Parplott
Ett pair plot visualiserar parvisa relationer mellan alla numeriska variabler i en datamängd. Till skillnad från ett joint plot är det inte begränsat till två variabler. Det skapar ett N×N rutnät av delplottar, där N är antalet numeriska kolumner i DataFrame.
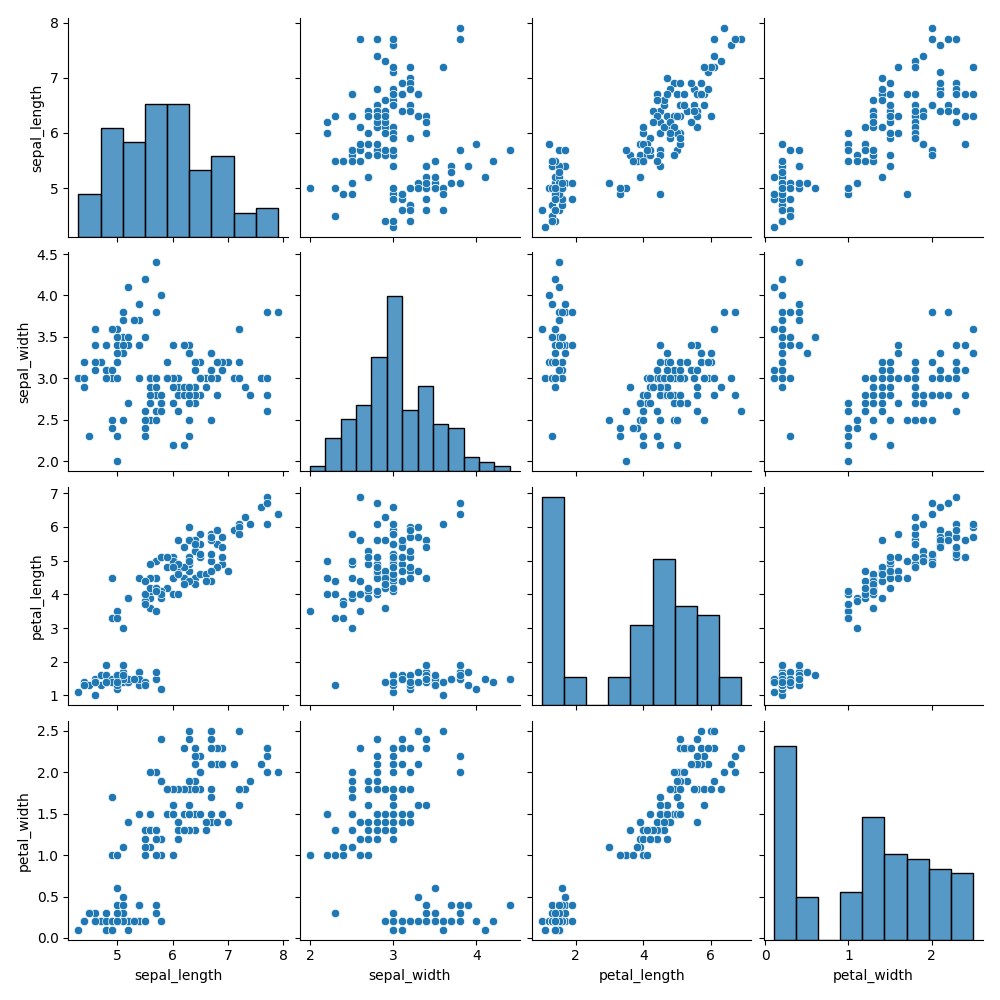
Beskrivning av Pair Plot
Varje kolumn i rutnätet delar samma x-axel-variabel, och varje rad delar samma y-axel. Diagonalen visar histogram för individuella variabler, medan celler utanför diagonalen visar spridningsdiagram.
Skapa ett Pair Plot
Du kan skapa ett med seaborn.pairplot(). Dess enda obligatoriska argument är data, som måste vara en DataFrame. Parametrar som height och aspect anger storleken (i tum) för varje delplott.
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Creating a pair plot sns.pairplot(iris_df, height=2, aspect=0.8) plt.show()
Hue
Parametern hue tilldelar färger baserat på en angiven kategorikolumn. Detta framhäver gruppskillnader och visar, när den används i klassificeringsdatamängder, hur klasser separeras över variabelpar.
