Poolningslager
Svep för att visa menyn
Syftet med pooling
Pooling-lager spelar en avgörande roll i konvolutionella neurala nätverk (CNN) genom att minska de rumsliga dimensionerna hos funktionskartor samtidigt som väsentlig information bevaras. Detta bidrar till:
- Dimensionalitetsreduktion: minskad beräkningskomplexitet och minnesanvändning;
- Bevarande av egenskaper: bibehåller de mest relevanta detaljerna för efterföljande lager;
- Förebyggande av överanpassning: minskar risken för att fånga upp brus och irrelevanta detaljer;
- Translationsinvarians: gör nätverket mer robust mot variationer i objektens positioner inom en bild.
Typer av pooling
Pooling-lager fungerar genom att applicera ett litet fönster över funktionskartor och aggregera värden på olika sätt. De huvudsakliga typerna av pooling inkluderar:
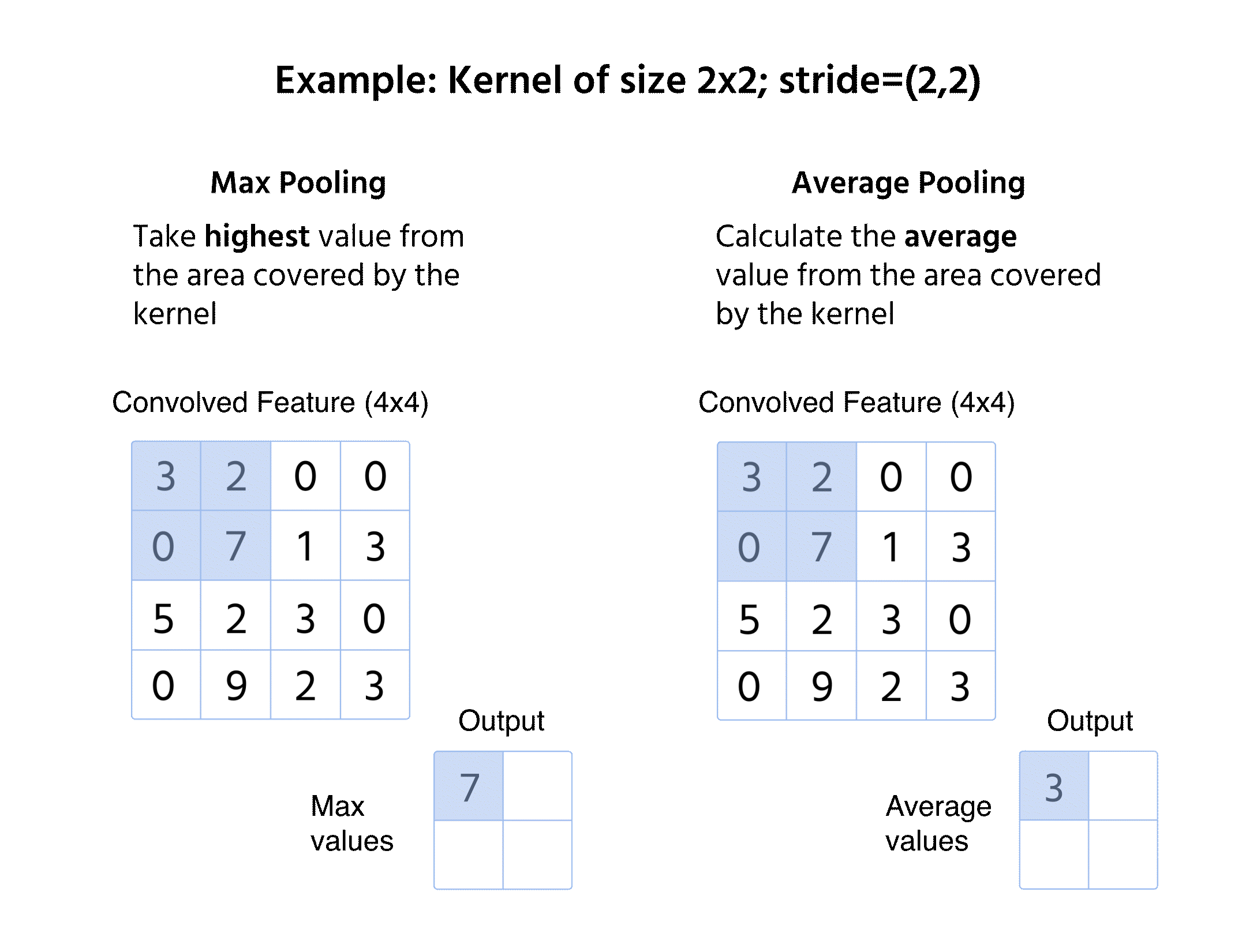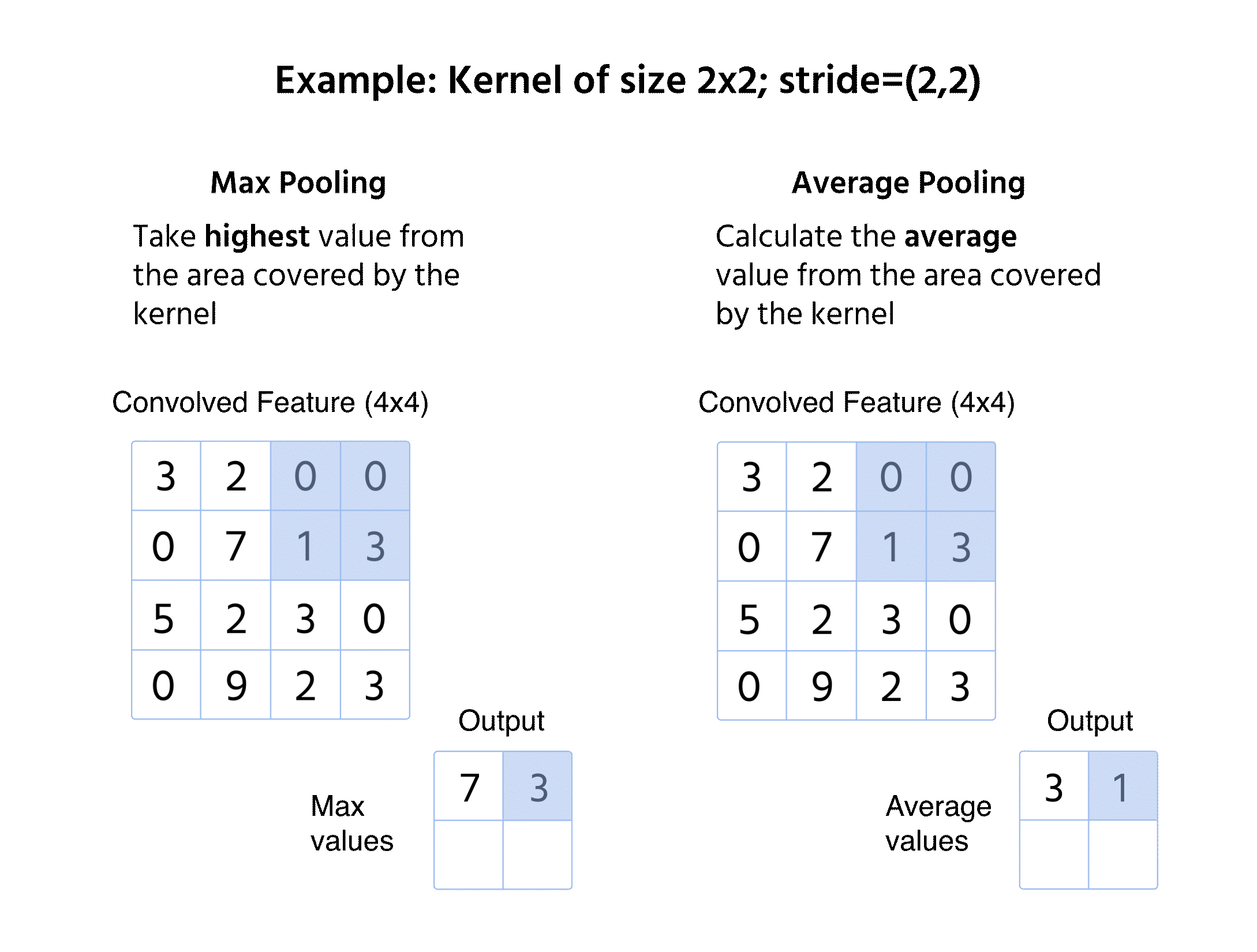