Översikt av Bildgenerering
Svep för att visa menyn
AI-genererade bilder förändrar sättet människor skapar konst, design och digitalt innehåll. Med hjälp av artificiell intelligens kan datorer nu skapa realistiska bilder, förbättra kreativt arbete och till och med bistå företag. I detta kapitel utforskas hur AI skapar bilder, olika typer av bildgenereringsmodeller och deras användning i verkliga tillämpningar.
Hur AI skapar bilder
AI-bildgenerering fungerar genom att lära sig från en stor samling bilder. AI:n analyserar mönster i bilderna och skapar sedan nya som liknar dessa. Denna teknik har förbättrats mycket över åren och möjliggör nu mer realistiska och kreativa bilder. Den används idag inom datorspel, film, reklam och även mode.
Tidiga metoder: PixelRNN och PixelCNN
Innan dagens avancerade AI-modeller utvecklade forskare tidiga bildgenereringsmetoder som PixelRNN och PixelCNN. Dessa modeller skapade bilder genom att förutsäga en pixel i taget.
- PixelRNN: använder ett system som kallas rekurrenta neurala nätverk (RNN) för att förutsäga pixelns färg en efter en. Även om det fungerade bra var det mycket långsamt;
- PixelCNN: förbättrade PixelRNN genom att använda en annan typ av nätverk, så kallade konvolutionella lager, vilket gjorde bildskapandet snabbare.
Trots att dessa modeller var en bra början var de inte särskilt bra på att skapa högkvalitativa bilder. Detta ledde till utvecklingen av bättre tekniker.
Autoregressiva modeller
Autoregressiva modeller skapar också bilder en pixel i taget, genom att använda tidigare pixlar för att förutsäga vad som kommer härnäst. Dessa modeller var användbara men långsamma, vilket gjorde att de blev mindre populära med tiden. De bidrog dock till att inspirera nyare och snabbare modeller.