När hue är inställd (t.ex. på species), färglägger spridningsdiagrammen punkterna efter klass, och diagonala diagram byter från histogram till KDE-diagram, vilket gör klassfördelningar tydligare.
1234567891011121314import seaborn as sns import matplotlib.pyplot as plt # Ignoring warnings import warnings warnings.filterwarnings('ignore') # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the hue parameter to 'species' sns.pairplot(iris_df, hue='species', height=2, aspect=0.8) plt.show()
Ändra diagramtyper
Det går att anpassa både huvuddiagrammen och de diagonala diagrammen.
kindstyr diagrammen utanför diagonalen (standard:'scatter');diag_kindstyr de diagonala (histogram eller KDE, ofta automatiskt vald närhueanvänds).
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the kind parameter and diag_kind parameters sns.pairplot(iris_df, hue='species', kind='reg', diag_kind=None, height=2, aspect=0.8) plt.show()
'scatter', 'kde', 'hist', 'reg' är möjliga värden för parametern kind.
diag_kind kan ställas in på ett av följande värden:
'auto';'hist';'kde';None.
Allt är liknande funktionen jointplot() i detta avseende.
Utforska mer i pairplot()-dokumentationen.
Tack för dina kommentarer!
single
Parplott
Svep för att visa menyn
Ett pair plot visualiserar parvisa relationer mellan alla numeriska variabler i en datamängd. Till skillnad från ett joint plot är det inte begränsat till två variabler. Det skapar ett N×N rutnät av delplottar, där N är antalet numeriska kolumner i DataFrame.
Beskrivning av Pair Plot
Varje kolumn i rutnätet delar samma x-axel-variabel, och varje rad delar samma y-axel. Diagonalen visar histogram för individuella variabler, medan celler utanför diagonalen visar spridningsdiagram.
Skapa ett Pair Plot
Du kan skapa ett med seaborn.pairplot(). Dess enda obligatoriska argument är data, som måste vara en DataFrame. Parametrar som height och aspect anger storleken (i tum) för varje delplott.
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Creating a pair plot sns.pairplot(iris_df, height=2, aspect=0.8) plt.show()
Hue
Parametern hue tilldelar färger baserat på en angiven kategorikolumn. Detta framhäver gruppskillnader och visar, när den används i klassificeringsdatamängder, hur klasser separeras över variabelpar.
När hue är inställd (t.ex. på species), färglägger spridningsdiagrammen punkterna efter klass, och diagonala diagram byter från histogram till KDE-diagram, vilket gör klassfördelningar tydligare.
1234567891011121314import seaborn as sns import matplotlib.pyplot as plt # Ignoring warnings import warnings warnings.filterwarnings('ignore') # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the hue parameter to 'species' sns.pairplot(iris_df, hue='species', height=2, aspect=0.8) plt.show()
Ändra diagramtyper
Det går att anpassa både huvuddiagrammen och de diagonala diagrammen.
kindstyr diagrammen utanför diagonalen (standard:'scatter');diag_kindstyr de diagonala (histogram eller KDE, ofta automatiskt vald närhueanvänds).
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the kind parameter and diag_kind parameters sns.pairplot(iris_df, hue='species', kind='reg', diag_kind=None, height=2, aspect=0.8) plt.show()
'scatter', 'kde', 'hist', 'reg' är möjliga värden för parametern kind.
diag_kind kan ställas in på ett av följande värden:
'auto';'hist';'kde';None.
Allt är liknande funktionen jointplot() i detta avseende.
Utforska mer i pairplot()-dokumentationen.
Svep för att börja koda
- Använd rätt funktion för att skapa ett pair plot.
- Ange datan för diagrammet till
penguins_dfvia det första argumentet. - Ange
'sex'som kolumnen som mappar diagrammets aspekter till olika färger genom att specificera det andra argumentet. - Ange att icke-diagonala diagram ska ha en regressionslinje (
'reg') genom att specificera det tredje argumentet. - Sätt
heighttill2. - Sätt
aspecttill0.8.
Lösning
Tack för dina kommentarer!
single
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
