Aprendizado por Transferência em Visão Computacional
Deslize para mostrar o menu
Aprendizado por transferência permite reutilizar modelos treinados em grandes conjuntos de dados para novas tarefas com dados limitados. Em vez de construir uma rede neural do zero, utilizamos modelos pré-treinados para melhorar a eficiência e o desempenho. Ao longo deste curso, abordamos abordagens semelhantes em seções anteriores, que serviram de base para a aplicação eficaz do aprendizado por transferência.
O que é Aprendizado por Transferência?
Aprendizado por transferência é uma técnica em que um modelo treinado em uma tarefa é adaptado para outra tarefa relacionada. Em visão computacional, modelos pré-treinados em grandes conjuntos de dados como o ImageNet podem ser ajustados para aplicações específicas, como imagem médica ou condução autônoma.
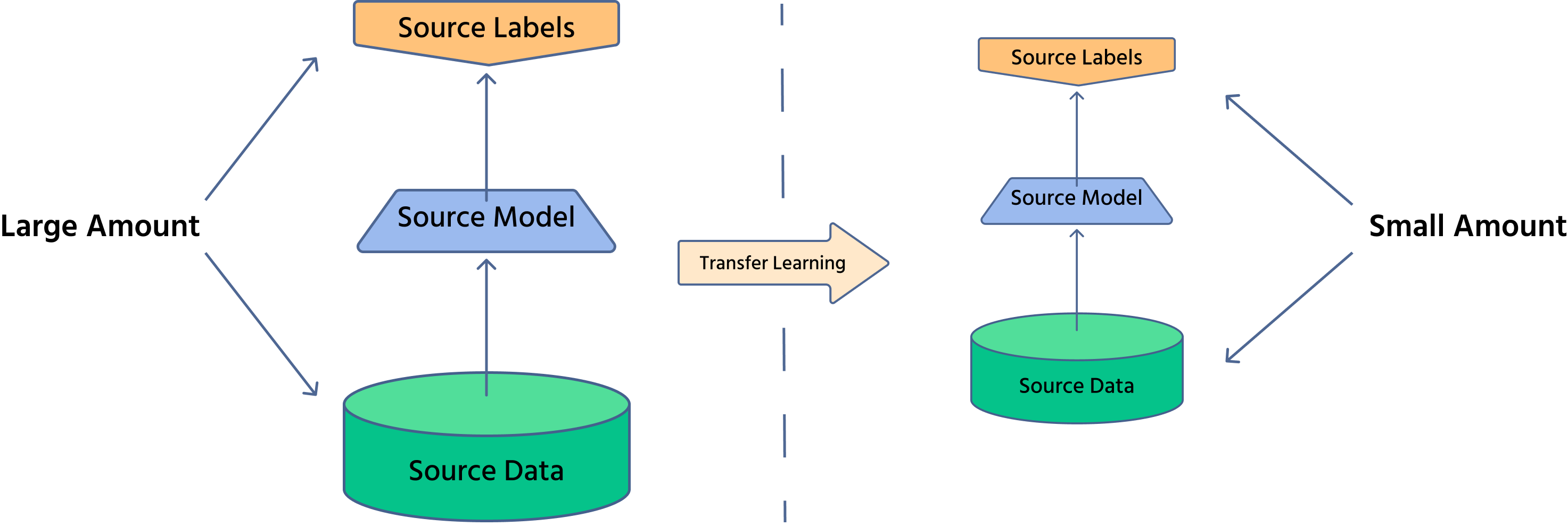
Por que o Aprendizado por Transferência é Importante?
- Redução do tempo de treinamento: como o modelo já aprendeu características gerais, apenas pequenos ajustes são necessários;
- Necessidade de menos dados: útil em situações onde a obtenção de dados rotulados é cara;
- Aumento de desempenho: modelos pré-treinados oferecem extração robusta de características, melhorando a precisão.
Fluxo de Trabalho do Aprendizado por Transferência
O fluxo de trabalho típico do aprendizado por transferência envolve várias etapas principais:
-
Seleção de um Modelo Pré-Treinado:
- Escolha de um modelo treinado em um grande conjunto de dados (por exemplo, ResNet, VGG, YOLO);
- Esses modelos já aprenderam representações úteis que podem ser adaptadas para novas tarefas.
-
Modificação do Modelo Pré-Treinado:
- Extração de características: congelamento das camadas iniciais e re-treinamento apenas das camadas finais para a nova tarefa;
- Ajuste fino: descongelamento de algumas ou todas as camadas e re-treinamento no novo conjunto de dados.