Hur AI förstår text för bildgenerering
Vissa AI-modeller kan omvandla skrivna ord till bilder. Dessa modeller använder Large Language Models (LLMs) för att förstå beskrivningar och generera matchande bilder. Till exempel, om du skriver “en katt som sitter på en strand vid solnedgången”, kommer AI:n att skapa en bild baserad på den beskrivningen.
AI-modeller som OpenAI:s DALL-E och Googles Imagen använder avancerad språkförståelse för att förbättra hur väl textbeskrivningar matchar de bilder de genererar. Detta möjliggörs genom Natural Language Processing (NLP), som hjälper AI att bryta ner ord till siffror som styr bildskapandet.
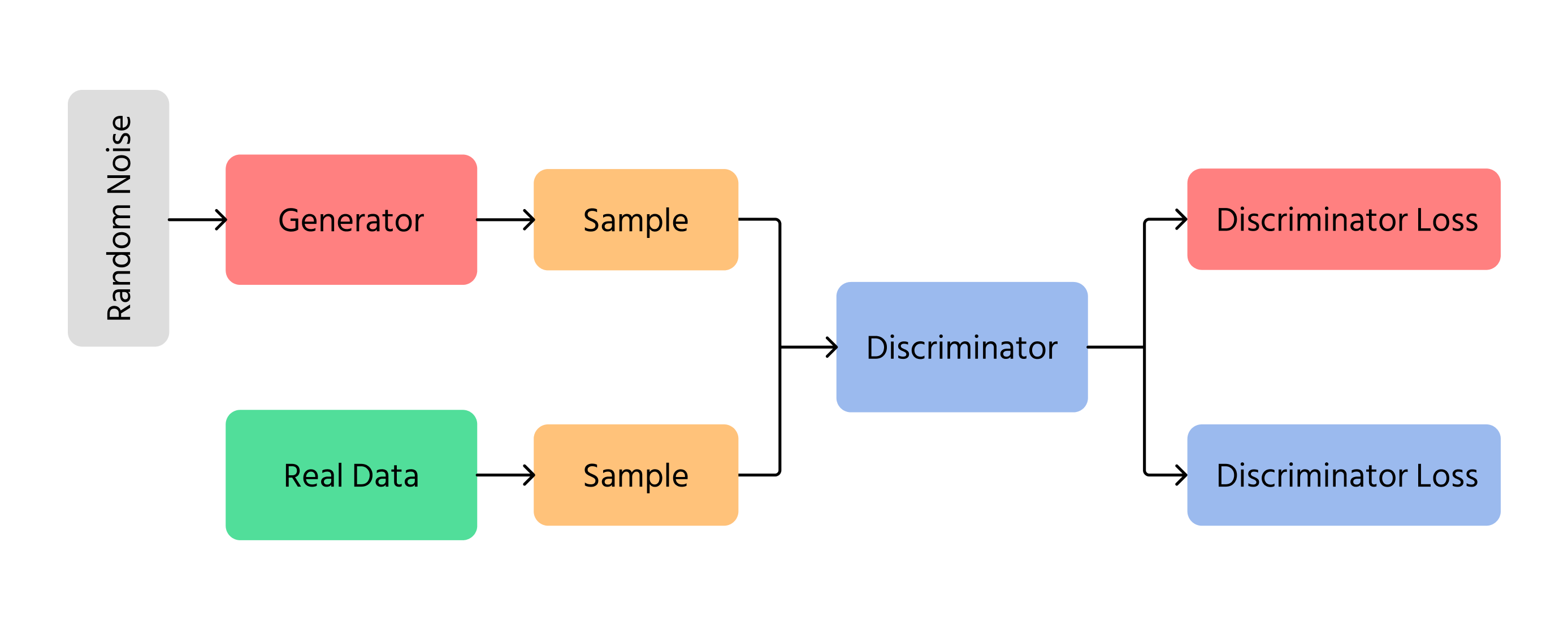
Generativa adversariella nätverk (GANs)
Ett av de viktigaste genombrotten inom AI-bildgenerering var Generativa adversariella nätverk (GANs). GANs fungerar genom att använda två olika neurala nätverk:
- Generator: skapar nya bilder från grunden;
- Discriminator: kontrollerar om bilderna ser verkliga eller falska ut.
Generatorn försöker skapa bilder som är så realistiska att diskriminatorn inte kan avgöra att de är falska. Med tiden förbättras bilderna och ser mer ut som riktiga fotografier. GANs används inom deepfake-teknik, konstskapande och förbättring av bildkvalitet.
Variationsautoenkodare (VAE)
VAE är ett annat sätt för AI att generera bilder. Istället för att använda tävling som GAN:er, kodar och avkodar VAE bilder med hjälp av sannolikhet. De fungerar genom att lära sig de underliggande mönstren i en bild och sedan återskapa den med små variationer. Det sannolikhetsbaserade inslaget i VAE säkerställer att varje genererad bild är något annorlunda, vilket ger variation och kreativitet.
