas criam e utilizam imagens. Seja na arte, nos negócios ou no entretenimento, a IA está abrindo novas possibilidades e tornando o trabalho criativo mais fácil e empolgante.
1. Qual é o principal objetivo da geração de imagens por IA?
2. Como funcionam as Redes Geradoras Adversariais (GANs)?
3. Qual modelo de IA começa com ruído aleatório e melhora a imagem passo a passo?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
Visão Geral da Geração de Imagens
Imagens geradas por IA estão transformando a forma como as pessoas criam arte, design e conteúdo digital. Com o auxílio da inteligência artificial, computadores agora podem produzir imagens realistas, aprimorar trabalhos criativos e até mesmo apoiar empresas. Neste capítulo, serão explorados os processos de criação de imagens por IA, os diferentes tipos de modelos de geração de imagens e suas aplicações no mundo real.
Como a IA Cria Imagens
A geração de imagens por IA funciona aprendendo a partir de uma grande coleção de fotos. A IA analisa padrões nas imagens e, em seguida, cria novas imagens semelhantes. Essa tecnologia evoluiu bastante ao longo dos anos, produzindo imagens cada vez mais realistas e criativas. Atualmente, é utilizada em videogames, filmes, publicidade e até mesmo na moda.
Métodos Iniciais: PixelRNN e PixelCNN
Antes dos modelos avançados de IA atuais, pesquisadores desenvolveram métodos iniciais de geração de imagens, como PixelRNN e PixelCNN. Esses modelos criavam imagens prevendo um pixel de cada vez.
- PixelRNN: utiliza um sistema chamado rede neural recorrente (RNN) para prever as cores dos pixels um após o outro. Embora funcionasse bem, era muito lento;
- PixelCNN: aprimorou o PixelRNN ao utilizar um tipo diferente de rede, chamada camadas convolucionais, tornando a criação de imagens mais rápida.
Apesar de terem sido um bom começo, esses modelos não eram eficientes na produção de imagens de alta qualidade. Isso levou ao desenvolvimento de técnicas mais avançadas.
Modelos Autoregressivos
Modelos autoregressivos também criam imagens um pixel de cada vez, utilizando pixels anteriores para prever o próximo. Esses modelos foram úteis, mas lentos, o que fez com que se tornassem menos populares ao longo do tempo. No entanto, eles ajudaram a inspirar modelos mais novos e rápidos.
Como a IA Compreende Texto para Criação de Imagens
Alguns modelos de IA podem transformar palavras escritas em imagens. Esses modelos utilizam Modelos de Linguagem de Grande Escala (LLMs) para entender descrições e gerar imagens correspondentes. Por exemplo, se você digitar “um gato sentado em uma praia ao pôr do sol”, a IA criará uma imagem baseada nessa descrição.
Modelos de IA como o DALL-E da OpenAI e o Imagen do Google utilizam compreensão avançada de linguagem para melhorar a correspondência entre descrições textuais e as imagens geradas. Isso é possível por meio do Processamento de Linguagem Natural (NLP), que ajuda a IA a converter palavras em números que orientam a criação de imagens.
Redes Generativas Adversariais (GANs)
Um dos avanços mais importantes na geração de imagens por IA foi o surgimento das Redes Generativas Adversariais (GANs). As GANs funcionam utilizando duas redes neurais diferentes:
- Gerador: cria novas imagens do zero;
- Discriminador: verifica se as imagens parecem reais ou falsas.
O gerador tenta criar imagens tão realistas que o discriminador não consegue identificar que são falsas. Com o tempo, as imagens melhoram e se assemelham cada vez mais a fotografias reais. As GANs são utilizadas em tecnologia deepfake, criação de obras de arte e aprimoramento da qualidade de imagens.
Autoencoders Variacionais (VAEs)
VAEs são outra abordagem que a IA pode usar para gerar imagens. Em vez de utilizar competição como os GANs, os VAEs codificam e decodificam imagens utilizando probabilidade. Eles funcionam aprendendo os padrões subjacentes de uma imagem e, em seguida, reconstruindo-a com pequenas variações. O elemento probabilístico nos VAEs garante que cada imagem gerada seja ligeiramente diferente, adicionando variedade e criatividade.
Um conceito fundamental em VAEs é a divergência de Kullback-Leibler (KL), que mede a diferença entre a distribuição aprendida e uma distribuição normal padrão. Ao minimizar a divergência KL, os VAEs garantem que as imagens geradas permaneçam realistas, permitindo ao mesmo tempo variações criativas.
