Implementera Word2Vec
Svep för att visa menyn
Efter att ha förstått hur Word2Vec fungerar, går vi vidare till att implementera det med Python. Gensim-biblioteket, ett robust open source-verktyg för naturlig språkbehandling, erbjuder en enkel implementation via sin Word2Vec-klass i gensim.models.
Förbereda data
Word2Vec kräver att textdata tokeniseras, det vill säga delas upp i en lista av listor där varje inre lista innehåller ord från en specifik mening. I detta exempel används romanen Emma av den engelska författaren Jane Austen som korpus. En CSV-fil med förbehandlade meningar laddas in och varje mening delas sedan upp i ord:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() tillämpar metoden .split() på varje mening i kolumnen 'Sentence', vilket resulterar i en lista med ord för varje mening. Eftersom meningarna redan har förbehandlats, med ord separerade av blanksteg, är metoden .split() tillräcklig för denna tokenisering.
Träning av Word2Vec-modellen
Nu fokuserar vi på att träna Word2Vec-modellen med den tokeniserade datan. Klassen Word2Vec erbjuder flera parametrar för anpassning. De vanligaste parametrarna är:
vector_size(standardvärde 100): dimensionen eller storleken på ordbeskrivningarna;window(standardvärde 5): storleken på kontextfönstret;min_count(standardvärde 5): ord som förekommer färre gånger än detta ignoreras;sg(standardvärde 0): modellarkitektur (1 för Skip-gram, 0 för CBoW).cbow_mean(standardvärde 1): anger om CBoW-kontexten summeras (0) eller medelvärdesberäknas (1)
När det gäller modellarkitekturer är CBoW lämplig för större datamängder och situationer där beräkningshastighet är avgörande. Skip-gram är däremot att föredra för uppgifter som kräver detaljerad förståelse av ordkontext, särskilt effektivt för mindre datamängder eller när man arbetar med ovanliga ord.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Här sätter vi inbäddningsstorleken till 200, kontextfönstrets storlek till 5, och inkluderade alla ord genom att sätta min_count=1. Genom att sätta sg=0 valde vi att använda CBoW-modellen.
Att välja rätt inbäddningsstorlek och kontextfönster innebär avvägningar. Större inbäddningar fångar mer betydelse men ökar beräkningskostnaden och risken för överanpassning. Mindre kontextfönster är bättre på att fånga syntax, medan större är bättre på att fånga semantik.
Hitta Liknande Ord
När ord representeras som vektorer kan vi jämföra dem för att mäta likhet. Att använda avstånd är ett alternativ, men riktningen av en vektor bär ofta mer semantisk betydelse än dess storlek, särskilt i ordbäddningar.
Att använda en vinkel som likhetsmått är dock inte så praktiskt. Istället kan vi använda cosinus för vinkeln mellan två vektorer, även känt som cosinuslikhet. Den varierar från -1 till 1, där högre värden indikerar starkare likhet. Detta tillvägagångssätt fokuserar på hur väl vektorerna är riktade mot varandra, oavsett deras längd, vilket gör det idealiskt för att jämföra ords betydelser. Här är en illustration:
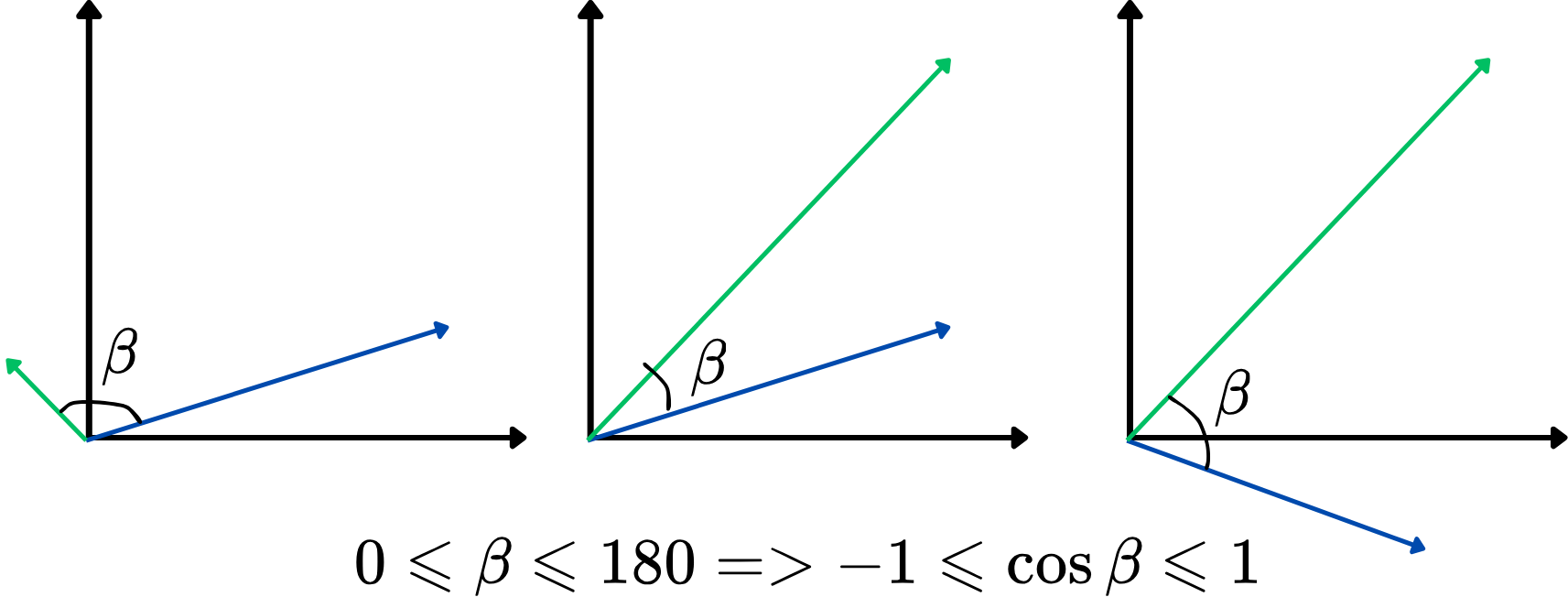
Ju högre cosinuslikhet, desto mer lika är de två vektorerna, och vice versa. Om till exempel två ordvektorer har en cosinuslikhet nära 1 (vinkeln nära 0 grader), indikerar det att de är nära relaterade eller liknande i kontext inom vektorrummet.
