Previsões de Caixas Delimitadoras
Deslize para mostrar o menu
Caixas delimitadoras são essenciais para a detecção de objetos, fornecendo uma maneira de marcar as localizações dos objetos. Modelos de detecção de objetos utilizam essas caixas para definir a posição e as dimensões dos objetos detectados dentro de uma imagem. Prever caixas delimitadoras com precisão é fundamental para garantir uma detecção de objetos confiável.
Como as CNNs Predizem as Coordenadas das Caixas Delimitadoras
Redes Neurais Convolucionais (CNNs) processam imagens por meio de camadas de convolução e pooling para extrair características. Para detecção de objetos, as CNNs geram mapas de características que representam diferentes partes de uma imagem. A previsão das caixas delimitadoras é normalmente realizada por:
- Extração de representações de características da imagem;
- Aplicação de uma função de regressão para prever as coordenadas das caixas delimitadoras;
- Classificação dos objetos detectados em cada caixa.
As previsões das caixas delimitadoras são representadas como valores numéricos correspondentes a:
- (x, y): as coordenadas do centro da caixa;
- (w, h): a largura e a altura da caixa.
Exemplo: Previsão de Caixas Delimitadoras Utilizando um Modelo Pré-treinado
Em vez de treinar uma CNN do zero, é possível utilizar um modelo pré-treinado como o Faster R-CNN do TensorFlow's model zoo para prever caixas delimitadoras em uma imagem. Abaixo está um exemplo de como carregar um modelo pré-treinado, carregar uma imagem, realizar previsões e visualizar as caixas delimitadoras com os rótulos das classes.
Importar bibliotecas
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Carregar modelo e imagem
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Pré-processar a imagem
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Realizar predição e extrair características da caixa delimitadora
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Desenhar caixas delimitadoras
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualizar
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultado:

Previsões de Caixa Delimitadora Baseadas em Regressão
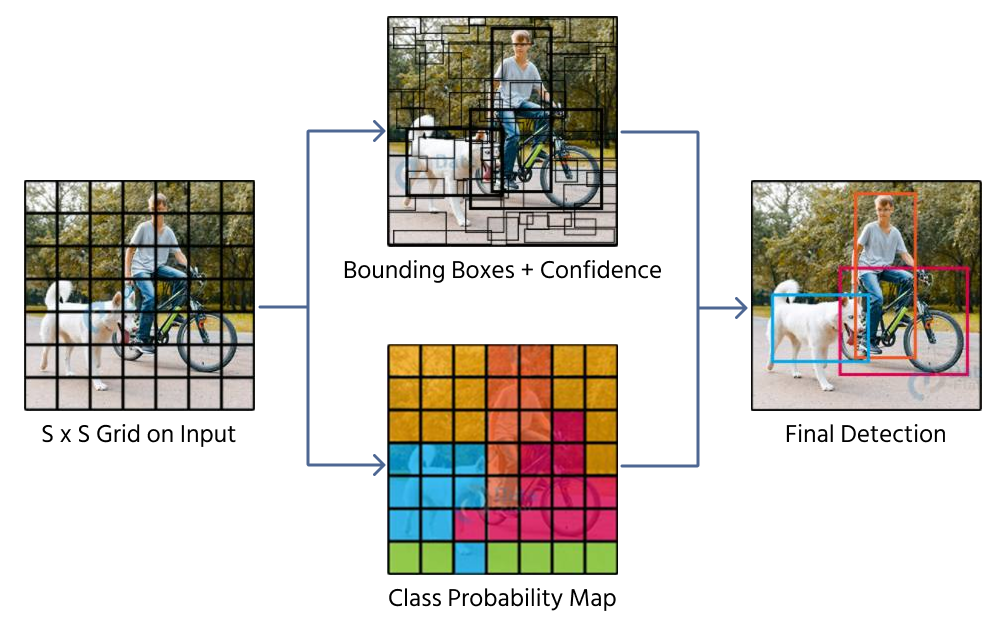
Uma abordagem para prever caixas delimitadoras é a regressão direta, onde uma CNN retorna quatro valores numéricos que representam a posição e o tamanho da caixa. Modelos como o YOLO (You Only Look Once) utilizam essa técnica dividindo uma imagem em uma grade e atribuindo previsões de caixas delimitadoras às células da grade.
No entanto, a regressão direta possui limitações:
- Dificuldade com objetos de tamanhos e proporções variadas;
- Não lida de forma eficaz com objetos sobrepostos;
- As caixas delimitadoras podem se deslocar de maneira imprevisível, causando inconsistências.
Abordagens Baseadas em Âncoras vs. Sem Âncoras
Métodos Baseados em Âncoras
Caixas âncora são caixas delimitadoras predefinidas com tamanhos e proporções fixas. Modelos como Faster R-CNN e SSD (Single Shot MultiBox Detector) utilizam caixas âncora para melhorar a precisão das previsões. O modelo prevê ajustes nas caixas âncora em vez de prever caixas delimitadoras do zero. Este método é eficaz para detectar objetos em diferentes escalas, mas aumenta a complexidade computacional.
Métodos Sem Âncoras
Métodos sem âncoras, como CenterNet e FCOS (Fully Convolutional One-Stage Object Detection), eliminam as caixas âncora predefinidas e, em vez disso, prevêem diretamente os centros dos objetos. Esses métodos oferecem:
- Arquiteturas de modelo mais simples;
- Velocidades de inferência mais rápidas;
- Melhor generalização para tamanhos de objetos não vistos.