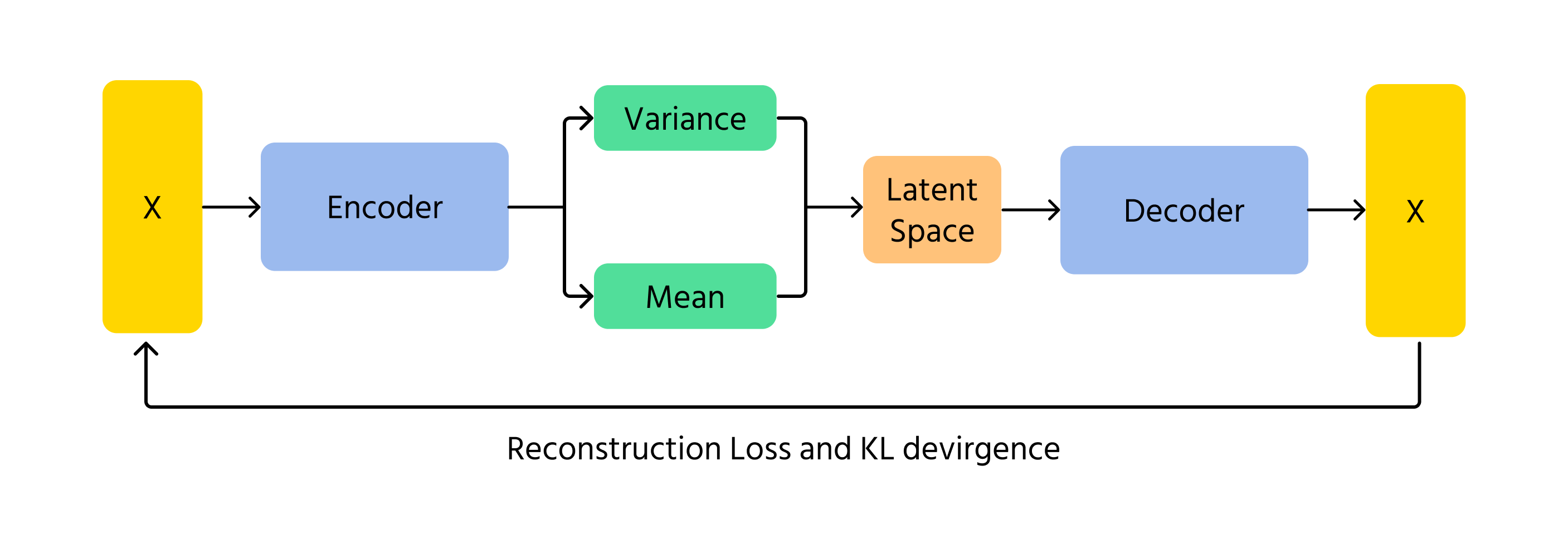
Ett centralt begrepp i VAE:er är Kullback-Leibler (KL) divergens, som mäter skillnaden mellan den inlärda fördelningen och en standard normalfördelning. Genom att minimera KL-divergensen säkerställer VAE:er att genererade bilder förblir realistiska samtidigt som kreativa variationer möjliggörs.
Hur VAE:er fungerar
- Kodning: indata x matas in i kodaren, som ger parametrarna för den latenta rumsfördelningen q(z∣x) (medelvärde μ och varians σ²);
- Sampling i latent rum: latenta variabler z samplas från fördelningen q(z∣x) med hjälp av tekniker som reparameteriseringstricket;
- Avkodning & rekonstruktion: den samplade z skickas genom avkodaren för att producera den rekonstruerade datan x̂, som bör vara lik originalindatan x.
VAE:er är användbara för uppgifter som att rekonstruera ansikten, generera nya versioner av befintliga bilder och skapa mjuka övergångar mellan olika bilder.
Diffusionsmodeller
Diffusionsmodeller är det senaste genombrottet inom AI-genererade bilder. Dessa modeller börjar med slumpmässigt brus och förbättrar gradvis bilden steg för steg, likt att sudda bort brus från ett suddigt foto. Till skillnad från GAN:er, som ibland skapar begränsade variationer, kan diffusionsmodeller producera ett bredare spektrum av högkvalitativa bilder.