Låt oss nu hitta de fem mest liknande orden till ordet "man" med hjälp av cosinuslikhet:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv ger åtkomst till ordvektorerna i den tränade modellen, medan metoden .most_similar() hittar de ord vars inbäddningar ligger närmast inbäddningen för det angivna ordet, baserat på cosinuslikhet. Parametern topn bestämmer antalet topp-N liknande ord som returneras.
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
Implementera Word2Vec
Efter att ha förstått hur Word2Vec fungerar, går vi vidare till att implementera det med Python. Gensim-biblioteket, ett robust open source-verktyg för naturlig språkbehandling, erbjuder en enkel implementation via sin Word2Vec-klass i gensim.models.
Förbereda data
Word2Vec kräver att textdata tokeniseras, det vill säga delas upp i en lista av listor där varje inre lista innehåller ord från en specifik mening. I detta exempel används romanen Emma av den engelska författaren Jane Austen som korpus. En CSV-fil med förbehandlade meningar laddas in och varje mening delas sedan upp i ord:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() tillämpar metoden .split() på varje mening i kolumnen 'Sentence', vilket resulterar i en lista med ord för varje mening. Eftersom meningarna redan har förbehandlats, med ord separerade av blanksteg, är metoden .split() tillräcklig för denna tokenisering.
Träning av Word2Vec-modellen
Nu fokuserar vi på att träna Word2Vec-modellen med den tokeniserade datan. Klassen Word2Vec erbjuder flera parametrar för anpassning. De vanligaste parametrarna är:
vector_size(standardvärde 100): dimensionen eller storleken på ordbeskrivningarna;window(standardvärde 5): storleken på kontextfönstret;min_count(standardvärde 5): ord som förekommer färre gånger än detta ignoreras;sg(standardvärde 0): modellarkitektur (1 för Skip-gram, 0 för CBoW).cbow_mean(standardvärde 1): anger om CBoW-kontexten summeras (0) eller medelvärdesberäknas (1)
När det gäller modellarkitekturer är CBoW lämplig för större datamängder och situationer där beräkningshastighet är avgörande. Skip-gram är däremot att föredra för uppgifter som kräver detaljerad förståelse av ordkontext, särskilt effektivt för mindre datamängder eller när man arbetar med ovanliga ord.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Här sätter vi inbäddningsstorleken till 200, kontextfönstrets storlek till 5, och inkluderade alla ord genom att sätta min_count=1. Genom att sätta sg=0 valde vi att använda CBoW-modellen.
Att välja rätt inbäddningsstorlek och kontextfönster innebär avvägningar. Större inbäddningar fångar mer betydelse men ökar beräkningskostnaden och risken för överanpassning. Mindre kontextfönster är bättre på att fånga syntax, medan större är bättre på att fånga semantik.
Hitta Liknande Ord
När ord representeras som vektorer kan vi jämföra dem för att mäta likhet. Att använda avstånd är ett alternativ, men riktningen av en vektor bär ofta mer semantisk betydelse än dess storlek, särskilt i ordbäddningar.
Att använda en vinkel som likhetsmått är dock inte så praktiskt. Istället kan vi använda cosinus för vinkeln mellan två vektorer, även känt som cosinuslikhet. Den varierar från -1 till 1, där högre värden indikerar starkare likhet. Detta tillvägagångssätt fokuserar på hur väl vektorerna är riktade mot varandra, oavsett deras längd, vilket gör det idealiskt för att jämföra ords betydelser. Här är en illustration:
Ju högre cosinuslikhet, desto mer lika är de två vektorerna, och vice versa. Om till exempel två ordvektorer har en cosinuslikhet nära 1 (vinkeln nära 0 grader), indikerar det att de är nära relaterade eller liknande i kontext inom vektorrummet.
Låt oss nu hitta de fem mest liknande orden till ordet "man" med hjälp av cosinuslikhet:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv ger åtkomst till ordvektorerna i den tränade modellen, medan metoden .most_similar() hittar de ord vars inbäddningar ligger närmast inbäddningen för det angivna ordet, baserat på cosinuslikhet. Parametern topn bestämmer antalet topp-N liknande ord som returneras.
Tack för dina kommentarer!