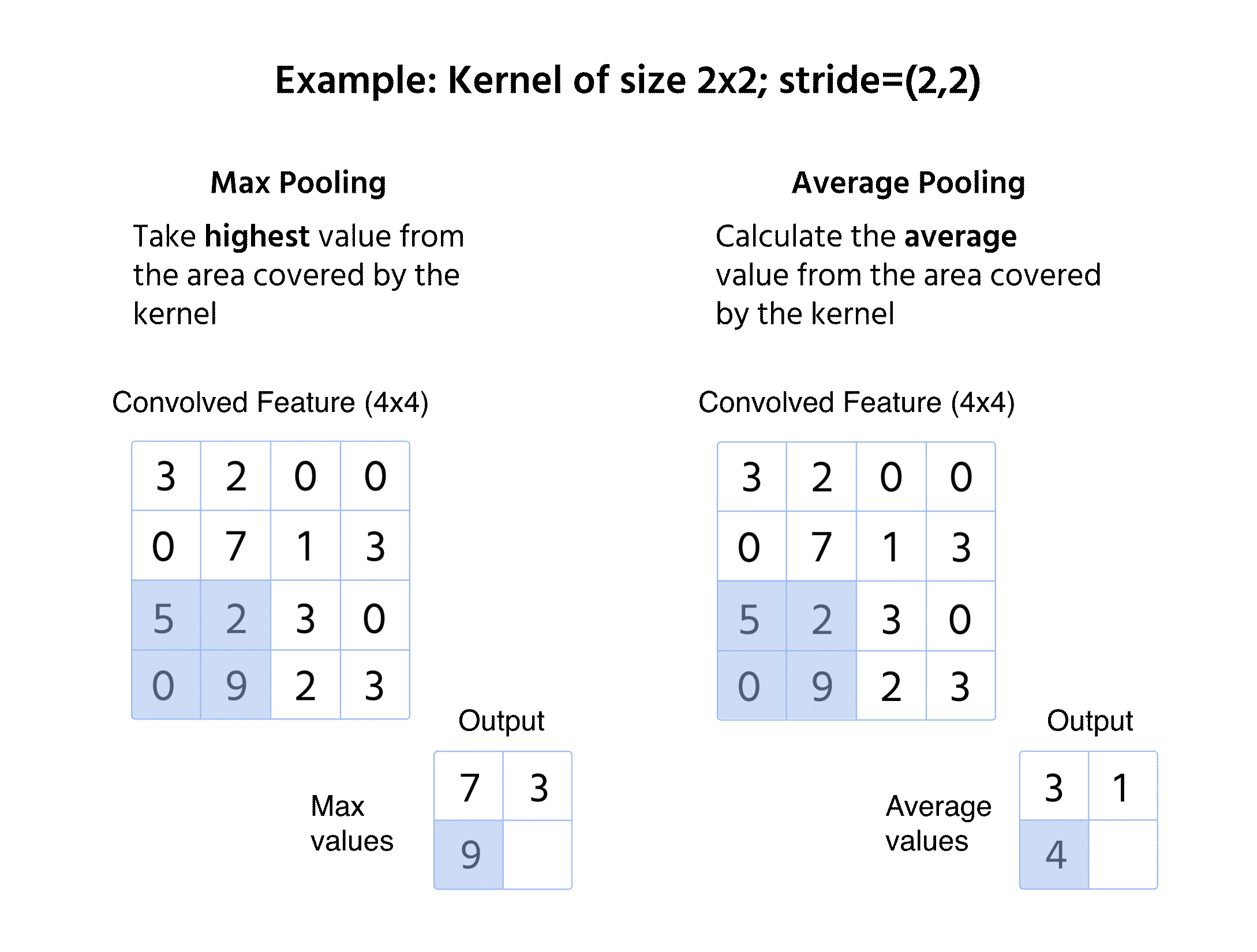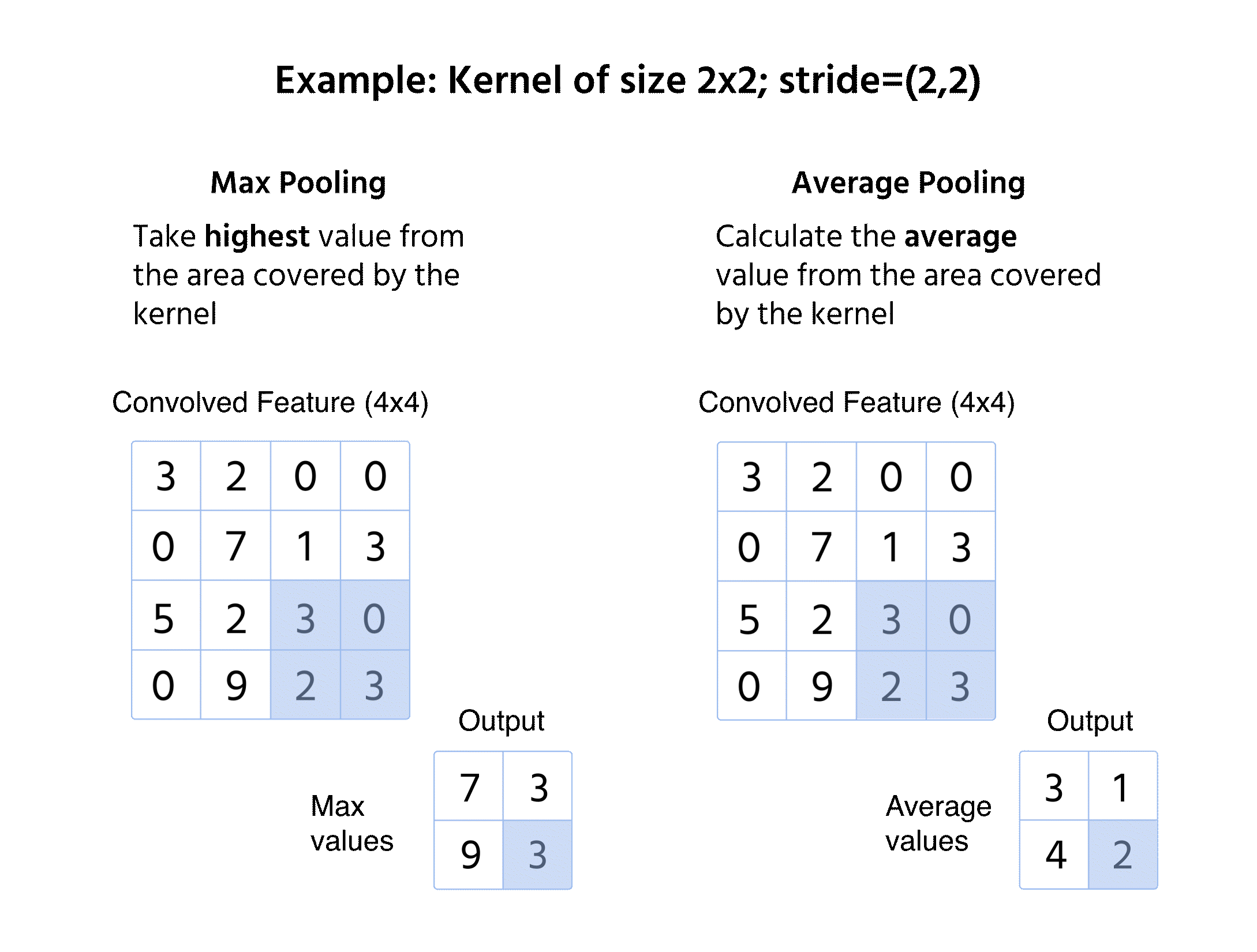
Maxpooling
- Väljer det högsta värdet från fönstret;
- Bevarar dominerande egenskaper och bortser från mindre variationer;
- Vanligt förekommande tack vare förmågan att behålla skarpa och framträdande kanter.
