Översikt över Populära CNN-modeller
Svep för att visa menyn
Konvolutionella neurala nätverk (CNNs) har utvecklats avsevärt, med olika arkitekturer som förbättrar noggrannhet, effektivitet och skalbarhet. Detta kapitel utforskar fem centrala CNN-modeller som har format djupinlärning: LeNet, AlexNet, VGGNet, ResNet och InceptionNet.
LeNet: Grunden för CNNs
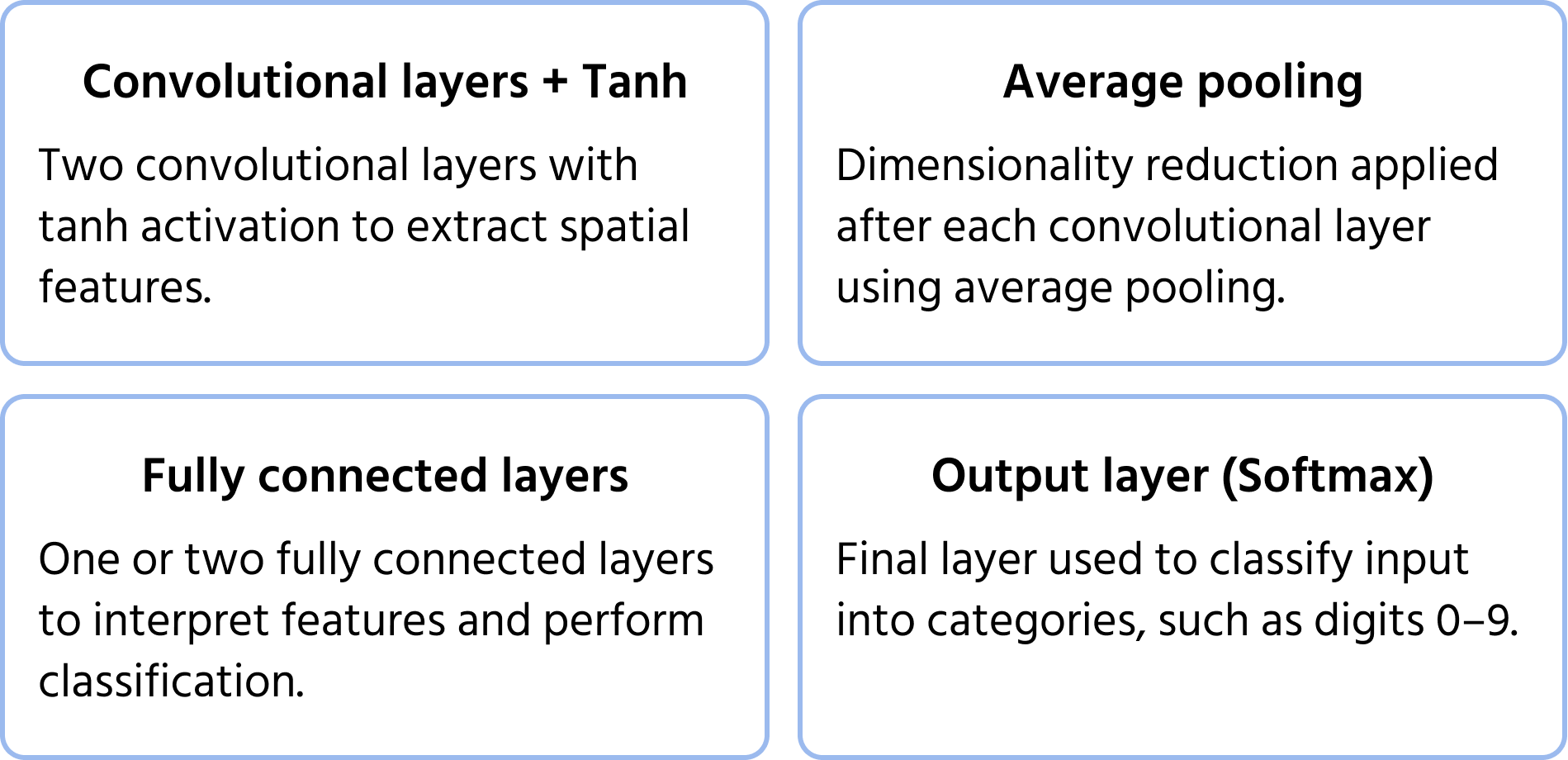
En av de första konvolutionella neurala nätverksarkitekturerna, föreslagen av Yann LeCun 1998 för handskriven sifferigenkänning. Den lade grunden för moderna CNNs genom att introducera viktiga komponenter såsom konvolutioner, pooling och fullt anslutna lager. Du kan läsa mer om modellen i dokumentationen.
