Aktiveringsfunktioner
Svep för att visa menyn
Varför aktiveringsfunktioner är avgörande i CNN:er
Aktiveringsfunktioner introducerar icke-linjäritet i CNN:er, vilket gör det möjligt för dem att lära sig komplexa mönster utöver vad en enkel linjär modell kan uppnå. Utan aktiveringsfunktioner skulle CNN:er ha svårt att upptäcka invecklade samband i data, vilket begränsar deras effektivitet vid bildigenkänning och klassificering. Valet av rätt aktiveringsfunktion påverkar träningshastighet, stabilitet och den övergripande prestandan.
Vanliga aktiveringsfunktioner
- ReLU (rectified linear unit): den mest använda aktiveringsfunktionen i CNN:er. Den släpper endast igenom positiva värden och sätter alla negativa indata till noll, vilket gör den beräkningsmässigt effektiv och förhindrar försvinnande gradienter. Dock kan vissa neuroner bli inaktiva på grund av "dying ReLU"-problemet;

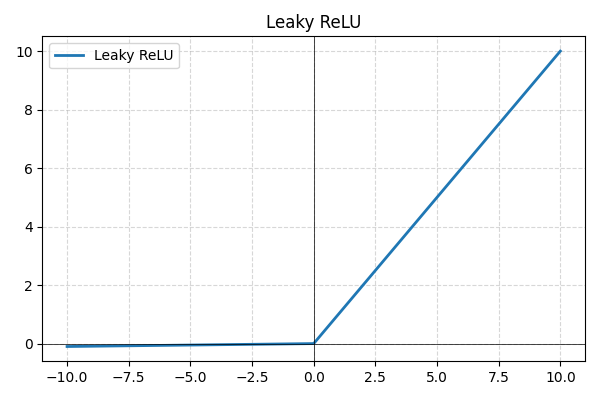
- Leaky ReLU: en variant av ReLU som tillåter små negativa värden istället för att sätta dem till noll, vilket förhindrar inaktiva neuroner och förbättrar gradientflödet;
- Sigmoid: komprimerar inmatningsvärden till ett intervall mellan 0 och 1, vilket gör den användbar för binär klassificering. Dock lider den av försvinnande gradienter i djupa nätverk;

- Tanh: liknar Sigmoid men ger värden mellan -1 och 1, vilket centrerar aktiveringar kring noll;

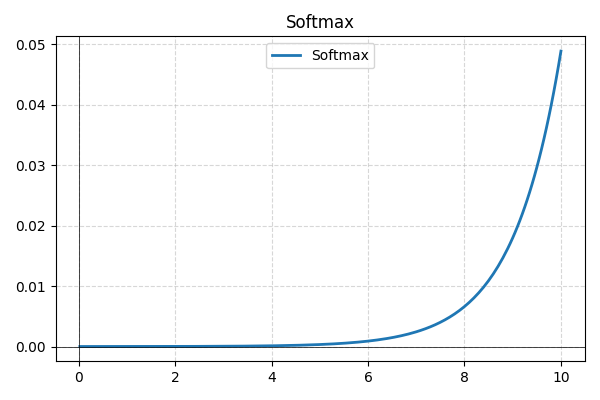
- Softmax: används vanligtvis i det sista lagret för flervalsklassificering. Softmax omvandlar nätverkets råa utdata till sannolikheter och säkerställer att de summeras till ett, vilket ger bättre tolkbarhet.
Att välja rätt aktiveringsfunktion
ReLU är standardvalet för dolda lager tack vare dess effektivitet och starka prestanda, medan Leaky ReLU är ett bättre alternativ när inaktiva neuroner blir ett problem. Sigmoid och Tanh undviks oftast i djupa CNN:er men kan fortfarande vara användbara i specifika tillämpningar. Softmax är avgörande för klassificering med flera klasser och säkerställer tydliga sannolikhetsbaserade förutsägelser.
Att välja rätt aktiveringsfunktion är avgörande för att optimera CNN-prestanda, balansera effektivitet och förebygga problem som försvinnande eller exploderande gradienter. Varje funktion bidrar på sitt unika sätt till hur ett nätverk bearbetar och lär sig från visuella data.
1. Varför föredras ReLU framför Sigmoid i djupa CNN:er?
2. Vilken aktiveringsfunktion används vanligtvis i det sista lagret av ett CNN för flervalsklassificering?
3. Vad är den främsta fördelen med Leaky ReLU jämfört med standard ReLU?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
Aktiveringsfunktioner
Varför aktiveringsfunktioner är avgörande i CNN:er
Aktiveringsfunktioner introducerar icke-linjäritet i CNN:er, vilket gör det möjligt för dem att lära sig komplexa mönster utöver vad en enkel linjär modell kan uppnå. Utan aktiveringsfunktioner skulle CNN:er ha svårt att upptäcka invecklade samband i data, vilket begränsar deras effektivitet vid bildigenkänning och klassificering. Valet av rätt aktiveringsfunktion påverkar träningshastighet, stabilitet och den övergripande prestandan.
Vanliga aktiveringsfunktioner
- ReLU (rectified linear unit): den mest använda aktiveringsfunktionen i CNN:er. Den släpper endast igenom positiva värden och sätter alla negativa indata till noll, vilket gör den beräkningsmässigt effektiv och förhindrar försvinnande gradienter. Dock kan vissa neuroner bli inaktiva på grund av "dying ReLU"-problemet;
- Leaky ReLU: en variant av ReLU som tillåter små negativa värden istället för att sätta dem till noll, vilket förhindrar inaktiva neuroner och förbättrar gradientflödet;
- Sigmoid: komprimerar inmatningsvärden till ett intervall mellan 0 och 1, vilket gör den användbar för binär klassificering. Dock lider den av försvinnande gradienter i djupa nätverk;
- Tanh: liknar Sigmoid men ger värden mellan -1 och 1, vilket centrerar aktiveringar kring noll;
- Softmax: används vanligtvis i det sista lagret för flervalsklassificering. Softmax omvandlar nätverkets råa utdata till sannolikheter och säkerställer att de summeras till ett, vilket ger bättre tolkbarhet.
Att välja rätt aktiveringsfunktion
ReLU är standardvalet för dolda lager tack vare dess effektivitet och starka prestanda, medan Leaky ReLU är ett bättre alternativ när inaktiva neuroner blir ett problem. Sigmoid och Tanh undviks oftast i djupa CNN:er men kan fortfarande vara användbara i specifika tillämpningar. Softmax är avgörande för klassificering med flera klasser och säkerställer tydliga sannolikhetsbaserade förutsägelser.
Att välja rätt aktiveringsfunktion är avgörande för att optimera CNN-prestanda, balansera effektivitet och förebygga problem som försvinnande eller exploderande gradienter. Varje funktion bidrar på sitt unika sätt till hur ett nätverk bearbetar och lär sig från visuella data.
Tack för dina kommentarer!