Como funcionam os VAEs
- Codificação: os dados de entrada x são enviados para o codificador, que gera os parâmetros da distribuição do espaço latente q(z∣x) (média μ e variância σ²);
- Amostragem do espaço latente: as variáveis latentes z são amostradas da distribuição q(z∣x) utilizando técnicas como o truque de reparametrização;
- Decodificação e reconstrução: o z amostrado é passado pelo decodificador para produzir os dados reconstruídos x̂, que devem ser semelhantes à entrada original x.
VAEs são úteis para tarefas como reconstrução de rostos, geração de novas versões de imagens existentes e até mesmo para criar transições suaves entre diferentes imagens.
Modelos de Difusão
Modelos de difusão representam o mais recente avanço em imagens geradas por IA. Esses modelos começam com ruído aleatório e melhoram gradualmente a imagem passo a passo, como se estivessem removendo estática de uma foto borrada. Diferente dos GANs, que às vezes criam variações limitadas, os modelos de difusão podem produzir uma gama mais ampla de imagens de alta qualidade.
Como Funcionam os Modelos de Difusão
- Processo direto (adição de ruído): o modelo começa adicionando ruído aleatório a uma imagem ao longo de várias etapas até que ela se torne completamente irreconhecível;
- Processo reverso (remoção de ruído): em seguida, o modelo aprende como reverter esse processo, removendo gradualmente o ruído etapa por etapa para recuperar uma imagem significativa;
- Treinamento: os modelos de difusão são treinados para prever e remover o ruído em cada etapa, permitindo gerar imagens nítidas e de alta qualidade a partir de ruído aleatório.
Um exemplo popular é o MidJourney, DALL-E e Stable Diffusion, conhecido por criar imagens realistas e artísticas. Os modelos de difusão são amplamente utilizados para arte gerada por IA, síntese de imagens em alta resolução e aplicações de design criativo.
Exemplos de Imagens Geradas por Modelos de Difusão
Imagem realista de um jogador de basquete com barba, vestindo um uniforme amarelo-violeta, fazendo uma enterrada e derrotando demônios em um jogo de basquete, toda a ação ocorre no inferno.
Uma foto artística surrealista e bela de um Volkswagen Golf GTI branco de 1990 em um campo infinito de flores brancas em harmonia com a natureza, no meio de colinas intermináveis cheias de flores, botânico, luz natural, artístico, neblina, fotorealista surrealista com ultra detalhes, filme kodak, luz natural, lente grande angular, f 1.20
Pintura de cachorro Poodle bege deitado em sofá verde com almofada listrada verde e branca no estilo de Fairfield Porter, expressionismo abstrato, com pinceladas ousadas em fundo bege
Close-up extremo da pele de uma mulher mediterrânea ou latina, destacando um tipo de pele mista com oleosidade visível na testa e no nariz, enquanto as bochechas parecem mais secas e levemente descamadas. Os poros são mais perceptíveis na zona T, e há um brilho natural refletindo a produção de óleo. A pele apresenta uma mistura de tons quentes e dourados, com textura irregular devido a diferentes níveis de hidratação. Iluminação suave e natural enfatiza o contraste realista entre as áreas secas e oleosas. O fundo está desfocado, mantendo a atenção na sua tez.
Desafios e Questões Éticas
Embora as imagens geradas por IA sejam impressionantes, elas apresentam desafios:
- Falta de controle: a IA pode não gerar exatamente o que o usuário deseja;
- Poder computacional: criar imagens de IA de alta qualidade exige computadores potentes e caros;
- Viés em modelos de IA: como a IA aprende a partir de imagens existentes, pode repetir vieses presentes nos dados.
Também existem questões éticas:
- Quem é o dono da arte feita por IA?: se uma IA cria uma obra de arte, a pessoa que usou a IA é a proprietária ou pertence à empresa de IA?
- Imagens falsas e deepfakes: GANs podem ser usados para criar imagens falsas que parecem reais, o que pode gerar desinformação e problemas de privacidade.
Como a Geração de Imagens por IA é Utilizada Hoje
Imagens geradas por IA já causam grande impacto em diferentes setores:
- Entretenimento: videogames, filmes e animações utilizam IA para criar cenários, personagens e efeitos;
- Moda: estilistas usam IA para criar novos estilos de roupas, e lojas online oferecem provadores virtuais para clientes;
- Design gráfico: a IA auxilia artistas e designers a criar rapidamente logotipos, cartazes e materiais de marketing.
O Futuro da Geração de Imagens por IA
À medida que a geração de imagens por IA continua evoluindo, ela seguirá transformando a maneira como as pessoas criam e utilizam imagens. Seja na arte, nos negócios ou no entretenimento, a IA está abrindo novas possibilidades e tornando o trabalho criativo mais fácil e empolgante.
Obrigado pelo seu feedback!