Viktiga arkitekturella egenskaper
AlexNet: Genombrott inom djupinlärning
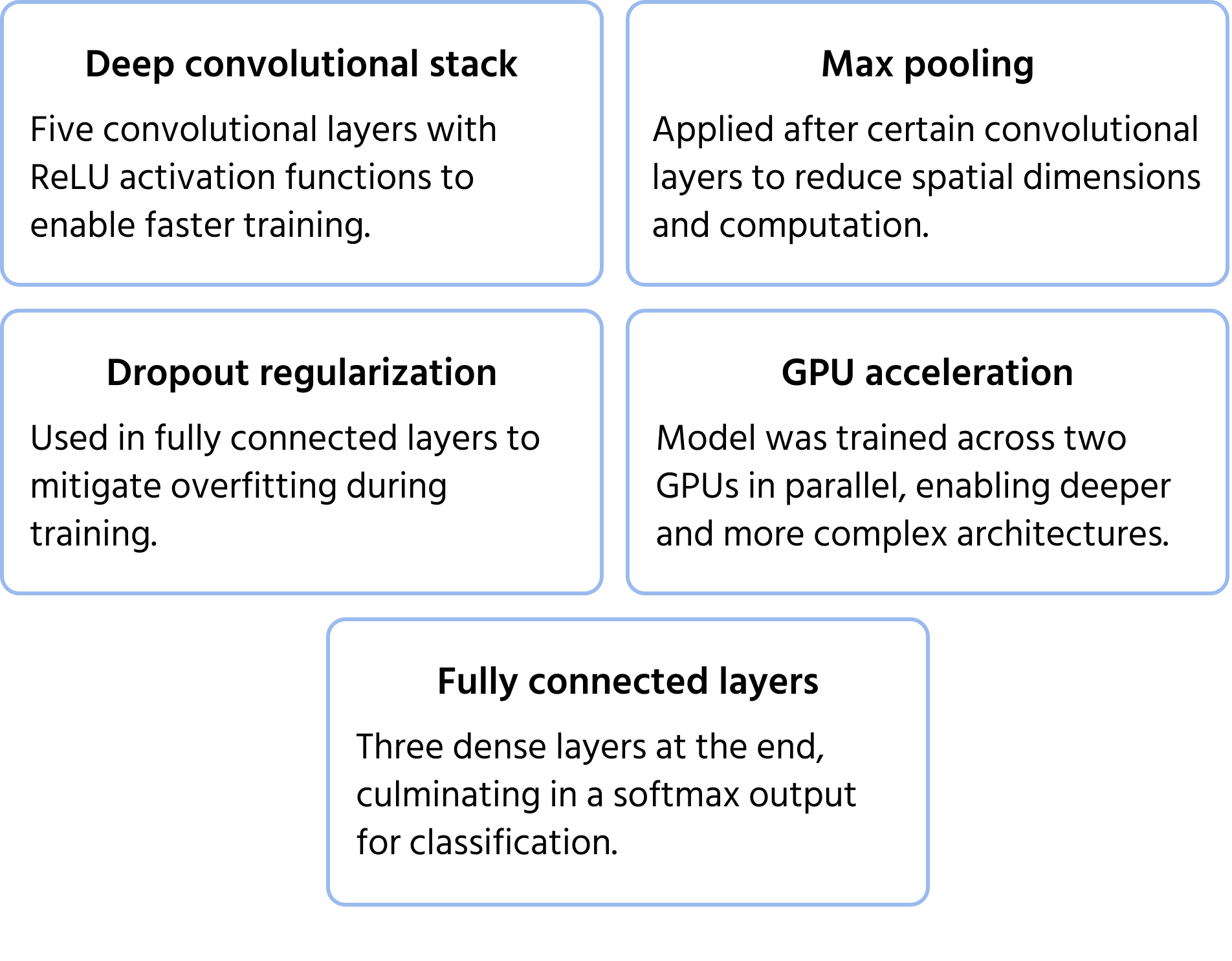
En banbrytande CNN-arkitektur som vann ImageNet-tävlingen 2012. AlexNet visade att djupa konvolutionella nätverk kunde överträffa traditionella maskininlärningsmetoder avsevärt vid storskalig bildklassificering. Den introducerade innovationer som blev standard inom modern djupinlärning. Du kan läsa mer om modellen i dokumentationen.
