Caixas Âncora
Deslize para mostrar o menu
Anchor box é uma caixa delimitadora predefinida com tamanho e proporção fixos, posicionada em locais específicos de uma imagem.
Por Que Anchor Boxes São Usadas em Detecção de Objetos
Anchor boxes são um conceito fundamental em modelos modernos de detecção de objetos, como Faster R-CNN e YOLO. Elas servem como caixas de referência predefinidas que auxiliam na detecção de objetos de diferentes tamanhos e proporções, tornando a detecção mais rápida e confiável.
Em vez de detectar objetos do zero, os modelos utilizam anchor boxes como pontos de partida, ajustando-as para se adequar melhor aos objetos detectados. Essa abordagem melhora a eficiência e a precisão, especialmente para detectar objetos em diferentes escalas.
Diferença Entre Anchor Box e Bounding Box
- Anchor Box: um modelo predefinido que atua como referência durante a detecção de objetos;
- Bounding Box: a caixa final prevista após os ajustes feitos em uma anchor box para corresponder ao objeto real.

Ao contrário das caixas delimitadoras, que são ajustadas dinamicamente durante a previsão, as anchor boxes são fixadas em posições específicas antes de qualquer detecção de objeto. Os modelos aprendem a refinar as anchor boxes ajustando seu tamanho, posição e proporção, transformando-as em caixas delimitadoras finais que representam com precisão os objetos detectados.
Como uma Rede Gera Anchor Boxes
As anchor boxes não são aplicadas diretamente à imagem, mas sim aos mapas de características extraídos da imagem. Após a extração de características, um conjunto de anchor boxes é posicionado nesses mapas de características, variando em tamanho e proporção. A escolha dos formatos das anchor boxes é fundamental e envolve um equilíbrio entre a detecção de objetos pequenos e grandes.