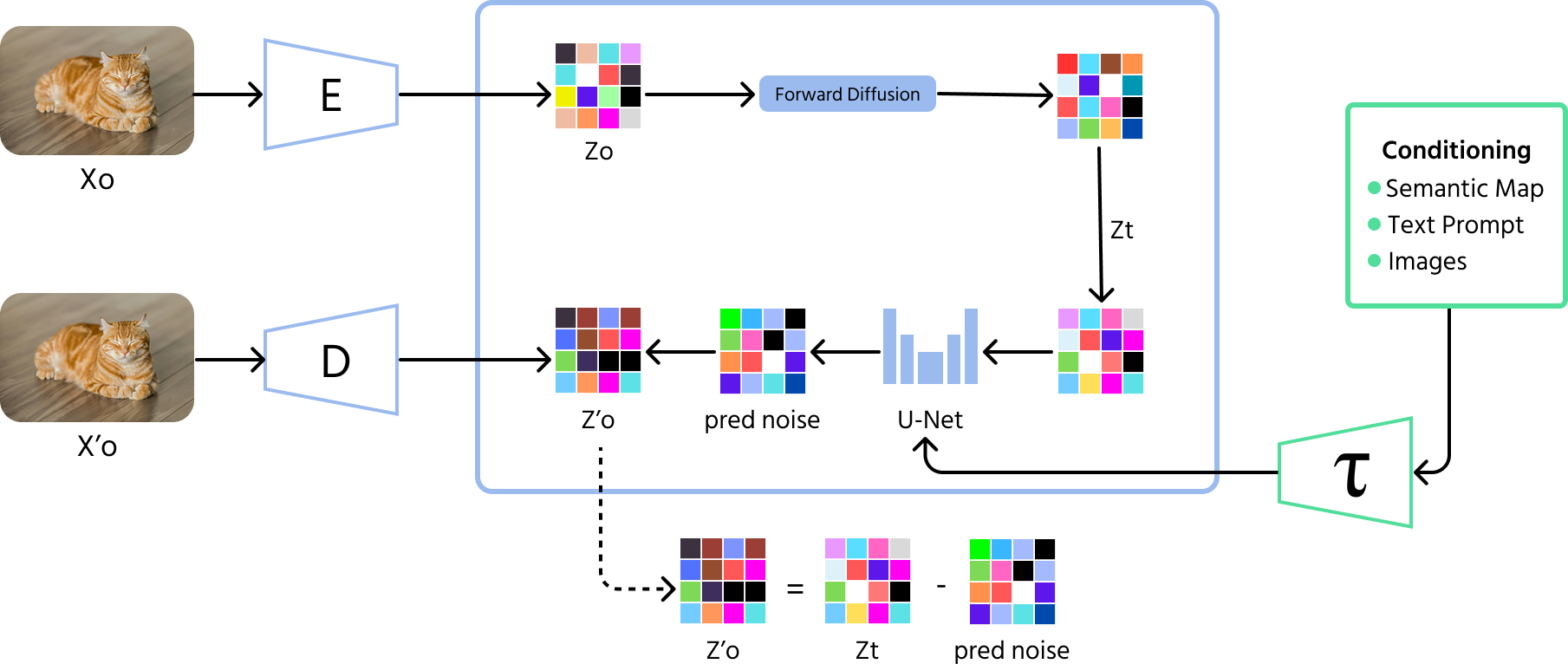
Hur diffusionsmodeller fungerar
- Framåtprocess (brusaddition): modellen börjar med att lägga till slumpmässigt brus till en bild under många steg tills den blir helt oigenkännlig;
- Omvänd process (brusreducering): modellen lär sig sedan att vända denna process, genom att gradvis ta bort bruset steg för steg för att återskapa en meningsfull bild;
- Träning: diffusionsmodeller tränas för att förutsäga och ta bort brus vid varje steg, vilket hjälper dem att generera tydliga och högkvalitativa bilder från slumpmässigt brus.
Ett populärt exempel är MidJourney, DALL-E och Stable Diffusion, som är kända för att skapa realistiska och konstnärliga bilder. Diffusionsmodeller används ofta för AI-genererad konst, högupplöst bildsyntes och kreativa designapplikationer.
Exempel på bilder genererade av diffusionsmodeller

Realistisk bild av en basketspelare med skägg i gul-lila uniform som gör en dunk och besegrar demoner i en basketmatch, all action utspelar sig i helvetet.