Viktiga arkitekturella egenskaper
VGGNet: Djupare nätverk med enhetliga filter
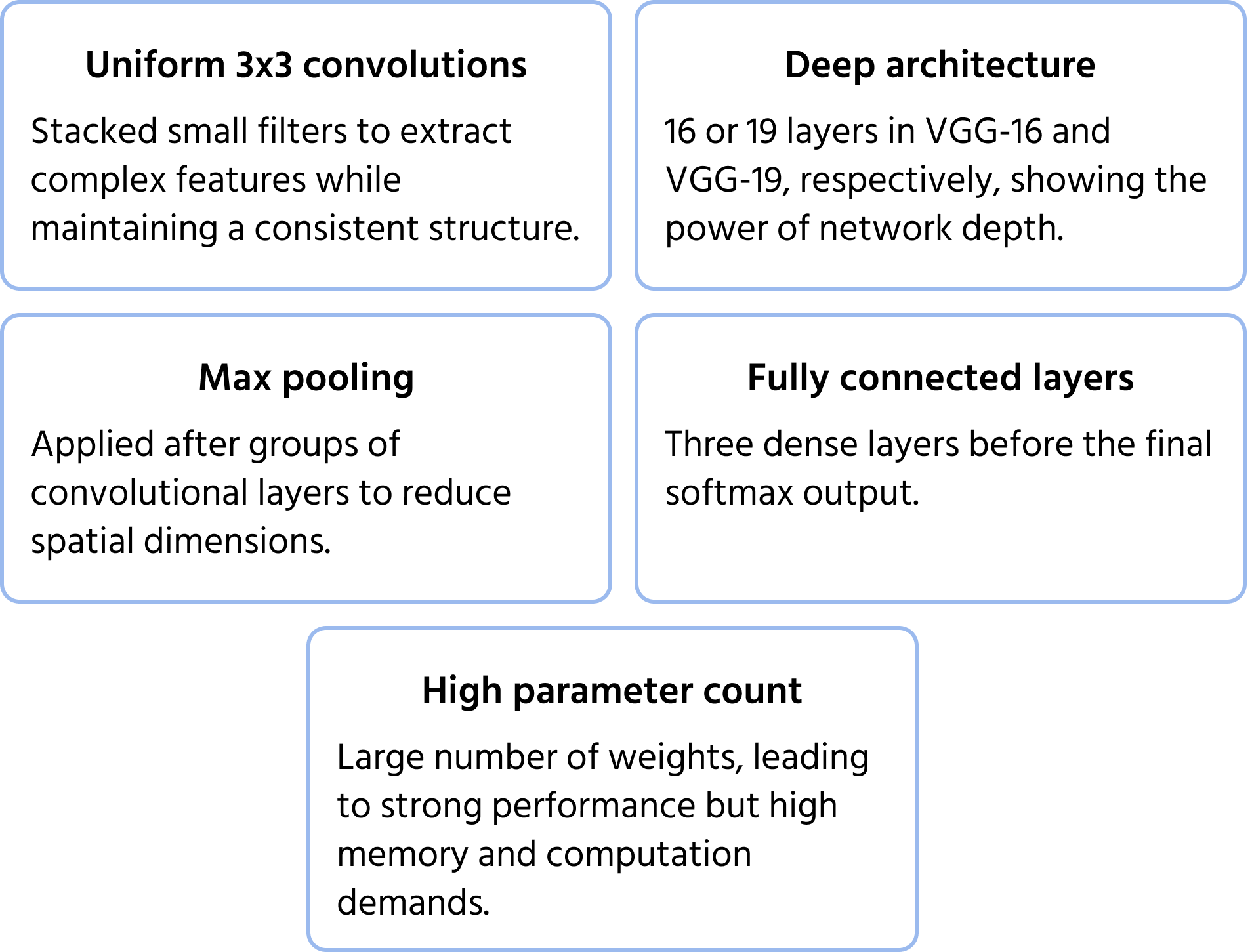
Utvecklad av Visual Geometry Group vid Oxford, betonade VGGNet djup och enkelhet genom att använda enhetliga 3×3-konvolutionsfilter. Den visade att stapling av små filter i djupa nätverk avsevärt kunde förbättra prestandan, vilket ledde till allmänt använda varianter som VGG-16 och VGG-19. Du kan läsa mer om modellen i dokumentationen.