Para definir os tamanhos das anchor boxes, os modelos normalmente utilizam uma combinação de seleção manual e algoritmos de agrupamento como K-Means para analisar o conjunto de dados e determinar os formatos e tamanhos de objetos mais comuns. Essas anchor boxes predefinidas são então aplicadas em diferentes locais dos mapas de características. Por exemplo, um modelo de detecção de objetos pode usar anchor boxes de tamanhos (16x16), (32x32), (64x64), com proporções como 1:1, 1:2, and 2:1.
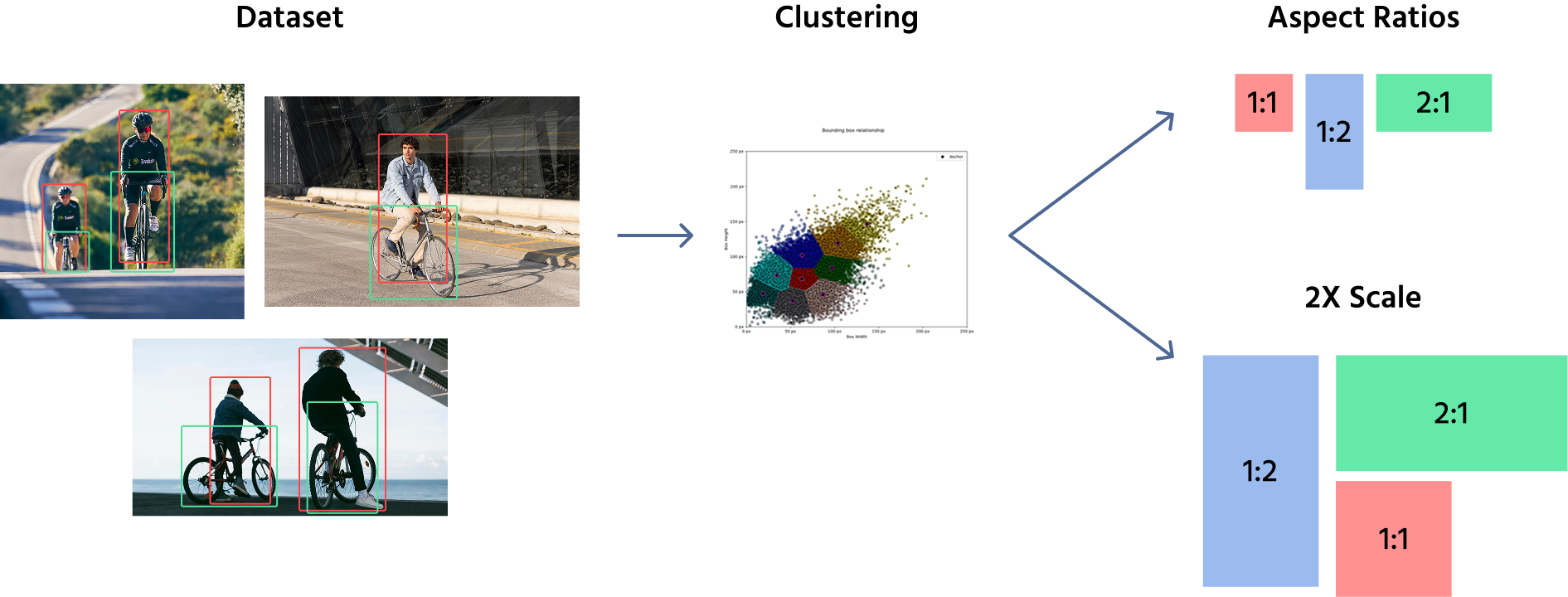
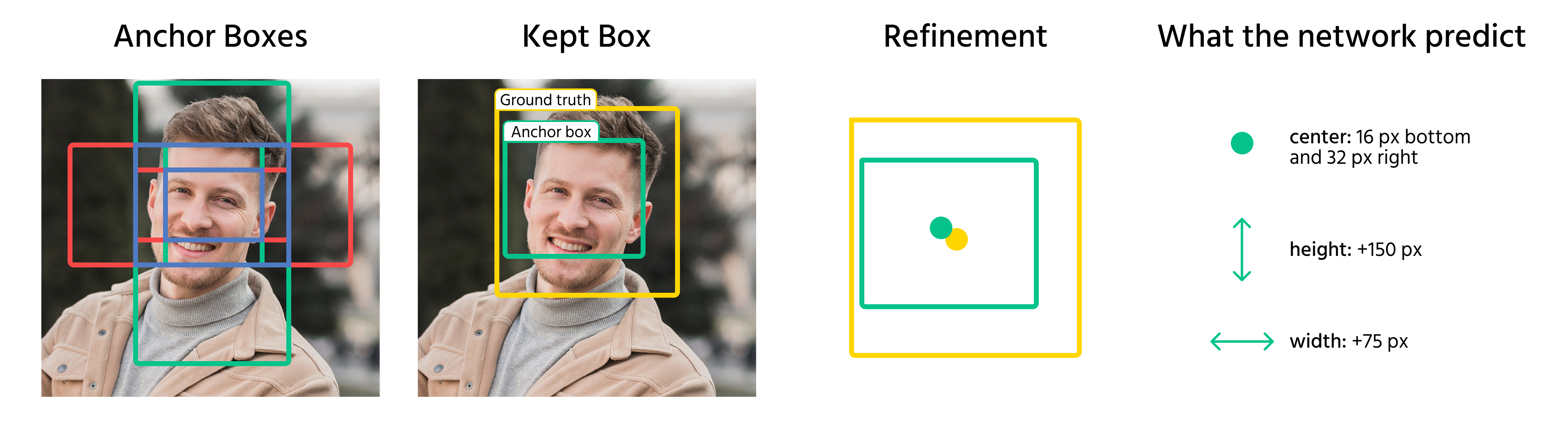
Depois que essas anchor boxes são definidas, elas são aplicadas aos feature maps, e não à imagem original. O modelo atribui múltiplas anchor boxes a cada local do feature map, cobrindo diferentes formas e tamanhos. Durante o treinamento, a rede ajusta as anchor boxes prevendo deslocamentos, refinando seu tamanho e posição para melhor se adequar aos objetos.
De Anchor Box para Bounding Box
Depois que as anchor boxes são atribuídas aos objetos, o modelo prevê deslocamentos para refiná-las. Esses deslocamentos incluem:
- Ajuste das coordenadas do centro da caixa;
- Escalonamento da largura e altura;
- Deslocamento da caixa para melhor alinhamento com o objeto.
Ao aplicar essas transformações, o modelo converte as anchor boxes em bounding boxes finais que correspondem de forma mais precisa aos objetos em uma imagem.
Abordagens Que Não Utilizam Anchors ou Reduzem Seu Número
Embora as anchor boxes sejam amplamente utilizadas, alguns modelos buscam reduzir a dependência delas ou eliminá-las completamente:
- Métodos anchor-free: modelos como
CenterNeteFCOSpredizem diretamente as localizações dos objetos sem anchors predefinidos, reduzindo a complexidade; - Abordagens com menos anchors:
EfficientDeteYOLOv4otimizam a quantidade de anchor boxes utilizadas, equilibrando velocidade de detecção e precisão.
Essas abordagens visam melhorar a eficiência da detecção de objetos mantendo alto desempenho, especialmente para aplicações em tempo real.
