Visão Geral do Modelo YOLO
Deslize para mostrar o menu
O algoritmo YOLO (You Only Look Once) é um modelo de detecção de objetos rápido e eficiente. Diferente de abordagens tradicionais como o R-CNN, que utilizam múltiplas etapas, o YOLO processa a imagem inteira em uma única passagem, tornando-o ideal para aplicações em tempo real.
Como o YOLO Difere das Abordagens R-CNN
Métodos tradicionais de detecção de objetos, como o R-CNN e suas variantes, utilizam um pipeline de duas etapas: primeiro gerando propostas de regiões, depois classificando cada região proposta. Embora eficaz, essa abordagem é computacionalmente custosa e reduz a velocidade de inferência, tornando-a menos adequada para aplicações em tempo real.
YOLO (You Only Look Once) adota uma abordagem radicalmente diferente. Ele divide a imagem de entrada em uma grade e prevê caixas delimitadoras e probabilidades de classe para cada célula em uma única passagem direta. Esse design trata a detecção de objetos como um único problema de regressão, permitindo que o YOLO alcance desempenho em tempo real.
Diferente dos métodos baseados em R-CNN, que focam apenas em regiões locais, o YOLO processa a imagem inteira de uma vez, possibilitando capturar informações contextuais globais. Isso resulta em melhor desempenho na detecção de múltiplos objetos ou objetos sobrepostos, mantendo alta velocidade e precisão.
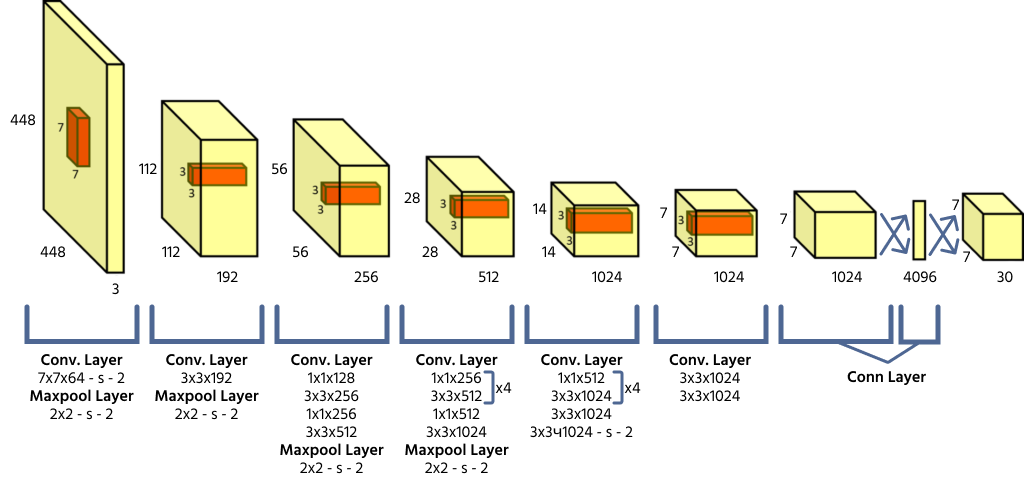
Arquitetura do YOLO e Previsões Baseadas em Grade
YOLO divide uma imagem de entrada em uma grade S × S, onde cada célula da grade é responsável por detectar objetos cujo centro está dentro dela. Cada célula prevê as coordenadas da caixa delimitadora (x, y, largura, altura), uma pontuação de confiança do objeto e probabilidades de classe. Como o YOLO processa a imagem inteira em uma única passagem, ele é altamente eficiente em comparação com modelos anteriores de detecção de objetos.
Função de Perda e Pontuações de Confiança de Classe
YOLO otimiza a precisão da detecção utilizando uma função de perda personalizada, que inclui:
- Perda de localização: mede a precisão da caixa delimitadora;
- Perda de confiança: garante que as previsões indiquem corretamente a presença de objetos;
- Perda de classificação: avalia o quão bem a classe prevista corresponde à classe real.
Para melhorar os resultados, o YOLO aplica anchor boxes e supressão não máxima (NMS) para remover detecções redundantes.