Medelvärdespooling
- Beräknar medelvärdet inom fönstret;
- Ger en mjukare funktionskarta genom att minska extrema variationer;
- Mindre vanligt än maxpooling men användbart i vissa tillämpningar såsom objektlokalisering.
Global Pooling
- Istället för att använda ett litet fönster, poolas över hela feature-mappen;
- Det finns två typer av global pooling:
- Global max pooling: Tar det maximala värdet över hela feature-mappen;
- Global average pooling: Beräknar medelvärdet av alla värden i feature-mappen.
- Används ofta i fullt konvolutionella nätverk för klassificeringsuppgifter.
Vid pooling appliceras ingen kernel på indata, utan vi förenklar informationen med en matematisk operation (Max eller Medel).
Fördelar med pooling i CNN:er
Pooling förbättrar prestandan hos CNN:er på flera sätt:
- Translationsinvarians: små förskjutningar i en bild förändrar inte utdata avsevärt eftersom pooling fokuserar på de mest betydelsefulla egenskaperna;
- Minskad överanpassning: förenklar feature maps och förhindrar överdriven inlärning av träningsdata;
- Förbättrad beräkningseffektivitet: minskning av storleken på feature maps snabbar upp bearbetningen och minskar minneskraven.
Pooling-lager är en grundläggande komponent i CNN-arkitekturer och säkerställer att nätverken extraherar meningsfull information samtidigt som effektivitet och generaliseringsförmåga bibehålls.
1. Vad är det primära syftet med pooling-lager i en CNN?
2. Vilken pooling-metod väljer det mest dominerande värdet i ett givet område?
3. Hur hjälper pooling till att förhindra överanpassning i CNN:er?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
Poolningslager
Syftet med pooling
Pooling-lager spelar en avgörande roll i konvolutionella neurala nätverk (CNN) genom att minska de rumsliga dimensionerna hos funktionskartor samtidigt som väsentlig information bevaras. Detta bidrar till:
- Dimensionalitetsreduktion: minskad beräkningskomplexitet och minnesanvändning;
- Bevarande av egenskaper: bibehåller de mest relevanta detaljerna för efterföljande lager;
- Förebyggande av överanpassning: minskar risken för att fånga upp brus och irrelevanta detaljer;
- Translationsinvarians: gör nätverket mer robust mot variationer i objektens positioner inom en bild.
Typer av pooling
Pooling-lager fungerar genom att applicera ett litet fönster över funktionskartor och aggregera värden på olika sätt. De huvudsakliga typerna av pooling inkluderar:
Maxpooling
- Väljer det högsta värdet från fönstret;
- Bevarar dominerande egenskaper och bortser från mindre variationer;
- Vanligt förekommande tack vare förmågan att behålla skarpa och framträdande kanter.
Medelvärdespooling
- Beräknar medelvärdet inom fönstret;
- Ger en mjukare funktionskarta genom att minska extrema variationer;
- Mindre vanligt än maxpooling men användbart i vissa tillämpningar såsom objektlokalisering.
Global Pooling
- Istället för att använda ett litet fönster, poolas över hela feature-mappen;
- Det finns två typer av global pooling:
- Global max pooling: Tar det maximala värdet över hela feature-mappen;
- Global average pooling: Beräknar medelvärdet av alla värden i feature-mappen.
- Används ofta i fullt konvolutionella nätverk för klassificeringsuppgifter.
Vid pooling appliceras ingen kernel på indata, utan vi förenklar informationen med en matematisk operation (Max eller Medel).
Fördelar med pooling i CNN:er
Pooling förbättrar prestandan hos CNN:er på flera sätt:
- Translationsinvarians: små förskjutningar i en bild förändrar inte utdata avsevärt eftersom pooling fokuserar på de mest betydelsefulla egenskaperna;
- Minskad överanpassning: förenklar feature maps och förhindrar överdriven inlärning av träningsdata;
- Förbättrad beräkningseffektivitet: minskning av storleken på feature maps snabbar upp bearbetningen och minskar minneskraven.
Pooling-lager är en grundläggande komponent i CNN-arkitekturer och säkerställer att nätverken extraherar meningsfull information samtidigt som effektivitet och generaliseringsförmåga bibehålls.
Tack för dina kommentarer!