En surrealistisk vacker konstnärlig bild av en vit Volkswagen Golf GTI från 1990 på en oändlig äng av vita blommor i harmoni med naturen, mitt i oändliga kullar fulla av blommor, botanisk, naturligt ljus, konstnärlig, dimmig fotorealistisk surrealistisk ultradetaljerad, kodakfilm, naturligt ljus, vidvinkelobjektiv, f 1.20

Målning av beige pudelhund som ligger på grön soffa med grön- och vitrandig kudde i stil med Fairfield Porter, abstrakt expressionism, med djärva penseldrag på beige bakgrund

Extrem närbild av en medelhavs- eller latinamerikansk kvinnas hud, med fokus på en kombinerad hudtyp med synlig oljighet i pannan och på näsan, medan kinderna framstår som torrare och något flagiga. Porerna är mer framträdande i T-zonen, och det finns en naturlig glans som speglar talgproduktionen. Huden har en blandning av varma och gyllene undertoner, med ojämn textur på grund av olika fuktnivåer. Mjuk, naturlig belysning framhäver den realistiska kontrasten mellan de torra och oljiga områdena. Bakgrunden är suddig, vilket håller fokus på hennes hudton.
Utmaningar och etiska frågor
Även om AI-genererade bilder är imponerande, finns det utmaningar:
- Brist på kontroll: AI genererar inte alltid exakt det användaren önskar;
- Beräkningskraft: att skapa högkvalitativa AI-bilder kräver dyra och kraftfulla datorer;
- Bias i AI-modeller: eftersom AI lär sig från befintliga bilder kan den ibland upprepa fördomar som finns i datan.
Det finns också etiska frågor:
- Vem äger AI-konst?: om en AI skapar ett konstverk, är det personen som använde AI:n som äger det, eller tillhör det AI-företaget?
- Falska bilder och deepfakes: GAN:er kan användas för att skapa falska bilder som ser verkliga ut, vilket kan leda till desinformation och integritetsproblem.
Hur AI-bildgenerering används idag
AI-genererade bilder har redan stor påverkan inom olika branscher:
- Underhållning: datorspel, filmer och animation använder AI för att skapa bakgrunder, karaktärer och effekter;
- Mode: designers använder AI för att skapa nya klädstilar, och nätbutiker erbjuder virtuella provningar för kunder;
- Grafisk design: AI hjälper konstnärer och designers att snabbt skapa logotyper, affischer och marknadsföringsmaterial.
Framtiden för AI-bildgenerering
I takt med att AI-bildgenerering fortsätter att utvecklas, kommer det att förändra hur människor skapar och använder bilder. Inom konst, affärsliv eller underhållning öppnar AI nya möjligheter och gör kreativt arbete enklare och mer spännande.
1. Vad är huvudsyftet med AI-bildgenerering?
2. Hur fungerar Generative Adversarial Networks (GANs)?
3. Vilken AI-modell börjar med slumpmässigt brus och förbättrar bilden steg för steg?
Tack för dina kommentarer!
Fråga AI
Fråga AI

Fråga vad du vill eller prova någon av de föreslagna frågorna för att starta vårt samtal
Översikt av Bildgenerering
AI-genererade bilder förändrar sättet människor skapar konst, design och digitalt innehåll. Med hjälp av artificiell intelligens kan datorer nu skapa realistiska bilder, förbättra kreativt arbete och till och med bistå företag. I detta kapitel utforskas hur AI skapar bilder, olika typer av bildgenereringsmodeller och deras användning i verkliga tillämpningar.
Hur AI skapar bilder
AI-bildgenerering fungerar genom att lära sig från en stor samling bilder. AI:n analyserar mönster i bilderna och skapar sedan nya som liknar dessa. Denna teknik har förbättrats mycket över åren och möjliggör nu mer realistiska och kreativa bilder. Den används idag inom datorspel, film, reklam och även mode.
Tidiga metoder: PixelRNN och PixelCNN
Innan dagens avancerade AI-modeller utvecklade forskare tidiga bildgenereringsmetoder som PixelRNN och PixelCNN. Dessa modeller skapade bilder genom att förutsäga en pixel i taget.