Vantagens do YOLO: Equilíbrio entre Velocidade e Precisão
A principal vantagem do YOLO é a velocidade. Como a detecção ocorre em uma única passagem, o YOLO é muito mais rápido do que métodos baseados em R-CNN, tornando-o adequado para aplicações em tempo real, como condução autônoma e vigilância. No entanto, as primeiras versões do YOLO apresentavam dificuldades na detecção de objetos pequenos, o que foi aprimorado em versões posteriores.
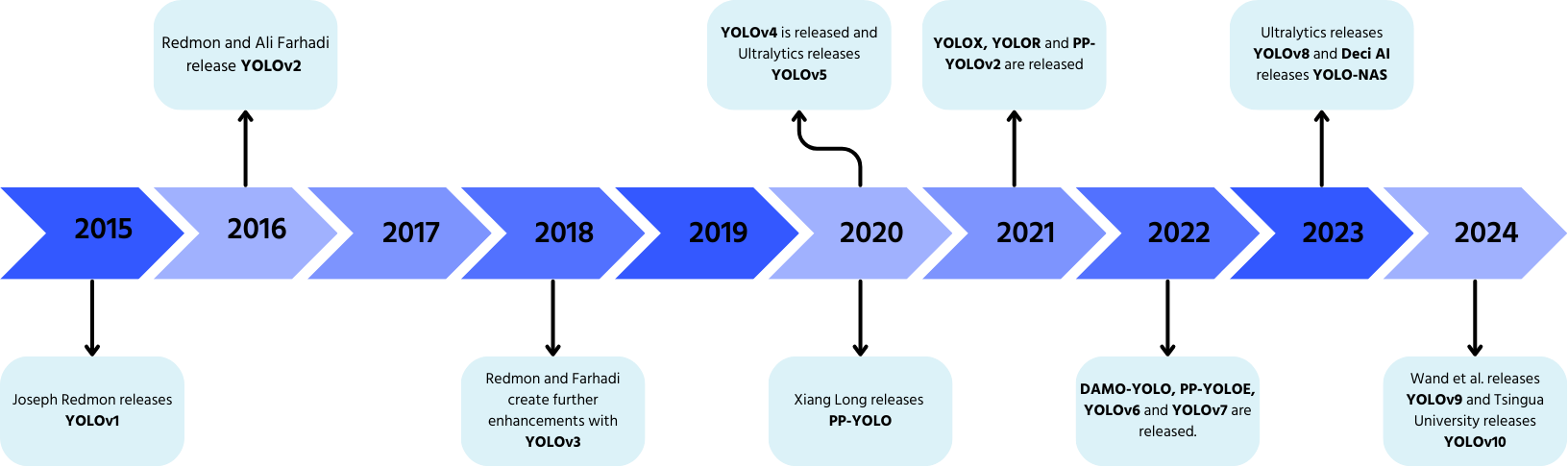
YOLO: Um Breve Histórico
YOLO, desenvolvido por Joseph Redmon e Ali Farhadi em 2015, revolucionou a detecção de objetos com seu processamento em passagem única.
- YOLOv2 (2016): adicionou normalização em lote, caixas âncora e agrupamento de dimensões;
- YOLOv3 (2018): introduziu um backbone mais eficiente, múltiplas âncoras e pooling piramidal espacial;
- YOLOv4 (2020): incorporou aumento de dados Mosaic, uma cabeça de detecção sem âncora e uma nova função de perda;
- YOLOv5: aprimorou o desempenho com otimização de hiperparâmetros, rastreamento de experimentos e recursos automáticos de exportação;
- YOLOv6 (2022): código aberto pela Meituan e utilizado em robôs autônomos de entrega;
- YOLOv7: expandiu as capacidades para incluir estimativa de pose;
- YOLOv8 (2023): melhorou velocidade, flexibilidade e eficiência para tarefas de IA em visão computacional;
- YOLOv9: introduziu Programmable Gradient Information (PGI) e Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: desenvolvido pela Universidade de Tsinghua, eliminando Non-Maximum Suppression (NMS) com uma cabeça de detecção End-to-End;
- YOLOv11: o modelo mais recente, oferecendo desempenho de ponta em detecção de objetos, segmentação e classificação.
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
