Sambandsdiagram
Joint plot är ett ganska unikt diagram, eftersom det kombinerar flera diagramtyper. Det är ett diagram som visar sambandet mellan två variabler tillsammans med deras individuella fördelningar.
Ett joint plot kombinerar tre element:
- ett histogram överst (fördelning av x-variabeln);
- ett histogram till höger (fördelning av y-variabeln);
- ett scatter plot i mitten (relationen mellan de två variablerna).
Här är ett exempel:
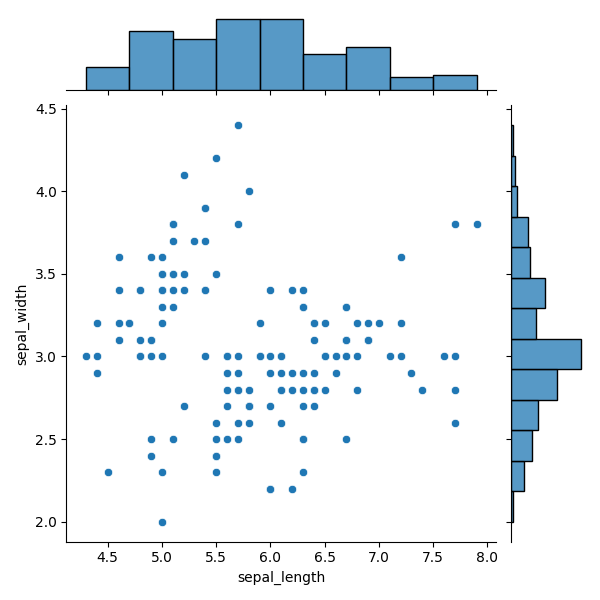
Data för Joint Plot
seaborn.jointplot() använder tre huvudparametrar:
data— DataFrame,x— variabel för det övre histogrammet,y— variabel för det högra histogrammet.
x och y kan vara kolumnnamn eller array-liknande objekt.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
Exemplet återskapas genom att en DataFrame skickas till data och kolumnnamn anges för x och y.
Diagram i mitten
Parametern kind styr typen av central diagram.
Standardvärde: 'scatter'.
Andra alternativ inkluderar: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Diagramtyper
Förutom scatter kan du välja:
- reg — lägger till en linjär regressionsanpassning;
- resid — visar regressionsresidualer;
- hist — bivariat histogram;
- kde — tvåvariabels KDE;
- hex — hexbin-diagram som visar densitet med färgade hexagonala fält.
Som vanligt kan du utforska fler alternativ och parametrar i jointplot() dokumentation.
Det är också värt att utforska följande ämnen:
residplot() dokumentation;
Exempel på bivariat histogram;
Exempel på hexbin-diagram.
Tack för dina kommentarer!
single
Sambandsdiagram
Svep för att visa menyn
Joint plot är ett ganska unikt diagram, eftersom det kombinerar flera diagramtyper. Det är ett diagram som visar sambandet mellan två variabler tillsammans med deras individuella fördelningar.
Ett joint plot kombinerar tre element:
- ett histogram överst (fördelning av x-variabeln);
- ett histogram till höger (fördelning av y-variabeln);
- ett scatter plot i mitten (relationen mellan de två variablerna).
Här är ett exempel:
Data för Joint Plot
seaborn.jointplot() använder tre huvudparametrar:
data— DataFrame,x— variabel för det övre histogrammet,y— variabel för det högra histogrammet.
x och y kan vara kolumnnamn eller array-liknande objekt.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width") plt.show()
Exemplet återskapas genom att en DataFrame skickas till data och kolumnnamn anges för x och y.
Diagram i mitten
Parametern kind styr typen av central diagram.
Standardvärde: 'scatter'.
Andra alternativ inkluderar: 'kde', 'hist', 'hex', 'reg', 'resid'.
12345678import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris flowers species iris_df = sns.load_dataset("iris") sns.jointplot(data=iris_df, x="sepal_length", y="sepal_width", kind='reg') plt.show()
Diagramtyper
Förutom scatter kan du välja:
- reg — lägger till en linjär regressionsanpassning;
- resid — visar regressionsresidualer;
- hist — bivariat histogram;
- kde — tvåvariabels KDE;
- hex — hexbin-diagram som visar densitet med färgade hexagonala fält.
Som vanligt kan du utforska fler alternativ och parametrar i jointplot() dokumentation.
Det är också värt att utforska följande ämnen:
residplot() dokumentation;
Exempel på bivariat histogram;
Exempel på hexbin-diagram.
Svep för att börja koda
- Använd rätt funktion för att skapa ett joint plot.
- Använd
weather_dfsom data för diagrammet (det första argumentet). - Ange kolumnen
'Boston'som variabel för x-axeln (det andra argumentet). - Ange kolumnen
'Seattle'som variabel för y-axeln (det tredje argumentet). - Ställ in diagrammet i mitten så att det har en regressionslinje (det sista argumentet).
Lösning
Tack för dina kommentarer!
single
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