Viktiga arkitekturella egenskaper
ResNet: Lösning på djuphetsproblemet
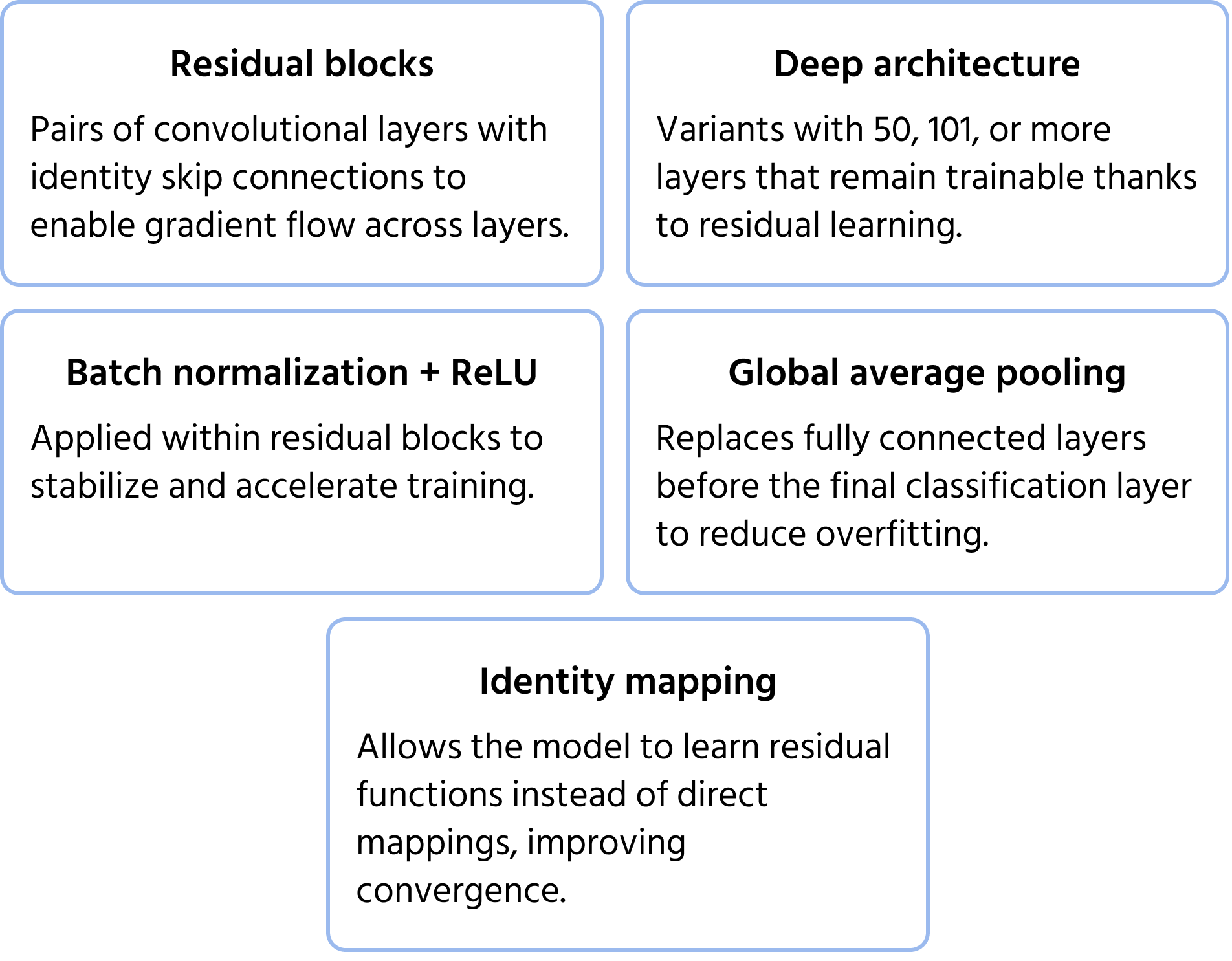
ResNet (Residual Networks), introducerad av Microsoft 2015, adresserade problemet med försvinnande gradient, vilket uppstår vid träning av mycket djupa nätverk. Traditionella djupa nätverk har svårigheter med träningseffektivitet och prestandaförsämring, men ResNet övervann detta problem med skip connections (residuellt lärande). Dessa genvägar tillåter information att kringgå vissa lager, vilket säkerställer att gradienter fortsätter att propagera effektivt. ResNet-arkitekturer, såsom ResNet-50 och ResNet-101, möjliggjorde träning av nätverk med hundratals lager och förbättrade därmed bildklassificeringens noggrannhet avsevärt. Mer information om modellen finns i dokumentationen.