-
Treinamento no Novo Conjunto de Dados:
- Treinamento do modelo modificado utilizando um conjunto de dados menor e específico para a tarefa alvo;
- Otimização utilizando técnicas como backpropagation e funções de perda.
-
Avaliação e Iteração:
- Avaliação do desempenho utilizando métricas como acurácia, precisão, revocação e mAP;
- Ajuste fino adicional, se necessário, para melhorar os resultados.
Modelos Pré-Treinados Populares
Alguns dos modelos pré-treinados mais utilizados em visão computacional incluem:
- ResNet: redes residuais profundas que permitem o treinamento de arquiteturas muito profundas;
- VGG: arquitetura simples com camadas convolucionais uniformes;
- EfficientNet: otimizado para alta precisão com menos parâmetros;
- YOLO: detecção de objetos em tempo real de última geração (SOTA).
Ajuste Fino vs. Extração de Características
Extração de características consiste em utilizar as camadas de um modelo pré-treinado como extratores de características fixos. Nesta abordagem, a camada final de classificação do modelo original é normalmente removida e substituída por uma nova, específica para a tarefa de destino. As camadas pré-treinadas permanecem congeladas, ou seja, seus pesos não são atualizados durante o treinamento, o que acelera o processo e exige menos dados.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ajuste fino, por outro lado, vai além ao descongelar algumas ou todas as camadas pré-treinadas e retreiná-las no novo conjunto de dados. Isso permite que o modelo adapte as características aprendidas de forma mais específica às particularidades da nova tarefa, frequentemente resultando em melhor desempenho—especialmente quando o novo conjunto de dados é suficientemente grande ou difere significativamente dos dados de treinamento originais.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Aplicações de Transferência de Aprendizagem
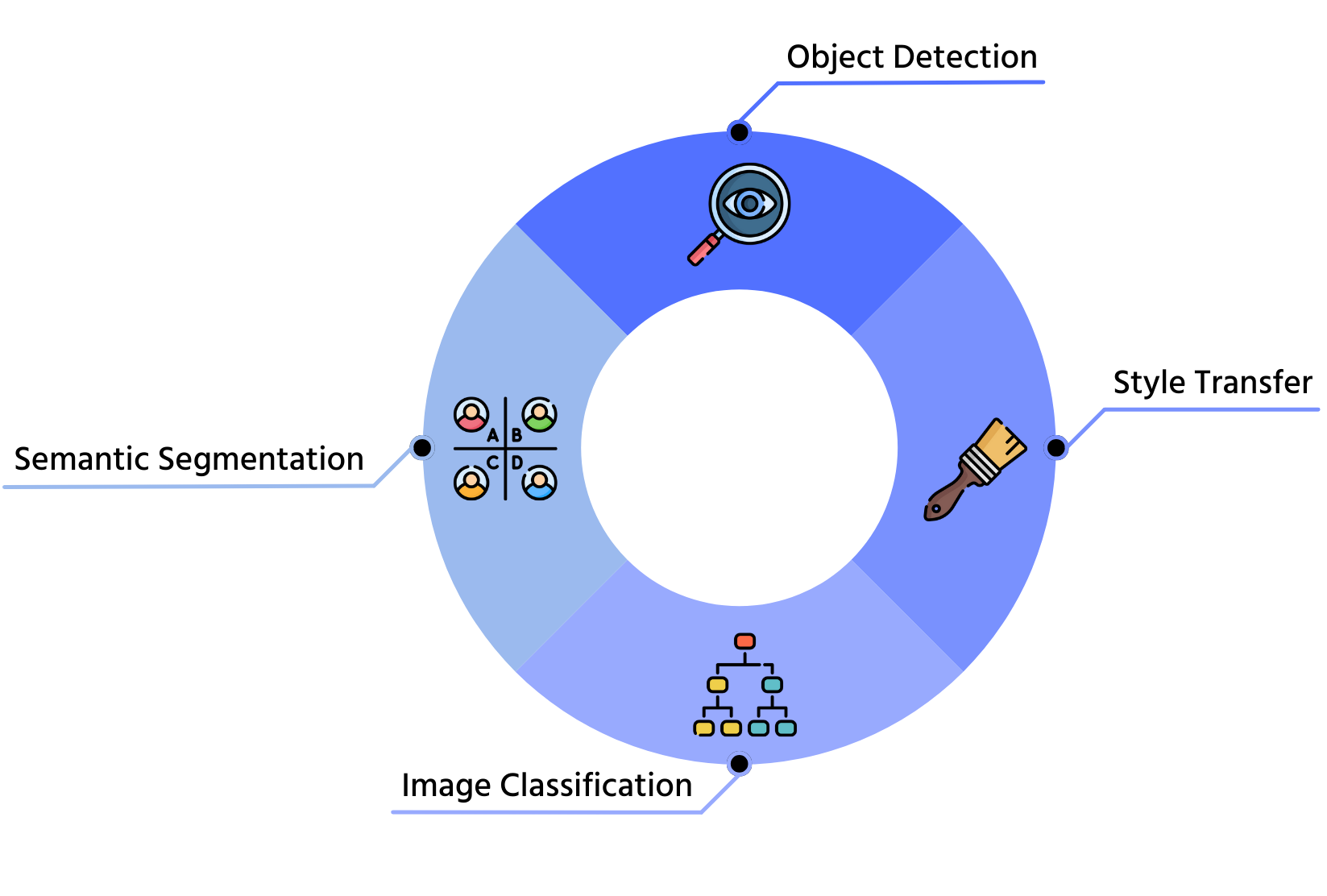
1. Classificação de Imagens
Classificação de imagens consiste em atribuir rótulos às imagens com base em seu conteúdo visual. Modelos pré-treinados como ResNet e EfficientNet podem ser adaptados para tarefas específicas, como imagem médica ou classificação de vida selvagem.
Exemplo:
- Selecionar um modelo pré-treinado (por exemplo, ResNet);
- Modificar a camada de classificação para corresponder às classes alvo;
- Realizar ajuste fino com uma taxa de aprendizado menor.
2. Detecção de Objetos
Detecção de objetos envolve tanto identificar objetos quanto localizá-los dentro de uma imagem. O aprendizado por transferência permite que modelos como Faster R-CNN, SSD e YOLO detectem objetos específicos em novos conjuntos de dados de forma eficiente.
Exemplo:
- Utilizar um modelo pré-treinado de detecção de objetos (por exemplo, YOLOv8);
- Realizar ajuste fino em um conjunto de dados personalizado com novas classes de objetos;
- Avaliar o desempenho e otimizar conforme necessário.
3. Segmentação Semântica
Segmentação semântica classifica cada pixel de uma imagem em categorias predefinidas. Modelos como U-Net e DeepLab são amplamente utilizados em aplicações como condução autônoma e imagem médica.
Exemplo:
- Utilizar um modelo pré-treinado de segmentação (por exemplo, U-Net);
- Treinar em um conjunto de dados específico do domínio;
- Ajustar hiperparâmetros para melhor precisão.
4. Transferência de Estilo
Transferência de estilo aplica o estilo visual de uma imagem em outra, preservando seu conteúdo original. Essa técnica é comumente utilizada em arte digital e realce de imagens, aproveitando modelos pré-treinados como VGG.
Exemplo:
- Selecionar um modelo de transferência de estilo (por exemplo, VGG);
- Inserir imagens de conteúdo e de estilo;
- Otimizar para obter resultados visualmente atraentes.
1. Qual é a principal vantagem de utilizar o aprendizado por transferência em visão computacional?
2. Qual abordagem é utilizada em aprendizado por transferência quando apenas a última camada de um modelo pré-treinado é modificada, mantendo as camadas anteriores fixas?
3. Qual dos seguintes modelos é comumente utilizado para aprendizado por transferência em detecção de objetos?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
Aprendizado por Transferência em Visão Computacional
Aprendizado por transferência permite reutilizar modelos treinados em grandes conjuntos de dados para novas tarefas com dados limitados. Em vez de construir uma rede neural do zero, utilizamos modelos pré-treinados para melhorar a eficiência e o desempenho. Ao longo deste curso, abordamos abordagens semelhantes em seções anteriores, que serviram de base para a aplicação eficaz do aprendizado por transferência.
O que é Aprendizado por Transferência?
Aprendizado por transferência é uma técnica em que um modelo treinado em uma tarefa é adaptado para outra tarefa relacionada. Em visão computacional, modelos pré-treinados em grandes conjuntos de dados como o ImageNet podem ser ajustados para aplicações específicas, como imagem médica ou condução autônoma.
Por que o Aprendizado por Transferência é Importante?
- Redução do tempo de treinamento: como o modelo já aprendeu características gerais, apenas pequenos ajustes são necessários;
- Necessidade de menos dados: útil em situações onde a obtenção de dados rotulados é cara;
- Aumento de desempenho: modelos pré-treinados oferecem extração robusta de características, melhorando a precisão.