Em resumo, as anchor boxes são parte fundamental da detecção de objetos, auxiliando os modelos a detectar objetos de forma eficiente em diferentes tamanhos e proporções. No entanto, novos avanços estão explorando maneiras de reduzir ou eliminar as anchor boxes para uma detecção ainda mais rápida e flexível.
1. Qual é o papel principal das anchor boxes na detecção de objetos?
2. Como as anchor boxes diferem das bounding boxes?
3. Qual método é comumente utilizado para determinar os tamanhos ideais das anchor boxes?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
Caixas Âncora
Anchor box é uma caixa delimitadora predefinida com tamanho e proporção fixos, posicionada em locais específicos de uma imagem.
Por Que Anchor Boxes São Usadas em Detecção de Objetos
Anchor boxes são um conceito fundamental em modelos modernos de detecção de objetos, como Faster R-CNN e YOLO. Elas servem como caixas de referência predefinidas que auxiliam na detecção de objetos de diferentes tamanhos e proporções, tornando a detecção mais rápida e confiável.
Em vez de detectar objetos do zero, os modelos utilizam anchor boxes como pontos de partida, ajustando-as para se adequar melhor aos objetos detectados. Essa abordagem melhora a eficiência e a precisão, especialmente para detectar objetos em diferentes escalas.
Diferença Entre Anchor Box e Bounding Box
- Anchor Box: um modelo predefinido que atua como referência durante a detecção de objetos;
- Bounding Box: a caixa final prevista após os ajustes feitos em uma anchor box para corresponder ao objeto real.
Ao contrário das caixas delimitadoras, que são ajustadas dinamicamente durante a previsão, as anchor boxes são fixadas em posições específicas antes de qualquer detecção de objeto. Os modelos aprendem a refinar as anchor boxes ajustando seu tamanho, posição e proporção, transformando-as em caixas delimitadoras finais que representam com precisão os objetos detectados.
Como uma Rede Gera Anchor Boxes
As anchor boxes não são aplicadas diretamente à imagem, mas sim aos mapas de características extraídos da imagem. Após a extração de características, um conjunto de anchor boxes é posicionado nesses mapas de características, variando em tamanho e proporção. A escolha dos formatos das anchor boxes é fundamental e envolve um equilíbrio entre a detecção de objetos pequenos e grandes.
Para definir os tamanhos das anchor boxes, os modelos normalmente utilizam uma combinação de seleção manual e algoritmos de agrupamento como K-Means para analisar o conjunto de dados e determinar os formatos e tamanhos de objetos mais comuns. Essas anchor boxes predefinidas são então aplicadas em diferentes locais dos mapas de características. Por exemplo, um modelo de detecção de objetos pode usar anchor boxes de tamanhos (16x16), (32x32), (64x64), com proporções como 1:1, 1:2, and 2:1.
Depois que essas anchor boxes são definidas, elas são aplicadas aos feature maps, e não à imagem original. O modelo atribui múltiplas anchor boxes a cada local do feature map, cobrindo diferentes formas e tamanhos. Durante o treinamento, a rede ajusta as anchor boxes prevendo deslocamentos, refinando seu tamanho e posição para melhor se adequar aos objetos.
De Anchor Box para Bounding Box
Depois que as anchor boxes são atribuídas aos objetos, o modelo prevê deslocamentos para refiná-las. Esses deslocamentos incluem:
- Ajuste das coordenadas do centro da caixa;
- Escalonamento da largura e altura;
- Deslocamento da caixa para melhor alinhamento com o objeto.
Ao aplicar essas transformações, o modelo converte as anchor boxes em bounding boxes finais que correspondem de forma mais precisa aos objetos em uma imagem.
Abordagens Que Não Utilizam Anchors ou Reduzem Seu Número
Embora as anchor boxes sejam amplamente utilizadas, alguns modelos buscam reduzir a dependência delas ou eliminá-las completamente:
- Métodos anchor-free: modelos como
CenterNeteFCOSpredizem diretamente as localizações dos objetos sem anchors predefinidos, reduzindo a complexidade; - Abordagens com menos anchors:
EfficientDeteYOLOv4otimizam a quantidade de anchor boxes utilizadas, equilibrando velocidade de detecção e precisão.
Essas abordagens visam melhorar a eficiência da detecção de objetos mantendo alto desempenho, especialmente para aplicações em tempo real.
Em resumo, as anchor boxes são parte fundamental da detecção de objetos, auxiliando os modelos a detectar objetos de forma eficiente em diferentes tamanhos e proporções. No entanto, novos avanços estão explorando maneiras de reduzir ou eliminar as anchor boxes para uma detecção ainda mais rápida e flexível.
Obrigado pelo seu feedback!