Viktiga arkitekturella egenskaper
InceptionNet: Multiskalig funktionsutvinning
InceptionNet (även känd som GoogLeNet) bygger på inception-modulen för att skapa en djup men effektiv arkitektur. Istället för att stapla lager sekventiellt använder InceptionNet parallella vägar för att extrahera funktioner på olika nivåer. Mer information om modellen finns i dokumentationen.
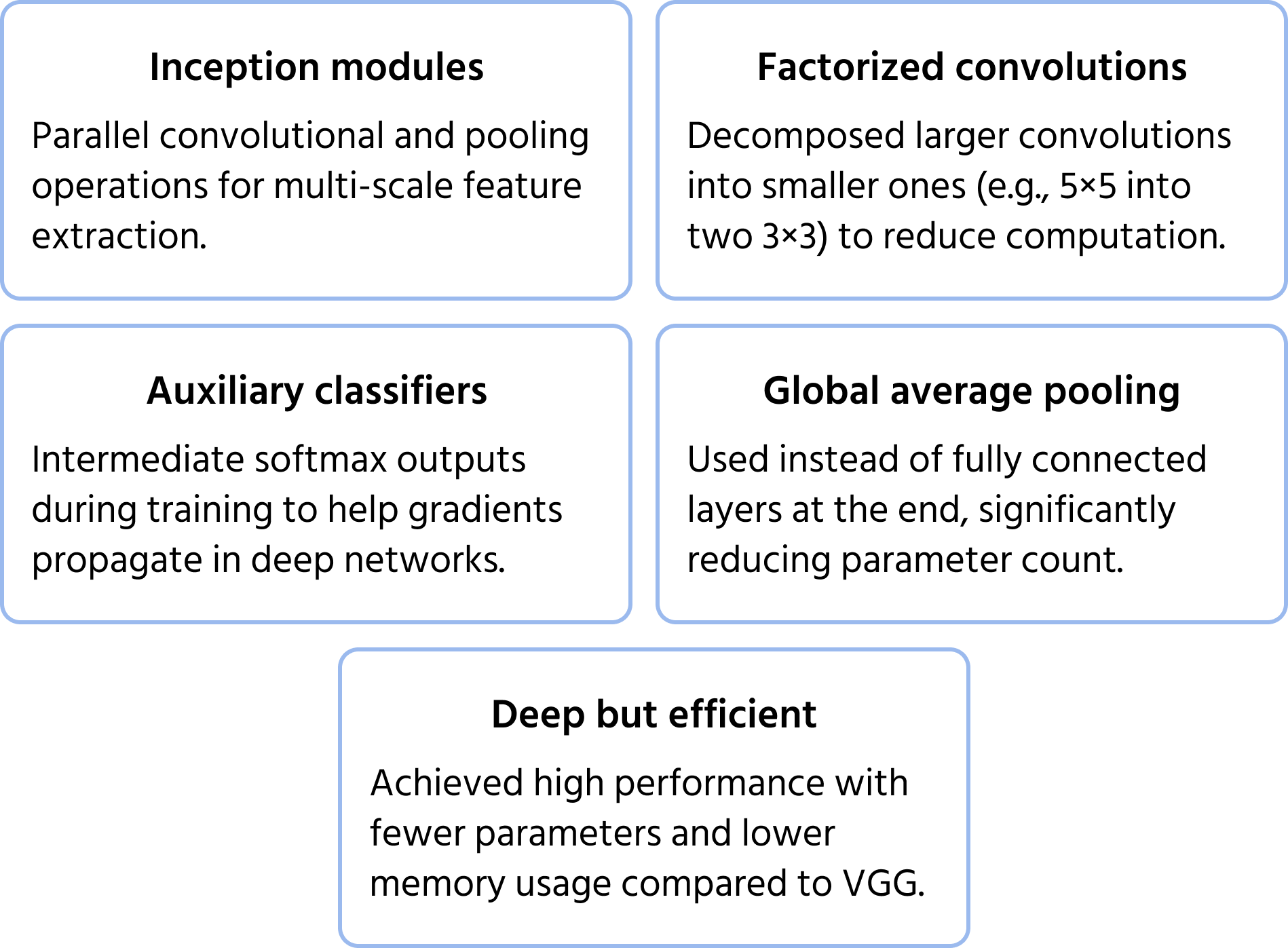
Viktiga optimeringar inkluderar:
- Faktorerade konvolutioner för att minska beräkningskostnaden;
- Hjälpklassificerare i mellanliggande lager för att förbättra träningsstabiliteten;
- Global medelpoolning istället för helt anslutna lager, vilket minskar antalet parametrar samtidigt som prestandan bibehålls.