- PixelRNN: använder ett system som kallas rekurrenta neurala nätverk (RNN) för att förutsäga pixelns färg en efter en. Även om det fungerade bra var det mycket långsamt;
- PixelCNN: förbättrade PixelRNN genom att använda en annan typ av nätverk, så kallade konvolutionella lager, vilket gjorde bildskapandet snabbare.
Trots att dessa modeller var en bra början var de inte särskilt bra på att skapa högkvalitativa bilder. Detta ledde till utvecklingen av bättre tekniker.
Autoregressiva modeller
Autoregressiva modeller skapar också bilder en pixel i taget, genom att använda tidigare pixlar för att förutsäga vad som kommer härnäst. Dessa modeller var användbara men långsamma, vilket gjorde att de blev mindre populära med tiden. De bidrog dock till att inspirera nyare och snabbare modeller.
Hur AI förstår text för bildgenerering
Vissa AI-modeller kan omvandla skrivna ord till bilder. Dessa modeller använder Large Language Models (LLMs) för att förstå beskrivningar och generera matchande bilder. Till exempel, om du skriver “en katt som sitter på en strand vid solnedgången”, kommer AI:n att skapa en bild baserad på den beskrivningen.
AI-modeller som OpenAI:s DALL-E och Googles Imagen använder avancerad språkförståelse för att förbättra hur väl textbeskrivningar matchar de bilder de genererar. Detta möjliggörs genom Natural Language Processing (NLP), som hjälper AI att bryta ner ord till siffror som styr bildskapandet.
Generativa adversariella nätverk (GANs)
Ett av de viktigaste genombrotten inom AI-bildgenerering var Generativa adversariella nätverk (GANs). GANs fungerar genom att använda två olika neurala nätverk:
- Generator: skapar nya bilder från grunden;
- Discriminator: kontrollerar om bilderna ser verkliga eller falska ut.
Generatorn försöker skapa bilder som är så realistiska att diskriminatorn inte kan avgöra att de är falska. Med tiden förbättras bilderna och ser mer ut som riktiga fotografier. GANs används inom deepfake-teknik, konstskapande och förbättring av bildkvalitet.
Variationsautoenkodare (VAE)
VAE är ett annat sätt för AI att generera bilder. Istället för att använda tävling som GAN:er, kodar och avkodar VAE bilder med hjälp av sannolikhet. De fungerar genom att lära sig de underliggande mönstren i en bild och sedan återskapa den med små variationer. Det sannolikhetsbaserade inslaget i VAE säkerställer att varje genererad bild är något annorlunda, vilket ger variation och kreativitet.
Ett centralt begrepp i VAE:er är Kullback-Leibler (KL) divergens, som mäter skillnaden mellan den inlärda fördelningen och en standard normalfördelning. Genom att minimera KL-divergensen säkerställer VAE:er att genererade bilder förblir realistiska samtidigt som kreativa variationer möjliggörs.
Hur VAE:er fungerar
- Kodning: indata x matas in i kodaren, som ger parametrarna för den latenta rumsfördelningen q(z∣x) (medelvärde μ och varians σ²);
- Sampling i latent rum: latenta variabler z samplas från fördelningen q(z∣x) med hjälp av tekniker som reparameteriseringstricket;
- Avkodning & rekonstruktion: den samplade z skickas genom avkodaren för att producera den rekonstruerade datan x̂, som bör vara lik originalindatan x.
VAE:er är användbara för uppgifter som att rekonstruera ansikten, generera nya versioner av befintliga bilder och skapa mjuka övergångar mellan olika bilder.
Diffusionsmodeller
Diffusionsmodeller är det senaste genombrottet inom AI-genererade bilder. Dessa modeller börjar med slumpmässigt brus och förbättrar gradvis bilden steg för steg, likt att sudda bort brus från ett suddigt foto. Till skillnad från GAN:er, som ibland skapar begränsade variationer, kan diffusionsmodeller producera ett bredare spektrum av högkvalitativa bilder.