Fluxo de Trabalho do Aprendizado por Transferência
O fluxo de trabalho típico do aprendizado por transferência envolve várias etapas principais:
-
Seleção de um Modelo Pré-Treinado:
- Escolha de um modelo treinado em um grande conjunto de dados (por exemplo, ResNet, VGG, YOLO);
- Esses modelos já aprenderam representações úteis que podem ser adaptadas para novas tarefas.
-
Modificação do Modelo Pré-Treinado:
- Extração de características: congelamento das camadas iniciais e re-treinamento apenas das camadas finais para a nova tarefa;
- Ajuste fino: descongelamento de algumas ou todas as camadas e re-treinamento no novo conjunto de dados.
-
Treinamento no Novo Conjunto de Dados:
- Treinamento do modelo modificado utilizando um conjunto de dados menor e específico para a tarefa alvo;
- Otimização utilizando técnicas como backpropagation e funções de perda.
-
Avaliação e Iteração:
- Avaliação do desempenho utilizando métricas como acurácia, precisão, revocação e mAP;
- Ajuste fino adicional, se necessário, para melhorar os resultados.
Modelos Pré-Treinados Populares
Alguns dos modelos pré-treinados mais utilizados em visão computacional incluem:
- ResNet: redes residuais profundas que permitem o treinamento de arquiteturas muito profundas;
- VGG: arquitetura simples com camadas convolucionais uniformes;
- EfficientNet: otimizado para alta precisão com menos parâmetros;
- YOLO: detecção de objetos em tempo real de última geração (SOTA).
Ajuste Fino vs. Extração de Características
Extração de características consiste em utilizar as camadas de um modelo pré-treinado como extratores de características fixos. Nesta abordagem, a camada final de classificação do modelo original é normalmente removida e substituída por uma nova, específica para a tarefa de destino. As camadas pré-treinadas permanecem congeladas, ou seja, seus pesos não são atualizados durante o treinamento, o que acelera o processo e exige menos dados.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ajuste fino, por outro lado, vai além ao descongelar algumas ou todas as camadas pré-treinadas e retreiná-las no novo conjunto de dados. Isso permite que o modelo adapte as características aprendidas de forma mais específica às particularidades da nova tarefa, frequentemente resultando em melhor desempenho—especialmente quando o novo conjunto de dados é suficientemente grande ou difere significativamente dos dados de treinamento originais.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Aplicações de Transferência de Aprendizagem
1. Classificação de Imagens
Classificação de imagens consiste em atribuir rótulos às imagens com base em seu conteúdo visual. Modelos pré-treinados como ResNet e EfficientNet podem ser adaptados para tarefas específicas, como imagem médica ou classificação de vida selvagem.
Exemplo:
- Selecionar um modelo pré-treinado (por exemplo, ResNet);
- Modificar a camada de classificação para corresponder às classes alvo;
- Realizar ajuste fino com uma taxa de aprendizado menor.
2. Detecção de Objetos
Detecção de objetos envolve tanto identificar objetos quanto localizá-los dentro de uma imagem. O aprendizado por transferência permite que modelos como Faster R-CNN, SSD e YOLO detectem objetos específicos em novos conjuntos de dados de forma eficiente.
Exemplo:
- Utilizar um modelo pré-treinado de detecção de objetos (por exemplo, YOLOv8);
- Realizar ajuste fino em um conjunto de dados personalizado com novas classes de objetos;
- Avaliar o desempenho e otimizar conforme necessário.
3. Segmentação Semântica
Segmentação semântica classifica cada pixel de uma imagem em categorias predefinidas. Modelos como U-Net e DeepLab são amplamente utilizados em aplicações como condução autônoma e imagem médica.
Exemplo:
- Utilizar um modelo pré-treinado de segmentação (por exemplo, U-Net);
- Treinar em um conjunto de dados específico do domínio;
- Ajustar hiperparâmetros para melhor precisão.
4. Transferência de Estilo
Transferência de estilo aplica o estilo visual de uma imagem em outra, preservando seu conteúdo original. Essa técnica é comumente utilizada em arte digital e realce de imagens, aproveitando modelos pré-treinados como VGG.
Exemplo:
- Selecionar um modelo de transferência de estilo (por exemplo, VGG);
- Inserir imagens de conteúdo e de estilo;
- Otimizar para obter resultados visualmente atraentes.
Obrigado pelo seu feedback!