Denna struktur gör det möjligt för InceptionNet att vara djupare än tidigare CNN:er som VGG, utan att drastiskt öka de beräkningsmässiga kraven.
Viktiga arkitekturegenskaper
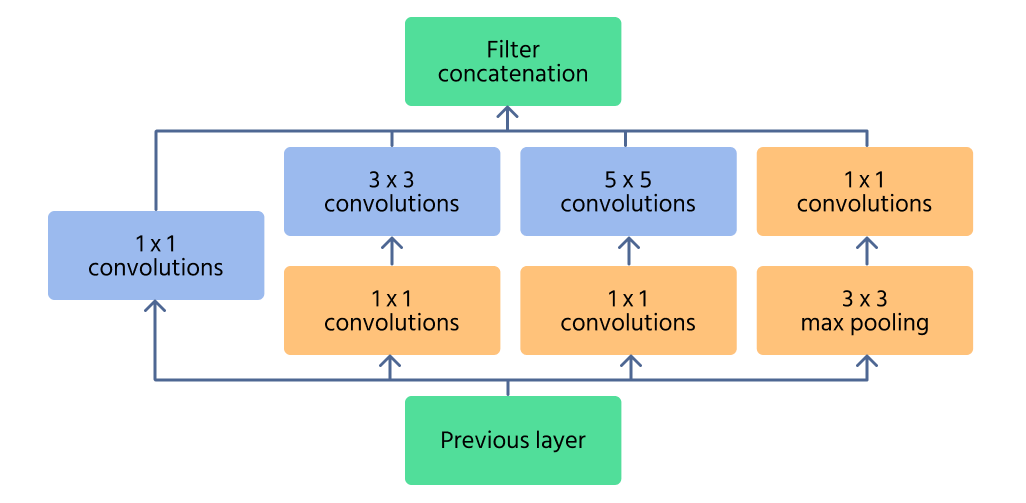
Inception-modul
Inception-modulen är kärnkomponenten i InceptionNet, utformad för att effektivt fånga egenskaper på flera skalor. Istället för att använda en enda konvolutionsoperation, bearbetar modulen indata med flera filterstorlekar (1×1, 3×3, 5×5) parallellt. Detta gör det möjligt för nätverket att identifiera både fina detaljer och stora mönster i en bild.
För att minska beräkningskostnaden används 1×1 convolutions innan större filter appliceras. Dessa minskar antalet indatakaneler, vilket gör nätverket mer effektivt. Dessutom hjälper maxpooling-lager inom modulen till att bevara viktiga egenskaper samtidigt som dimensionsstorleken kontrolleras.
Exempel
Betrakta ett exempel för att se hur minskning av dimensioner minskar den beräkningsmässiga belastningen. Antag att vi behöver konvolvera 28 × 28 × 192 input feature maps med 5 × 5 × 32 filters. Denna operation skulle kräva ungefär 120,42 miljoner beräkningar.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Låt oss utföra beräkningarna igen, men denna gång placera ett 1×1 convolutional layer före tillämpningen av 5×5 convolution på samma indata-funktionskartor.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Var och en av dessa CNN-arkitekturer har spelat en avgörande roll i utvecklingen av datorseende och påverkat tillämpningar inom hälso- och sjukvård, autonoma system, säkerhet och bildbehandling i realtid. Från LeNets grundläggande principer till InceptionNets extrahering av funktioner i flera skalor har dessa modeller ständigt drivit gränserna för djupinlärning och banat väg för ännu mer avancerade arkitekturer i framtiden.
1. Vilken var den primära innovationen som introducerades av ResNet och möjliggjorde träning av extremt djupa nätverk?
2. Hur förbättrar InceptionNet den beräkningsmässiga effektiviteten jämfört med traditionella CNN:er?
3. Vilken CNN-arkitektur introducerade först konceptet att använda små 3×3-konvolutionsfilter genom hela nätverket?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