A (Baseado em âncoras): prevê deslocamentos (linhas verdes) a partir de âncoras predefinidas (azul) para coincidir com o valor real (vermelho). B (Livre de âncoras): estima diretamente os deslocamentos de um ponto até seus limites.
Predição de caixa delimitadora é um componente essencial da detecção de objetos, e diferentes abordagens equilibram precisão e eficiência. Enquanto métodos baseados em âncoras aumentam a precisão utilizando formas predefinidas, métodos livres de âncoras simplificam a detecção ao prever diretamente as localizações dos objetos. Compreender essas técnicas auxilia no desenvolvimento de sistemas de detecção de objetos mais eficazes para diversas aplicações do mundo real.
1. Quais informações uma previsão de caixa delimitadora normalmente contém?
2. Qual é a principal vantagem dos métodos baseados em âncoras na detecção de objetos?
3. Qual desafio a regressão direta enfrenta na previsão de caixas delimitadoras?
Obrigado pelo seu feedback!
Pergunte à IA
Pergunte à IA

Pergunte o que quiser ou experimente uma das perguntas sugeridas para iniciar nosso bate-papo
Previsões de Caixas Delimitadoras
Caixas delimitadoras são essenciais para a detecção de objetos, fornecendo uma maneira de marcar as localizações dos objetos. Modelos de detecção de objetos utilizam essas caixas para definir a posição e as dimensões dos objetos detectados dentro de uma imagem. Prever caixas delimitadoras com precisão é fundamental para garantir uma detecção de objetos confiável.
Como as CNNs Predizem as Coordenadas das Caixas Delimitadoras
Redes Neurais Convolucionais (CNNs) processam imagens por meio de camadas de convolução e pooling para extrair características. Para detecção de objetos, as CNNs geram mapas de características que representam diferentes partes de uma imagem. A previsão das caixas delimitadoras é normalmente realizada por:
- Extração de representações de características da imagem;
- Aplicação de uma função de regressão para prever as coordenadas das caixas delimitadoras;
- Classificação dos objetos detectados em cada caixa.
As previsões das caixas delimitadoras são representadas como valores numéricos correspondentes a:
- (x, y): as coordenadas do centro da caixa;
- (w, h): a largura e a altura da caixa.
Exemplo: Previsão de Caixas Delimitadoras Utilizando um Modelo Pré-treinado
Em vez de treinar uma CNN do zero, é possível utilizar um modelo pré-treinado como o Faster R-CNN do TensorFlow's model zoo para prever caixas delimitadoras em uma imagem. Abaixo está um exemplo de como carregar um modelo pré-treinado, carregar uma imagem, realizar previsões e visualizar as caixas delimitadoras com os rótulos das classes.
Importar bibliotecas
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Carregar modelo e imagem
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Pré-processar a imagem
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Realizar predição e extrair características da caixa delimitadora
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Desenhar caixas delimitadoras
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualizar
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultado:
Previsões de Caixa Delimitadora Baseadas em Regressão
Uma abordagem para prever caixas delimitadoras é a regressão direta, onde uma CNN retorna quatro valores numéricos que representam a posição e o tamanho da caixa. Modelos como o YOLO (You Only Look Once) utilizam essa técnica dividindo uma imagem em uma grade e atribuindo previsões de caixas delimitadoras às células da grade.
No entanto, a regressão direta possui limitações:
- Dificuldade com objetos de tamanhos e proporções variadas;
- Não lida de forma eficaz com objetos sobrepostos;
- As caixas delimitadoras podem se deslocar de maneira imprevisível, causando inconsistências.
Abordagens Baseadas em Âncoras vs. Sem Âncoras
Métodos Baseados em Âncoras
Caixas âncora são caixas delimitadoras predefinidas com tamanhos e proporções fixas. Modelos como Faster R-CNN e SSD (Single Shot MultiBox Detector) utilizam caixas âncora para melhorar a precisão das previsões. O modelo prevê ajustes nas caixas âncora em vez de prever caixas delimitadoras do zero. Este método é eficaz para detectar objetos em diferentes escalas, mas aumenta a complexidade computacional.
Métodos Sem Âncoras
Métodos sem âncoras, como CenterNet e FCOS (Fully Convolutional One-Stage Object Detection), eliminam as caixas âncora predefinidas e, em vez disso, prevêem diretamente os centros dos objetos. Esses métodos oferecem:
- Arquiteturas de modelo mais simples;
- Velocidades de inferência mais rápidas;
- Melhor generalização para tamanhos de objetos não vistos.
A (Baseado em âncoras): prevê deslocamentos (linhas verdes) a partir de âncoras predefinidas (azul) para coincidir com o valor real (vermelho). B (Livre de âncoras): estima diretamente os deslocamentos de um ponto até seus limites.
Predição de caixa delimitadora é um componente essencial da detecção de objetos, e diferentes abordagens equilibram precisão e eficiência. Enquanto métodos baseados em âncoras aumentam a precisão utilizando formas predefinidas, métodos livres de âncoras simplificam a detecção ao prever diretamente as localizações dos objetos. Compreender essas técnicas auxilia no desenvolvimento de sistemas de detecção de objetos mais eficazes para diversas aplicações do mundo real.
Obrigado pelo seu feedback!