Hur diffusionsmodeller fungerar
- Framåtprocess (brusaddition): modellen börjar med att lägga till slumpmässigt brus till en bild under många steg tills den blir helt oigenkännlig;
- Omvänd process (brusreducering): modellen lär sig sedan att vända denna process, genom att gradvis ta bort bruset steg för steg för att återskapa en meningsfull bild;
- Träning: diffusionsmodeller tränas för att förutsäga och ta bort brus vid varje steg, vilket hjälper dem att generera tydliga och högkvalitativa bilder från slumpmässigt brus.
Ett populärt exempel är MidJourney, DALL-E och Stable Diffusion, som är kända för att skapa realistiska och konstnärliga bilder. Diffusionsmodeller används ofta för AI-genererad konst, högupplöst bildsyntes och kreativa designapplikationer.
Exempel på bilder genererade av diffusionsmodeller
Realistisk bild av en basketspelare med skägg i gul-lila uniform som gör en dunk och besegrar demoner i en basketmatch, all action utspelar sig i helvetet.
En surrealistisk vacker konstnärlig bild av en vit Volkswagen Golf GTI från 1990 på en oändlig äng av vita blommor i harmoni med naturen, mitt i oändliga kullar fulla av blommor, botanisk, naturligt ljus, konstnärlig, dimmig fotorealistisk surrealistisk ultradetaljerad, kodakfilm, naturligt ljus, vidvinkelobjektiv, f 1.20
Målning av beige pudelhund som ligger på grön soffa med grön- och vitrandig kudde i stil med Fairfield Porter, abstrakt expressionism, med djärva penseldrag på beige bakgrund
Extrem närbild av en medelhavs- eller latinamerikansk kvinnas hud, med fokus på en kombinerad hudtyp med synlig oljighet i pannan och på näsan, medan kinderna framstår som torrare och något flagiga. Porerna är mer framträdande i T-zonen, och det finns en naturlig glans som speglar talgproduktionen. Huden har en blandning av varma och gyllene undertoner, med ojämn textur på grund av olika fuktnivåer. Mjuk, naturlig belysning framhäver den realistiska kontrasten mellan de torra och oljiga områdena. Bakgrunden är suddig, vilket håller fokus på hennes hudton.
Utmaningar och etiska frågor
Även om AI-genererade bilder är imponerande, finns det utmaningar:
- Brist på kontroll: AI genererar inte alltid exakt det användaren önskar;
- Beräkningskraft: att skapa högkvalitativa AI-bilder kräver dyra och kraftfulla datorer;
- Bias i AI-modeller: eftersom AI lär sig från befintliga bilder kan den ibland upprepa fördomar som finns i datan.
Det finns också etiska frågor:
- Vem äger AI-konst?: om en AI skapar ett konstverk, är det personen som använde AI:n som äger det, eller tillhör det AI-företaget?
- Falska bilder och deepfakes: GAN:er kan användas för att skapa falska bilder som ser verkliga ut, vilket kan leda till desinformation och integritetsproblem.
Hur AI-bildgenerering används idag
AI-genererade bilder har redan stor påverkan inom olika branscher:
- Underhållning: datorspel, filmer och animation använder AI för att skapa bakgrunder, karaktärer och effekter;
- Mode: designers använder AI för att skapa nya klädstilar, och nätbutiker erbjuder virtuella provningar för kunder;
- Grafisk design: AI hjälper konstnärer och designers att snabbt skapa logotyper, affischer och marknadsföringsmaterial.
Framtiden för AI-bildgenerering
I takt med att AI-bildgenerering fortsätter att utvecklas, kommer det att förändra hur människor skapar och använder bilder. Inom konst, affärsliv eller underhållning öppnar AI nya möjligheter och gör kreativt arbete enklare och mer spännande.
Tack för dina kommentarer!
